
# 支付宝爬虫(Scrapy版本)
---
<h3 id="Q&A">问题反馈</h3>
在使用中有任何问题,可以反馈给我,以下联系方式跟我交流
* Author: Leo
* Wechat: Leo-sunhailin
* E-mail: 379978424@qq.com
* Github URL: [项目链接](https://github.com/sunhailin-Leo/AlipaySpider-Scrapy)
---
* 目录
* [目前的进度](#Now)
* [开发环境](#DevelopEnv)
* [安装方式](#HowToInstall)
* [功能](#Function)
* [技术点](#TechPoints)
* [题外话](#FreeChat)
* [未来的进度](#Future)
---
<h3 id="Now">目前的进度</h3>
* 2019年1月2日:
* 目前建议运行AlipayCore_v2的代码(如果没有装pywin32的依赖的话尽量不要使用AlipayCore)
* 好久一段时间没有更新了(账单通过selenium的方式基本上都会被支付宝识破了)
* 爬取账单的接口的核心就是cookie的有效性,打算之后从cookie的有效性上开始入手
* 目前代码基本定型,后续需要交流的可以加我的微信或者QQ或者提issue也可以(目前暂时因为工作原因没有太多精力去研究了)
* 可能通过验证码登录的方式会比较有效(但是偶尔也会被封~)
* 新增的一些东西:
* spiders下新增了一个v2的方式就是通过Scrapy结合urllib的形式进行爬取(偶尔可行,主要还是需要面对支付宝的点击流模型)
* utils下就新增bill_page_option(一下账单的参数), bill_parser简单的urllib的爬虫
* 2018年11月30日:
* 今天先整理下代码, 好长一段时间没有认真看这段代码了,这几天会梳理一下也有可能会更新一下代码
* 2018年9月16日:
* 更新了一下用户主页的数据获取(账户 余额、余额宝详情、花呗详情)
* 账单详情依旧无法完整获取(账单下载也有点击流识别)
* 尝试使用了pywin32和pymouse系列的方式去点击(暂时没有什么进展), 打算用C写个dll真实模拟鼠标移动(待更新)
* conf文件夹中放了一个pywin32-221 python3.4的安装包(windows的, 感兴趣的小伙伴可以尝试一下)
* 2018年8月8日:
* 支付宝又双叒叕改了个人主页的样式和数据获取方式
* 之前有一段时间可以通过接口进行获取,但现在支付宝取消了这个接口
* 2018年7月2日:
* 题外话:
* 又好一段时间才捡起这个项目.对支付宝这个反爬开始绝望了.
* 最近应该会研究下...感觉selenium解决不了问题...
* 更新项目:
* 解决了下Windows控制台的报错的问题(加入了一个win_unicode_console包)
* 删除了一些无用的代码
* 2018年3月14日:
* 题外话:
* 好一段时间没有更新了,支付宝的反爬有点强.慢慢研究~
* 更新项目:
* 加入二维码登录的方式(需要自己手动扫码)
* 2018年2月4日:
* 更新说明看Release
* 2018年1月:
* 将更新提上日程,在测试二维码登录.先上个半成品
* 原先密码登陆的现在基本上不能用了.因为个人页面多了一种反爬手段,其次就是跳出二维码页面.
* 上面这些问题,将在之后尽量解决.
* 大概在2017年11月~12月的样子:
* 开始出现跳出验证码页面了.原因应该是支付宝反爬的模型增强了.
* 这段时间维护时间不多,都是个人测试没有更新代码上去
* 2017年10月 参加DoraHacks时:
* 当时能够获取到账单和账户信息.
---
<h3 id="DevelopEnv">开发环境</h3>
* 系统版本:Win10 x64
* Python版本:3.4.4
* Python库版本列表:
