
## NovelSpider
---
### 任务
* 完成网络爬虫系统设计,系统应包括:抓取网页、分析网页、判断相关度、保存网页信息、数据库设计和存储、多线程设计等。
### 要求
* 设计基于多线程的网络爬虫。
* 通过http将待爬取URL列表对应的URL网页代码提取出来。
* 提取所有需要的信息并且通过算法判断网页是否和设定的主题相关。
* 广度优化搜索,从网页中某个链接发出,访问该链接网页上的所有链接,访问完成后,再通过递归算法实现下一层的访问,重复以上步骤。
### 环境
> Django 2.2
### 展示
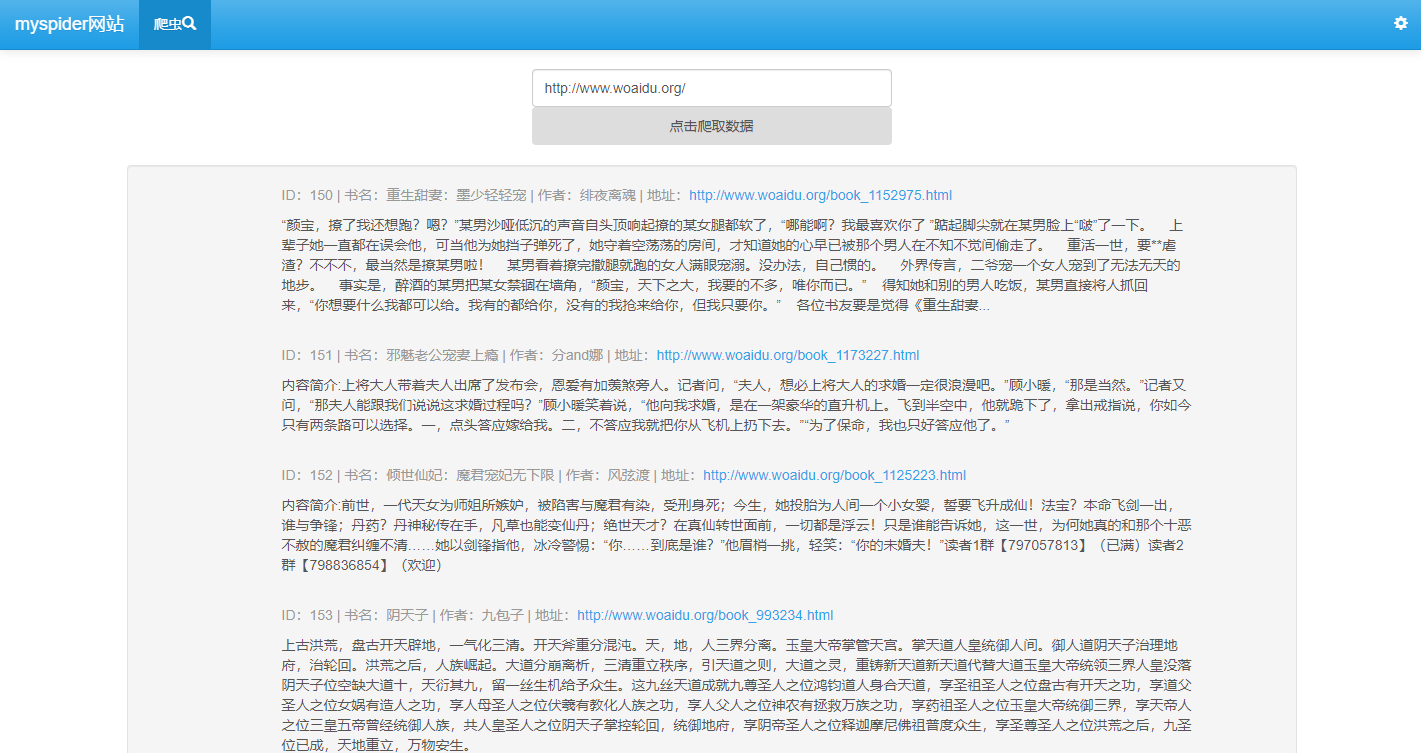
### 实现
```
class MyCrawler():
def __init__(self, seeds):
self.current_deepth = 1
# 初始化book列表
self.books = []
# 使用种子初始化url队列
self.linkQuence = linkQuence()
# 加锁,保护数据
self.lock = Lock()
# 线程池
self.url_queue = queue.Queue()
if isinstance(seeds, str):
self.linkQuence.addUnvisitedUrl(seeds)
if isinstance(seeds, list):
for i in seeds:
self.linkQuence.addUnvisitedUrl(i)
print("Add the seeds url \"%s\" to the unvisited url list" % str(self.linkQuence.unVisited))
# 抓取过程主函数
def crawling(self, seeds, crawl_count):
# 广度搜索
# 循环条件:待抓取的链接不空且专区的网页不多于crawl_count
while self.linkQuence.unVisitedUrlsEnmpy() is False and self.current_deepth <= crawl_count:
# 队头url出队列
visitUrl = self.linkQuence.unVisitedUrlDeQuence()
print("队头url出队列: \"%s\"" % visitUrl)
if visitUrl is None or visitUrl == "":
continue
# 获取超链接
links = self.getHyperLinks(visitUrl)
# 获取链接为空则跳过
if links is None:
continue
print("获取新链接个数: %d" % len(links))
# 将url放入已访问的url中
self.linkQuence.addVisitedUrl(visitUrl)
print("已访问网站数: " + str(self.linkQuence.getVisitedUrlCount()))
# 未访问的url入列
for link in links:
