4.1设置hosts
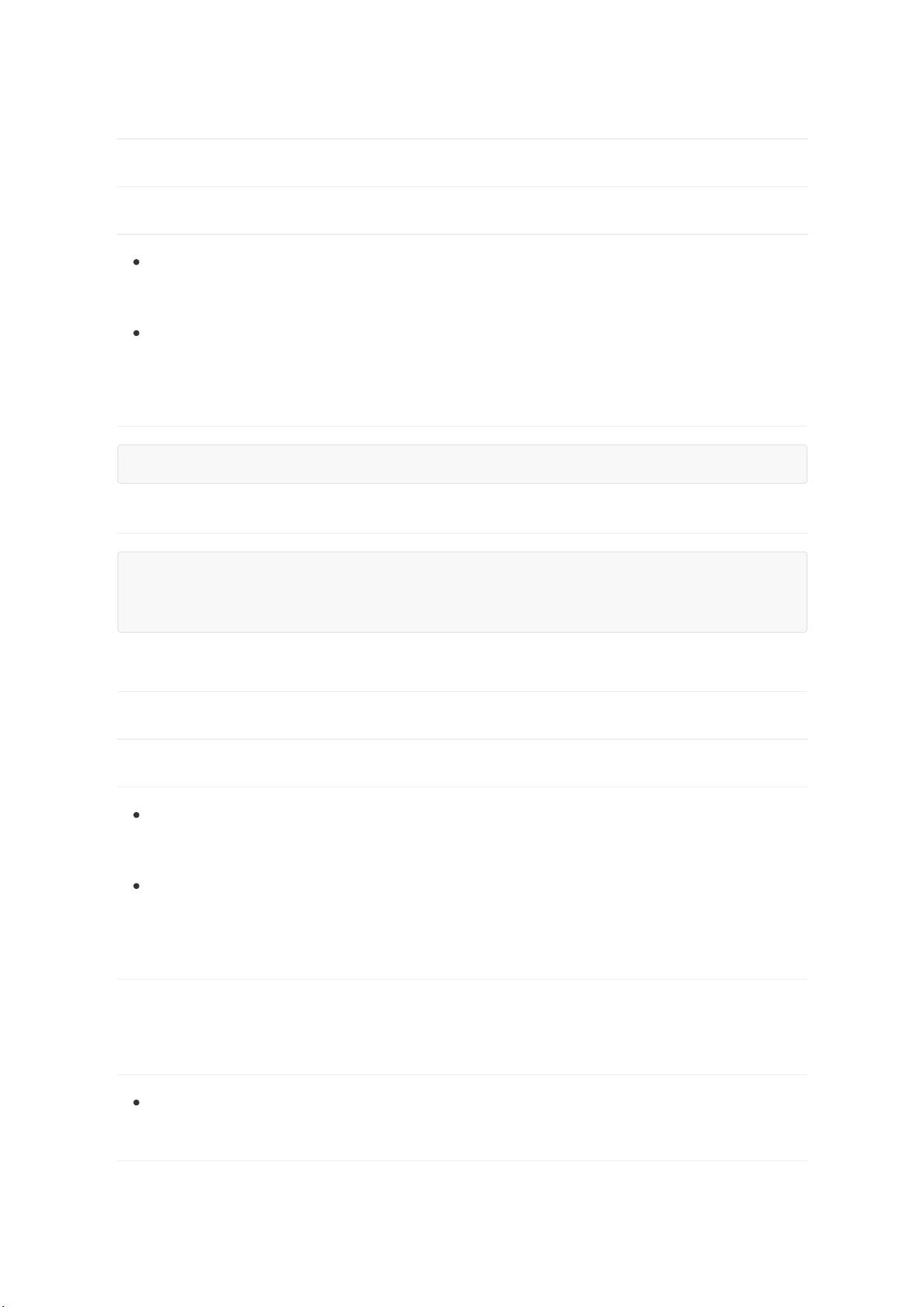
进入目录/etc/hosts,增加如下配置,每台机器都要配置
4.2 检查三台机器时间
需要确定三台机器的时间一致
4.3 配置zookeeper
4.3.1配置文件修改