* win_unicode_console: 0.5
* Pillow: 5.0.0
* Scrapy:1.5.0
* selenium:3.13.0
* requests:2.18.4
* pymongo:3.6.1
* python_dateutil:2.7.0
* Ps: 一定要配好Python的环境,不然Scrapy的命令可能会跑不起来
*
---
<h3 id="DevelopEnv">安装和运行方式</h3>
* 安装库
```python
# !!!最新登录方式(暂未加入命令, 切换登录需要自己的去改动代码) --- 推荐方式!!!
python cmdline_start_spider.py
```
```Python
# 项目根目录下,打开命令行
windows下:
pip install -r requirements.txt
Linux 下:
pip3 install -r requirements.txt (py2没有测试过, 感兴趣的可以测试一下)
```
* 启动(可以忽略不看)
```Python
# 项目根目录下,启动爬虫
scrapy crawl AlipaySpider -a username="你的用户名" -a password="你的密码"
# 必选参数
-a username=<账号>
-a password=<密码>
# 可选参数
-a option=<爬取类型>
# 1 -> 购物; 2 -> 线下; 3 -> 还款; 4 -> 缴费
# 这里面有四种类型数据对应四种不同的购物清单
#####################################################
# 实验版本
scrapy crawl AlipayQR
# 暂时还没有参数, 能登陆到个人页面了(概率到账单页面).
```
---
<h3 id="Function">功能</h3>
1. 模拟登录支付宝(账号密码和二位都可以登陆)
2. 获取自定义账单记录和花呗剩余额度(2017年10月份的时候个人页面还有花呗总额度的,后面改版没有了.再之后又出现了,应该是支付宝内部在做调整)
3. 数据存储在MongoDB中(暂时存储在MongoDB,后续支持sqlite,json或其他格式的数据)
4. 日志记录系统,启动爬虫后会在项目根目录下创建一个Alipay.log的文件(同时写入文件和输出在控制台)
---
<h3 id="TechPoints">技术点</h3>
吐槽一下: 这点可能没啥好说,因为代码是从自己之前写的用非框架的代码搬过来的,搬过来之后主要就是适应Scrapy这个框架,理解框架的意图和执行顺序以及项目的结构,然后进行兼容和测试。
我这个项目主要就用到Spider模块(即爬虫模块),Pipeline和item(即写数据的管道和实体类)
Downloader的那块基本没做处理,因为核心还是在用selenium + webdriver,解析页面用的是Scrapy封装好的Selector.
<strong>Scrapy具体的流程看下图: (从官方文档搬过来的)</strong>
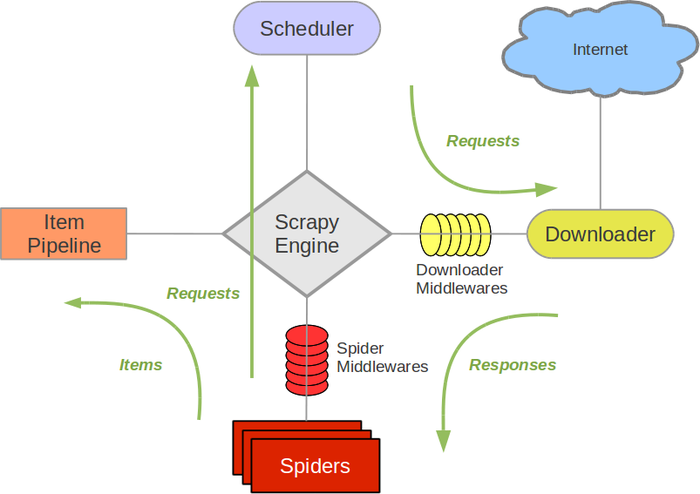
---
<h3 id="FreeChat">题外话</h3>
题外话模块:
上一段讲到了一个Selector,这个是东西是Scrapy基于lxml开发的,但是真正用的时候其实和lxml的selector有点区别.
举个例子吧:
```Python
# 两段相同的标签获取下面的文字的方式
# lxml
name = str(tr.xpath('td[@class="name"]/p/a/text()').strip()
# Scrapy
name = tr.xpath('string(td[@class="name"]/p/a)').extract()[0].strip()
```
两行代码对同一个标签的文字提取的方法有些不一样,虽然到最后的结果一样。
lxml中有一个"string(.)"方法也是为了提取文字,但是这个方法是要在先指定了父节点或最小子节点后再使用,就可以获取父节点以下的所有文字或最小子节点对应的文字信息.
而Scrapy的Selector则可以在"string(.)"里面写入标签,方便定位,也很清晰的看出是要去获取文字信息.
具体区别其实可以对比下我非框架下的和Scrapy框架下的代码,里面用xpath定位的方式有点不一样.
1. selenium + lxml: [非框架](https://github.com/sunhailin-Leo/Alipay-Spider)
2. Scrapy + selenium: [Scrapy](https://github.com/sunhailin-Leo/AlipaySpider-Scrapy)
---
<h3 id="Future">未来的进度</h3>
1. 解决账单获取的问题,目前基本都被二维码页面挡住了(需要研究一段时间, 暂时没有办法解决)
---
<h3 id="Hole">已经搁置的进度</h3>
* 下面的搁置着先:
~~1. 数据源保存的可选择性(从多源选择单源写入到多源写入)~~
~~2. 修改配置文件的自由度(增加修改settings.py的参数)~~
~~3. 尽可能优化爬虫的爬取速度~~
~~4. 研究Scrapy的自定义�
 AlipaySpider on Scrapy(use chrome driver); 支付宝爬虫(基于Scrapy).zip (30个子文件)
AlipaySpider on Scrapy(use chrome driver); 支付宝爬虫(基于Scrapy).zip (30个子文件)  AlipaySpider-Scrapy-master
AlipaySpider-Scrapy-master  scrapy.cfg 268B cmdline_start_spider.py 1KB
scrapy.cfg 268B cmdline_start_spider.py 1KB requirements.txt 138B AlipayScrapy pipelines.py 1KB utils time_util.py 7KB bill_page_option.py 1KB __pycache__ time_util.cpython-34.pyc 5KB __init__.cpython-34.pyc 157B bill_parser.py 8KB extract_data.py 2KB common_utils.py 1KB spiders __init__.py 161B AlipayQR.py 20KB AlipayCore_v2.py 9KB AlipayCore.py 25KB __pycache__ __init__.cpython-34.pyc 159B AlipayCore.cpython-34.pyc 10KB items.py 896B settings.py 3KB __pycache__ __init__.cpython-34.pyc 151B items.cpython-34.pyc 978B settings.cpython-34.pyc 860B pipelines.cpython-34.pyc 1KB conf
requirements.txt 138B AlipayScrapy pipelines.py 1KB utils time_util.py 7KB bill_page_option.py 1KB __pycache__ time_util.cpython-34.pyc 5KB __init__.cpython-34.pyc 157B bill_parser.py 8KB extract_data.py 2KB common_utils.py 1KB spiders __init__.py 161B AlipayQR.py 20KB AlipayCore_v2.py 9KB AlipayCore.py 25KB __pycache__ __init__.cpython-34.pyc 159B AlipayCore.cpython-34.pyc 10KB items.py 896B settings.py 3KB __pycache__ __init__.cpython-34.pyc 151B items.cpython-34.pyc 978B settings.cpython-34.pyc 860B pipelines.cpython-34.pyc 1KB conf  chromedriver.exe 7.91MB pywin32-221.win-amd64-py3.4.exe 8.39MB DDx64.dll 3.12MB chromedriver2-35.exe 6.11MB middlewares.py 2KB README.md 8KB 项目授权码.txt 268B
chromedriver.exe 7.91MB pywin32-221.win-amd64-py3.4.exe 8.39MB DDx64.dll 3.12MB chromedriver2-35.exe 6.11MB middlewares.py 2KB README.md 8KB 项目授权码.txt 268B资源评论


不走小道
- 粉丝: 3365
- 资源: 5054

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- dbeaver-ce-24.3.1-x86-64-setup.exe
- 国际象棋桌子检测6-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord数据集合集.rar
- 某平台广告投入分析与销售预测
- 连接ESP32手表来做验证20241223-140953.pcapng
- 小偏差线性化模型,航空发动机线性化,非线性系统线性化,求解线性系统具体参数,最小二乘拟合 MATLAB Simulink 航空发动机,非线性,线性,非线性系统,线性系统,最小二乘,拟合,小偏差,系统辨
- 好用的Linux终端管理工具,支持自定义多行脚本命令,密码保存、断链续接,SFTP等功能
- Qt源码ModbusTCP 主机客户端通信程序 基于QT5 QWidget, 实现ModbusTCP 主机客户端通信,支持以下功能: 1、支持断线重连 2、通过INI文件配置自定义服务器I
- QGroundControl-installer.exe
- 台球检测40-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 颜色拾取器 for Windows
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


