* [功能](#功能)
* [输出](#输出)
* [实例](#实例)
* [运行环境](#运行环境)
* [使用说明](#使用说明)
* [下载脚本](#1下载脚本)
* [安装依赖](#2安装依赖)
* [程序设置](#3程序设置)
* [设置数据库(可选)](#4设置数据库可选)
* [运行脚本](#5运行脚本)
* [按需求修改脚本(可选)](#6按需求修改脚本可选)
* [定期自动爬取微博(可选)](#7定期自动爬取微博可选)
* [如何获取user_id](#如何获取user_id)
* [添加cookie与不添加cookie的区别(可选)](#添加cookie与不添加cookie的区别可选)
* [如何获取cookie(可选)](#如何获取cookie可选)
* [如何检测cookie是否有效(可选)](#如何检测cookie是否有效可选)
## 功能
连续爬取**一个**或**多个**新浪微博用户(如[Dear-迪丽热巴](https://weibo.cn/u/1669879400)、[郭碧婷](https://weibo.cn/u/1729370543))的数据,并将结果信息写入文件。写入信息几乎包括了用户微博的所有数据,主要有**用户信息**和**微博信息**两大类,前者包含用户昵称、关注数、粉丝数、微博数等等;后者包含微博正文、发布时间、发布工具、评论数等等,因为内容太多,这里不再赘述,详细内容见[输出](#输出)部分。具体的写入文件类型如下:
- 写入**csv文件**(默认)
- 写入**json文件**(可选)
- 写入**MySQL数据库**(可选)
- 写入**MongoDB数据库**(可选)
- 下载用户**原创**微博中的原始**图片**(可选)
- 下载用户**转发**微博中的原始**图片**(可选)
- 下载用户**原创**微博中的**视频**(可选)
- 下载用户**转发**微博中的**视频**(可选)
- 下载用户**原创**微博**Live Photo**中的**视频**(可选)
- 下载用户**转发**微博**Live Photo**中的**视频**(可选)<br>
如果你只对用户信息感兴趣,而不需要爬用户的微博,也可以通过设置实现只爬取微博用户信息的功能。程序也可以实现**爬取结果自动更新**,即:现在爬取了目标用户的微博,几天之后,目标用户可能又发新微博了。通过设置,可以实现每隔几天**增量爬取**用户这几天发的新微博。具体方法见[定期自动爬取微博](#7定期自动爬取微博可选)。<br>
## 输出
**用户信息**<br>
- 用户id:微博用户id,如"1669879400"
- 用户昵称:微博用户昵称,如"Dear-迪丽热巴"
- 性别:微博用户性别
- 生日:用户出生日期
- 所在地:用户所在地
- 教育经历:用户上学时学校的名字
- 公司:用户所属公司名字
- 阳光信用:用户的阳光信用
- 微博注册时间:用户微博注册日期
- 微博数:用户的全部微博数(转发微博+原创微博)
- 粉丝数:用户的粉丝数
- 关注数:用户关注的微博数量
- 简介:用户简介
- 主页地址:微博移动版主页url,如<https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400>
- 头像url:用户头像url
- 高清头像url:用户高清头像url
- 微博等级:用户微博等级
- 会员等级:微博会员用户等级,普通用户该等级为0
- 是否认证:用户是否认证,为布尔类型
- 认证类型:用户认证类型,如个人认证、企业认证、政府认证等
- 认证信息:为认证用户特有,用户信息栏显示的认证信息
***
**微博信息**<br>
- 微博id:微博的id,为一串数字形式
- 微博bid:微博的bid,与[cookie版](https://github.com/dataabc/weiboSpider)中的微博id是同一个值
- 微博内容:微博正文
- 头条文章url:微博中头条文章的url,如果微博中存在头条文章,就获取该头条文章的url,否则该值为''