注:三台机器配置一样
1.将conf文件夹下的zoo_sample.cfg重新命名为zoo.cfg
2.修改zoo.cfg文件内容
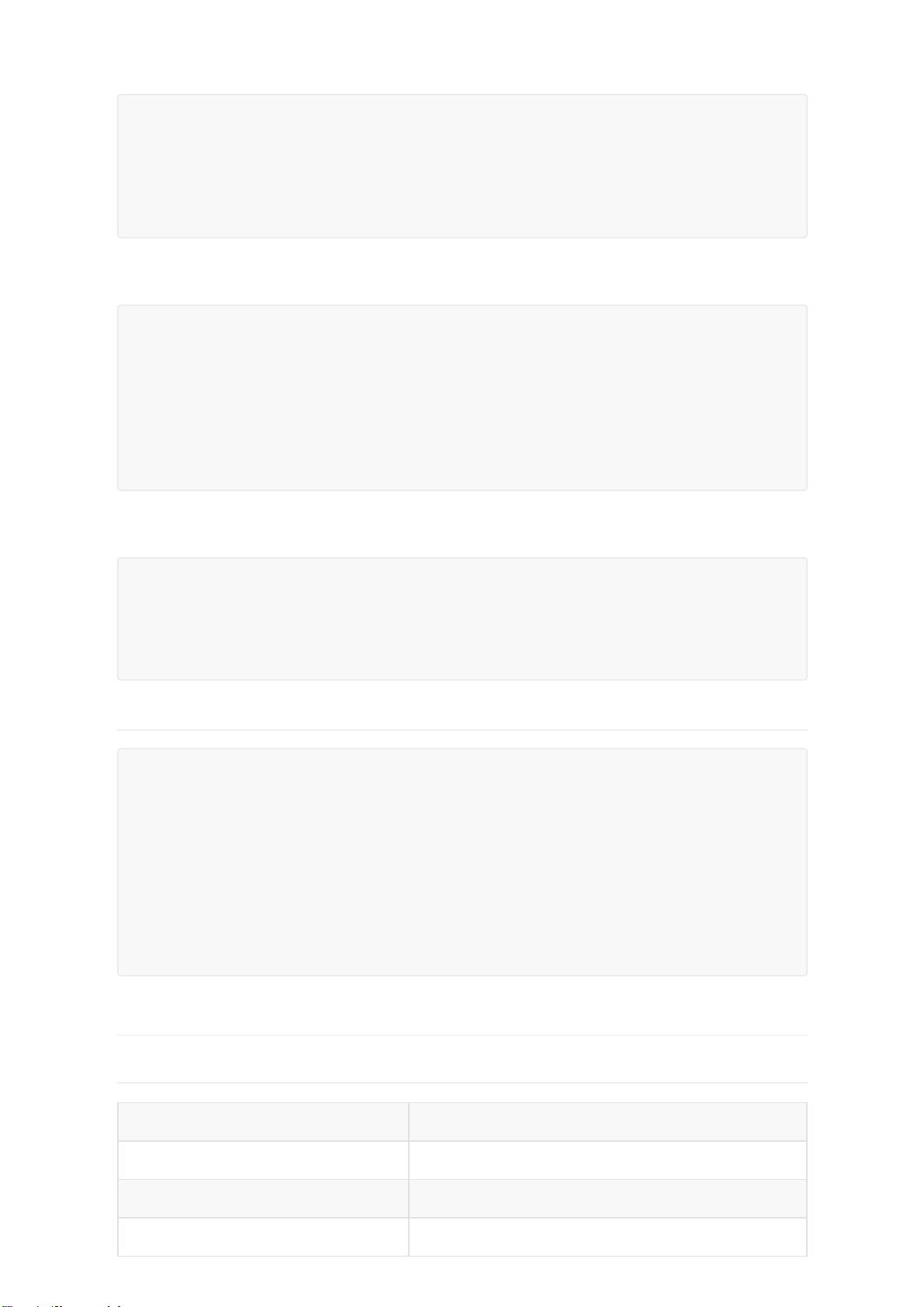
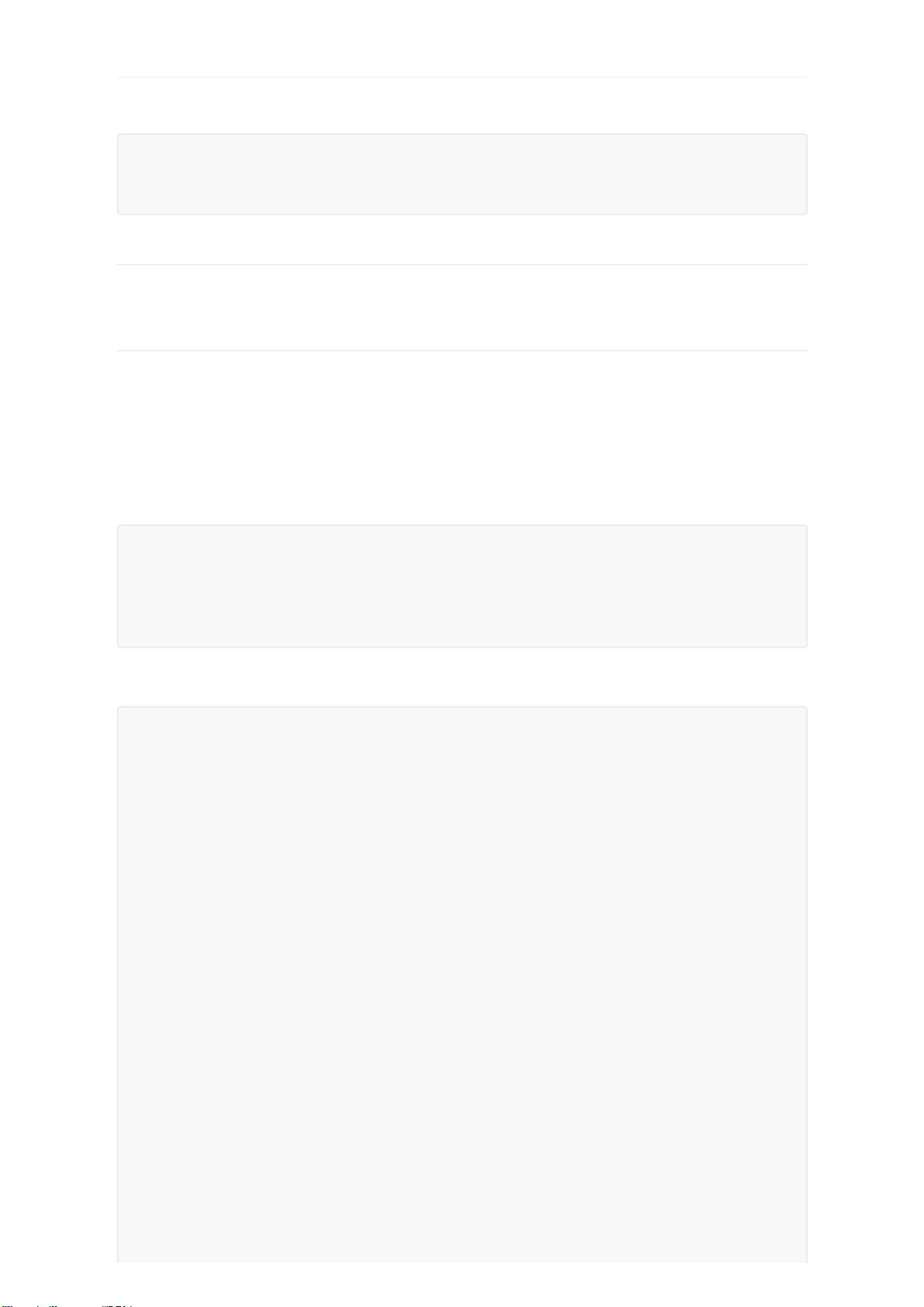
完整的配置如下
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/cloud/zookeeper-3.4.10/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours