MATLAB/Simulink for Digital Communication 09


CHAPTER 9 Information and Coding
9.1 Measure of Information - Entropy
9.2 Source Coding
9.2.1 Huffman Coding
9.2.2 Lempel-Ziv-Welch Coding
9.2.3 Source Coding vs. Channel Coding
9.3 Channel Model and Channel Capacity
9.4 Channel Coding
9.4.1 Waveform Coding
9.4.2 Linear Block Coding
9.4.3 Cyclic Coding
9.4.4 Convolutional Coding and Viterbi Decoding
9.4.5 Trellis-Coded Modulation
9.4.6 Turbo Coding
9.4.7 Low-Density Parity-Check (LDPC) Coding
9.4.8 Differential Space-Time Block Coding (DSTBC)
9.5 Coding Gain
Chapter Outline
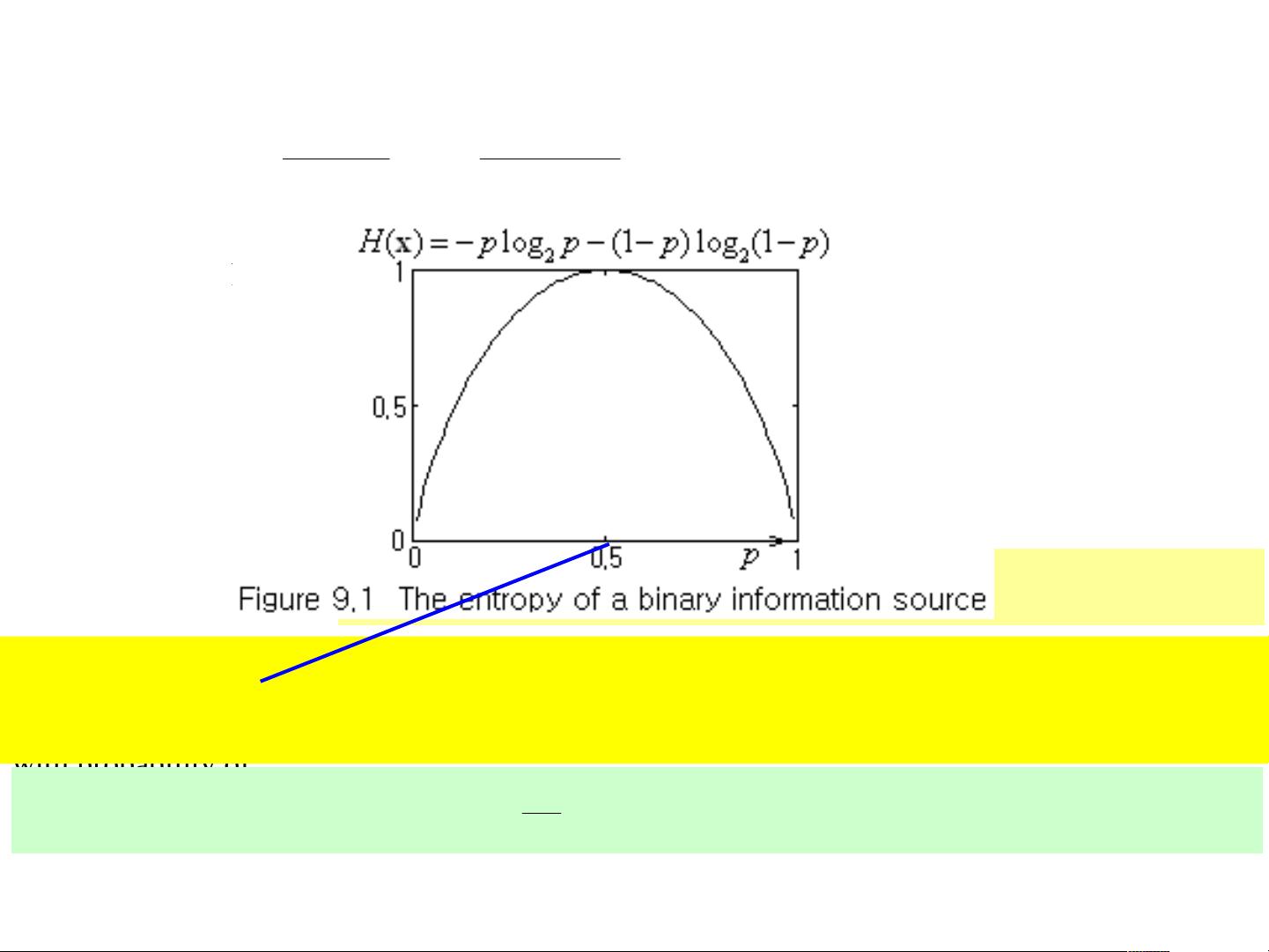
9.1 MEASURE OF INFORMATION – ENTROPY
On the premise that the outputs from an information source such as data, speech, or audio/video
disk can be regarded as a random process, the information theory defines the self information of
an event with probability as
i
x
)(
i
xP
2 2
1
( ) log log [bits] (9.1.1)
( )
( )
i i
i
I x
P x
P x
This measure of information is large/small for an event of lower/higher probability. Why is it
defined like that? It can be intuitively justified/understood by observing the following:
- A message that there was or will be an earthquake in the area where earthquake is very rare has
a value of big news and therefore can be believed to have a lot of information. But, another
message that there will be an earthquake in the area where earthquakes are frequent is of
much
less value as a news and accordingly, can be regarded as having a little information.
- For instance, the information contained in an event which happens with probability is
computed to be zero according to this definition, which fits our intuition.
( ) 1
i
P x
Source: MATLAB/Simulink for Digital Communication by Won Y. Yang et al. © 2009 ( wyyang53@hanmail.net, http://wyyang53.com.ne.kr )


剩余63页未读,继续阅读













- 1
- 2
前往页