- 原始图片url:原创微博图片和转发微博转发理由中图片的url,若某条微博存在多张图片,则每个url以英文逗号分隔,若没有图片则值为''
- 视频url: 微博中的视频url和Live Photo中的视频url,若某条微博存在多个视频,则每个url以英文分号分隔,若没有视频则值为''
- 微博发布位置:位置微博中的发布位置
- 微博发布时间:微博发布时的时间,精确到天
- 点赞数:微博被赞的数量
- 转发数:微博被转发的数量
- 评论数:微博被评论的数量
- 微博发布工具:微博的发布工具,如iPhone客户端、HUAWEI Mate 20 Pro等,若没有则值为''
- 话题:微博话题,即两个#中的内容,若存在多个话题,每个url以英文逗号分隔,若没有则值为''
- @用户:微博@的用户,若存在多个@用户,每个url以英文逗号分隔,若没有则值为''
- 原始微博:为转发微博所特有,是转发微博中那条被转发的微博,存储为字典形式,包含了上述微博信息中的所有内容,如微博id、微博内容等等
- 结果文件:保存在当前目录weibo文件夹下以用户昵称为名的文件夹里,名字为"user_id.csv"形式
- 微博图片:微博中的图片,保存在以用户昵称为名的文件夹下的img文件夹里
- 微博视频:微博中的视频,保存在以用户昵称为名的文件夹下的video文件夹里
## 实例
以爬取迪丽热巴的微博为例,我们需要修改**config.json**文件,文件内容如下:
```
{
"user_id_list": ["1669879400"],
"filter": 1,
"since_date": "1900-01-01",
"query_list": [],
"write_mode": ["csv"],
"original_pic_download": 1,
"retweet_pic_download": 0,
"original_video_download": 1,
"retweet_video_download": 0,
"cookie": "your cookie"
}
```
对于上述参数的含义以及取值范围,这里仅作简单介绍,详细信息见[程序设置](#3程序设置)。
>**user_id_list**代表我们要爬取的微博用户的user_id,可以是一个或多个,也可以是文件路径,微博用户Dear-迪丽热巴的user_id为1669879400,具体如何获取user_id见[如何获取user_id](#如何获取user_id);<br>**filter**的值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发);<br>**since_date**代表我们要爬取since_date日期之后发布的微博,因为我要爬迪丽热巴的全部原创微博,所以since_date设置了一个非常早的值;<br>query_list代表要爬取的微博关键词,为空([])则爬取全部;<br>**write_mode**代表结果文件的保存类型,我想要把结果写入csv文件和json文件,所以它的值为["csv", "json"],如果你想写入数据库,具体设置见[设置数据库](#4设置数据库可选);<br>**original_pic_download**值为1代表下载原创微博中的图片,值为0代表不下载;<br>**retweet_pic_download**值为1代表下载转发微博中的图片,值为0代表不下载;<br>**original_video_download**值为1代表下载原创微博中的视频,值为0代表不下载;<br>**retweet_video_download**值为1代表下载转发微博中的视频,值为0代表不下载;<br>**cookie**是可选参数,可填可不填,具体区别见[添加cookie与不添加cookie的区别](#添加cookie与不添加cookie的区别可选)。
配置完成后运行程序:
```bash
$ python weibo.py
```
程序会自动生成一个weibo文件夹,我们以后爬取的所有微博都被存储在weibo文件夹里。然后程序在该文件夹下生成一个名为"Dear-迪丽热巴"的文件夹,迪丽热巴的所有微博爬取结果都在这里。"Dear-迪丽热巴"文件夹里包含一个csv文件、一个img文件夹和一个video文件夹,img文件夹用来存储下载到的图片,video文件夹用来存储下载到的视频。如果你设置了保存数据库功能,这些信息也会保存在数据库里,数据库设置见[设置数据库](#4设置数据库可选)部分。<br>
**csv文件结果如下所示:**
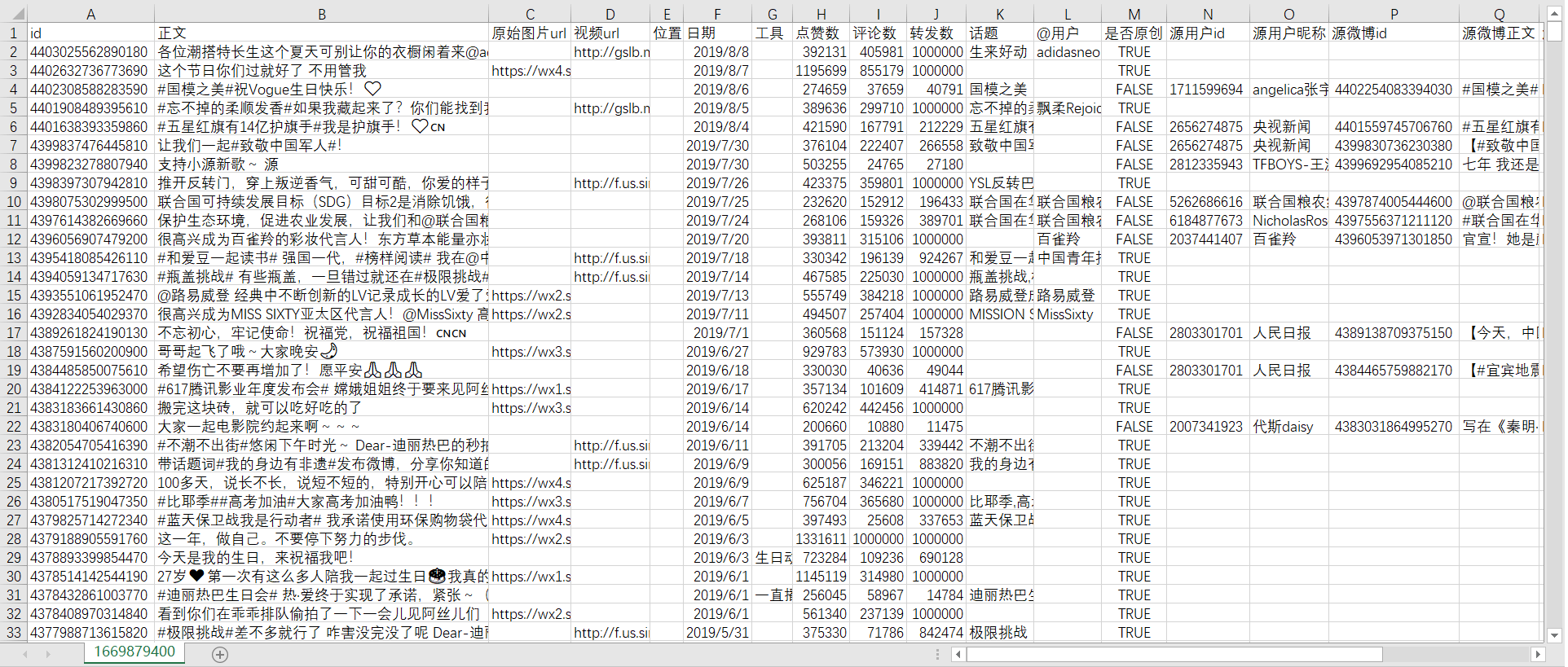*1669879
基于Python+Flask的基金查询工具源码+部署文档+全部数据资料 高分项目.zip

版权申诉
171 浏览量
2024-05-13
16:26:57
上传
评论
收藏 24.65MB ZIP 举报
 基于Python+Flask的基金查询工具源码+部署文档+全部数据资料 高分项目.zip (68个子文件)
基于Python+Flask的基金查询工具源码+部署文档+全部数据资料 高分项目.zip (68个子文件)  fund-main
fund-main  miner_pool.py 481B fund_base.py 2KB file new.csv 23B code_list.json 906B update_code_list.py 578B test.csv 60B xxhg.py 4KB .github workflows main.yml 1KB update_over_json.py 2KB btc.py 895B bing.py 561B stock.py 315B templates
miner_pool.py 481B fund_base.py 2KB file new.csv 23B code_list.json 906B update_code_list.py 578B test.csv 60B xxhg.py 4KB .github workflows main.yml 1KB update_over_json.py 2KB btc.py 895B bing.py 561B stock.py 315B templates  xalpha_all.html 895B index_mobile.html 2KB wb_article.html 892B xalpha_cccb.html 535B weibo_all.html 3KB index.html 4KB xxhg_pic.html 319B haoym_detail.html 522B haoym_index.html 684B weibo.html 2KB average_growth.py 2KB Readme 898B CodeListApi.py 3KB api.py 867B start.sh 46B driver chromedriver 11.03MB
xalpha_all.html 895B index_mobile.html 2KB wb_article.html 892B xalpha_cccb.html 535B weibo_all.html 3KB index.html 4KB xxhg_pic.html 319B haoym_detail.html 522B haoym_index.html 684B weibo.html 2KB average_growth.py 2KB Readme 898B CodeListApi.py 3KB api.py 867B start.sh 46B driver chromedriver 11.03MB chromedriver.exe 10.79MB mogen.py 1KB run.py 8KB common.py 6KB fund_howbuy.py 4KB