self.linkQuence.addUnvisitedUrl(link)
print("未访问的网站数: %d" % len(self.linkQuence.getUnvisitedUrl()))
self.current_deepth += 1
print("总的book数: %d" % self.books.__len__())
# 多线程采集book
for book in self.books:
self.url_queue.put(book)
spider_list = []
for i in range(20):
try:
t1 = Thread(target=self.getPageData, args=())
t1.start()
spider_list.append(t1)
except:
i += 1
for spider in spider_list:
spider.join()
# 获取源码中得超链接
def getHyperLinks(self, url, ua_agent='Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'):
try:
print('1这里执行了..')
links = []
# 随机休眠一定时间
time.sleep(random.random() * 2)
# request头部信息
header = {'User-Agent': ua_agent}
print('2这里执行了..')
# 获取源码
html = requests.get(url, timeout=30, headers=header, verify=False)
html.encoding = 'utf-8'
urls = re.findall(r'href="(.*?)"', html.text)
print('3这里执行了..')
for ur in urls:
# print('3这里执行了..')
# print('+'*50,ur)
# 如果以【/book_】开头则是想要的book网址
if ur.startswith('/book_'):
bookUrl = 'http://www.woaidu.org' + ur
# 查重,book列表如果已经存在该链接则不再添加
if self.books.__contains__(bookUrl):
continue
# 添加到book列表
self.books.insert(0, bookUrl)
# 相关性判断,判断是否和所设定的网址有关系
elif (ur.endswith('.html') and '/book_' not in ur) or 'www.woaidu.org/' in ur:
# print('>'*50,ur)
if not ur.startswith('http'):
ur2 = url + ur
else:
ur2 = ur
# 添加相关的网址链接
links.append(ur2)
print('4这里执行了..')
return links
except Exception as e:
print('没有获得超链接...')
return None
def getPageData(self, ua_agent='Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'):
while not self.url_queue.empty():
url_data = self.url_queue.get()
# print(url_data)
header = {'User-Agent': ua_agent}
html = requests.get(url_data, verify=False, headers=header)
html.encoding = 'utf-8'
with self.lock:
if html.status_code == 200:
# 通过正则表达式,抓取跟主题相关的内容
# print(html.text)
nam = re.findall(r'<title>(.*?) txt电子书下载 - 我爱读电子书 - 我爱读', html.text)
author = re.findall(r'作者:(.*?)\n', html.text)
# summay = re.findall(r'(.*?)</p>', html.text, re.S)
summay = re.findall(r'<p class="listcolor descrition" style="padding: 10px;">(.*?)</p>', html.text,
re.S)
# 查重,根据book的url判断是否已经在数据库当中
if Book.objects.filter(url=url_data).exists():
print("数据库已经存在该书:" + url_data)
else:
print('往Book表中存取的数据:', nam[0].strip(), author[0].strip(), url_data, summay[0].strip())
book = Book.objects.create(name=nam[0].strip(), author=author[0].strip(), url=url_data,
brief=summay[0].strip())
# 获取刚插入的book_id
book_id = book.pk
print('book_id:', book_id)
book.save()
# 获取下载地址
down_urls = re.findall(r'<a rel="nofollow" href=(.*) target="_blank">点击下载</a>', html.text)
# 获取更新时间
print('down_urls', down_urls)
up_times = re.findall(r'div class="ziziziz">(\d+-\d+-\d+)</div', html.text)
print('up_times', up_times)
new_sources = []
# 获取来源
for old_url in down_urls:
# 获取第一个参数
one_info = re.findall(r'_([^_]+)', old_url)[0]
# 获取第二个参数
twq_info = re.findall(r'_([^_]+)', old_url)[1].split()[0][:-1]
sources = re.findall(
r'a rel="nofollow" href="https://txt.woaidu.org/bookdownload_bookid_{}_snatchid_{}.html" target="_blank">(.*?)</a>'.format(
one_info, twq_info), html.text)[0]
new_sources.append(sources)
for source, up_time, down_url in zip(new_sources, up_times, down_urls):
 Python毕业设计 基于Django采用广度优先遍历搜索实现的小说爬取和展示系统的设计与实现+详细文档+全部资料.zip (51个子文件)
Python毕业设计 基于Django采用广度优先遍历搜索实现的小说爬取和展示系统的设计与实现+详细文档+全部资料.zip (51个子文件)  novel-spider-master spider
novel-spider-master spider  __init__.py 0B wsgi.py 389B urls.py 800B settings.py 3KB __pycache__ urls.cpython-36.pyc 963B settings.cpython-36.pyc 2KB settings.cpython-37.pyc 2KB __init__.cpython-37.pyc 132B __init__.cpython-36.pyc 124B wsgi.cpython-37.pyc 533B urls.cpython-37.pyc 970B wsgi.cpython-36.pyc 538B templates
__init__.py 0B wsgi.py 389B urls.py 800B settings.py 3KB __pycache__ urls.cpython-36.pyc 963B settings.cpython-36.pyc 2KB settings.cpython-37.pyc 2KB __init__.cpython-37.pyc 132B __init__.cpython-36.pyc 124B wsgi.cpython-37.pyc 533B urls.cpython-37.pyc 970B wsgi.cpython-36.pyc 538B templates  index.html 4KB manage.py 626B woaidu __init__.py 0B tests.py 10KB admin.py 372B migrations __init__.py 0B 0001_initial.py 1KB __pycache__ 0001_initial.cpython-36.pyc 875B __init__.cpython-36.pyc 148B apps.py 87B models.py 611B urls.py 186B __pycache__ urls.cpython-36.pyc 336B admin.cpython-36.pyc 702B views.cpython-36.pyc 7KB views.cpython-37.pyc 333B __init__.cpython-37.pyc 