chromedriver.exe 10.79MB mogen.py 1KB run.py 8KB common.py 6KB fund_howbuy.py 4KB requirements.txt 199B getstring.py 2KB decorate.py 404B spider_wb_article.py 2KB editcsv.py 807B UpdateEveryMoney.py 1KB .gitignore 58B weibo __init__.py 0B logging.conf 1017B weibo.py 51KB requirements.txt 42B config.json 454B README.md 43KB static require.js 84KB btc.js 238B mail.js 66B msyh.ttf 20.76MB input.css 911B
requirements.txt 199B getstring.py 2KB decorate.py 404B spider_wb_article.py 2KB editcsv.py 807B UpdateEveryMoney.py 1KB .gitignore 58B weibo __init__.py 0B logging.conf 1017B weibo.py 51KB requirements.txt 42B config.json 454B README.md 43KB static require.js 84KB btc.js 238B mail.js 66B msyh.ttf 20.76MB input.css 911B web.png 100KB weibolist.css 2KB color.js 1KB time.js 581B moment.min.js 33KB table.css 523B jquery.min.js 87KB wb_article.css 376B xxhg.png 73KB banner.css 540B title.ico 1KB codelist.js 3KB README.md 1KB choose_api.py 1KB nasdaq.py 819B Flask系统部署文档.md 3KB
web.png 100KB weibolist.css 2KB color.js 1KB time.js 581B moment.min.js 33KB table.css 523B jquery.min.js 87KB wb_article.css 376B xxhg.png 73KB banner.css 540B title.ico 1KB codelist.js 3KB README.md 1KB choose_api.py 1KB nasdaq.py 819B Flask系统部署文档.md 3KB 171265889347208773632.zip 416B
171265889347208773632.zip 416B资源评论


不走小道
- 粉丝: 3225
- 资源: 5113









最新资源
- 《计算机网络-自顶向下方法》答案
- 基于pyqt5框架开发的demo项目 全栈开发,短小精悍,入门学习,上手简单
- 国内IP地址大全 站长资源 访问IP设置 Order allow,deny 使用方法
- 【JavaScript实现点击鼠标出现爱心特效脚本】直接引入index.html文件可用!!!
- OPC Core Components Redistributable (x86).msi
- 一套基于Python的交易量化框架,详细复现步骤
- 顺序表定义及12个基本操作实现
- xilinx vbyone IP 网表文件
- 【JavaScript实现点击鼠标出现爱心特效脚本】直接引入index.html文件可用!!!
- Erlang环境,26.1.0.0和Erlang环境,26.1.0.0
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