132B __init__.cpython-36.pyc 137B models.cpython-36.pyc 1006B static js pager.js 277B bootstrap.min.js 36KB search.js 1KB bootstrap-switch.min.js 15KB continuously.js 1KB topcontrol.js 1KB config.js 7KB booktool.js 2KB jquery.min.js 84KB css custom_theme.css 181B bootstrap.min.css 127KB bootstrap-switch.min.css 6KB fonts
index.html 4KB manage.py 626B woaidu __init__.py 0B tests.py 10KB admin.py 372B migrations __init__.py 0B 0001_initial.py 1KB __pycache__ 0001_initial.cpython-36.pyc 875B __init__.cpython-36.pyc 148B apps.py 87B models.py 611B urls.py 186B __pycache__ urls.cpython-36.pyc 336B admin.cpython-36.pyc 702B views.cpython-36.pyc 7KB views.cpython-37.pyc 333B __init__.cpython-37.pyc 132B __init__.cpython-36.pyc 137B models.cpython-36.pyc 1006B static js pager.js 277B bootstrap.min.js 36KB search.js 1KB bootstrap-switch.min.js 15KB continuously.js 1KB topcontrol.js 1KB config.js 7KB booktool.js 2KB jquery.min.js 84KB css custom_theme.css 181B bootstrap.min.css 127KB bootstrap-switch.min.css 6KB fonts  glyphicons-halflings-regular.svg 106KB glyphicons-halflings-regular.ttf 44KB glyphicons-halflings-regular.woff 23KB glyphicons-halflings-regular.eot 20KB glyphicons-halflings-regular.woff2 18KB views.py 10KB README.md 9KB
glyphicons-halflings-regular.svg 106KB glyphicons-halflings-regular.ttf 44KB glyphicons-halflings-regular.woff 23KB glyphicons-halflings-regular.eot 20KB glyphicons-halflings-regular.woff2 18KB views.py 10KB README.md 9KB 171265889347208773632.zip 416B
171265889347208773632.zip 416B资源评论


不走小道
- 粉丝: 3389
- 资源: 5050









最新资源
- 基于观测器的线性多智能体系统事件触发一致性控制策略研究,基于观测器的事件触发线性多智能体一致性策略研究与应用实践,04基于观测器的线性多智能体事件触发一致性 ,基于观测器; 线性多智能体; 事件触发一
- COMSOL仿真分析变压器三相短路绕组振动模型:电磁场分布、轴向力、幅向力、磁密分布及振动形变综合研究,COMSOL仿真解析:变压器三相短路绕组振动模型-涵盖电磁场、力分布与振动形变结果探究,com
- 多智能体系统分布式动态事件触发一致性控制策略:固定与切换拓扑下的控制策略研究,多智能体系统分布式动态事件触发一致性控制策略:固定与切换拓扑研究,02固定及切拓扑多智能体系统分布式动态事件触发一致性控制
- 分布式智能体事件触发一致性协议:线性多动态环境的计算与应用研究,线性多智能体分布式动态事件触发一致性研究,01线性多智能体分布式动态事件触发一致性 ,核心关键词:线性多智能体; 分布式; 动态事件触发
- Simpack轨道客车模型非线性临界速度解析:超越时速300的横坐标分析图,Simpack轨道客车模型非线性临界速度研究:超越时速300的关键参数分析,simpack轨道客车模型,非线性临界速度300
- 单级式三相光伏并网逆变器波形详解:探究并网电流与直流母线电压追踪电网电压波形的关系及实际应用场景,单级式三相光伏并网逆变器波形详解:探究并网电流与直流母线电压追踪电网电压的动态表现 ,单级式三相光伏并
- 基于SpringBoot的在线交友系统
- HCL AppScan标准版web应用安全扫描报告 - csdn08021402案例解析与安全评估
- WinRAR-简体中文-7.10及其许可证
- **基于滑模控制的MMC并网逆变器研究**,MMC并网逆变器:基于滑模控制的优化策略与实验结果分析,MMC并网逆变器 滑模控制 1.MMC工作在整流侧,子模块个数N=22, 直流侧电压Udc=1
- 深度解析:整车八自由度Simulink模型的开发与应用,基于Simulink平台的整车八自由度仿真模型研究,整车八自由度simulink模型 ,核心关键词: 整车; 八自由度; simulink模型
- C语言epoll的实例服务端用法
- 基于花授粉优化算法的西班牙风场风速与功率预测模型:VMD与EEMD联合优化的预测方法研究,基于花授粉优化算法的西班牙风场风速与功率预测模型研究与应用,针对西班牙风场数据进行风场风速预测和功率预测,也可
- 2022优化版:媲美TI的磁链无感方案,全开放源码,无开发板限制,超越TI的磁链无感方案全新出炉:源码全开,优化升级,领先同行,媲美ti的磁链无感方案 2022最新优化版 源码不含开发板,全部开放
- C语言实现poll服务端
- 图形配置运动控制软件框架Demo(C#开发,支持图形缩放、工具增删改、参数加载保存、适配多种控制器、电机IO映射),图形配置运动控制软件框架Demo(C#开发,支持图形缩放、工具增删改、参数加载保存、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


