






基于
基于
lucene
lucene
的搜索引擎
的搜索引擎
2007/07/01
2007/07/01

引言
引言
本文用
本文用
lucene
lucene
和
和
Heritrix
Heritrix
构建了一个
构建了一个
Web
Web
搜索应用程
搜索应用程
序
序
Lucene
Lucene
是基于
是基于
Java
Java
的全文信息检索包,它目前是
的全文信息检索包,它目前是
Ap
Ap
ache Jakarta
ache Jakarta
家族下面的一个开源项目。
家族下面的一个开源项目。
Lucene
Lucene
很强大,但是,无论多么强大的搜索引擎工具,
很强大,但是,无论多么强大的搜索引擎工具,
在其后台,都需要一样东西来支援它,那就是网络爬虫
在其后台,都需要一样东西来支援它,那就是网络爬虫
S
S
pider
pider
。网络爬虫,又被称为蜘蛛
。网络爬虫,又被称为蜘蛛
Spider
Spider
,或是网络机器
,或是网络机器
人、
人、
BOT
BOT
等,这些都无关紧要,最重要的是要认识到,
等,这些都无关紧要,最重要的是要认识到,
由于爬虫的存在,才使得搜索引擎有了丰富的资源。
由于爬虫的存在,才使得搜索引擎有了丰富的资源。
Heritrix
Heritrix
是一个纯由
是一个纯由
Java
Java
开发的、开源的
开发的、开源的
Web
Web
网络爬
网络爬
虫,用户可以使用它从网络上抓取想要的资源。它来自于
虫,用户可以使用它从网络上抓取想要的资源。它来自于
www.archive.org
www.archive.org
。
。
Heritrix
Heritrix
最出色之处在于它的可扩展性,
最出色之处在于它的可扩展性,
开发者可以扩展它的各个组件,来实现自己的抓取逻辑。
开发者可以扩展它的各个组件,来实现自己的抓取逻辑。
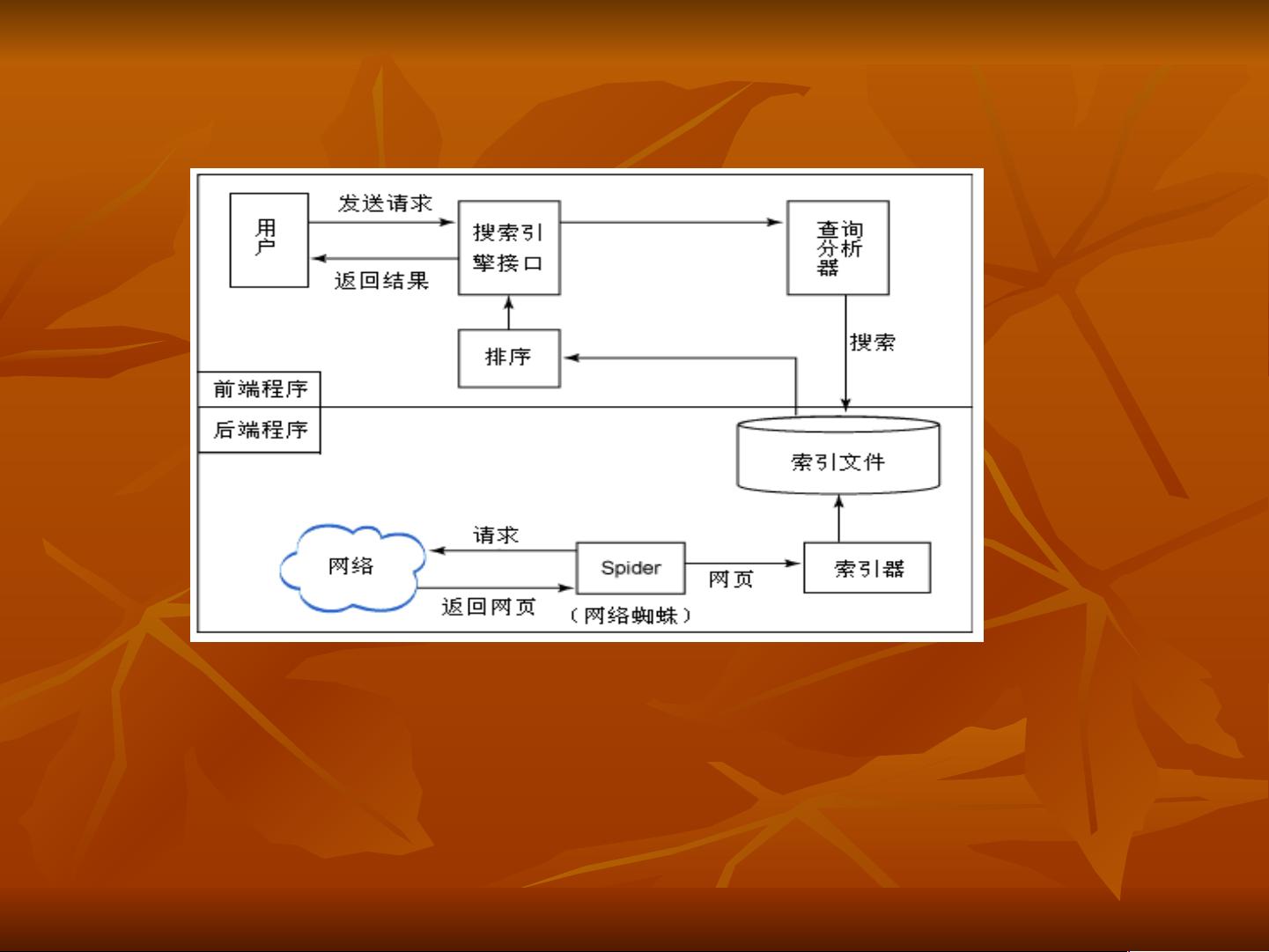
系统架构
系统架构
在前端流程中,用户在搜索引擎提供的界面中输入要搜索的
关键词,这里提到的用户界面一般是一个带有输入框的 Web 页
面,然后应用程序将搜索的关键词解析成搜索引擎可以理解的形
式,并在索引文件上进行搜索操作。在排序后,搜索引擎返回搜
索结果给用户。在后端流程中,网络爬虫从因特网上获取 Web
页面,然后索引子系统解析这些 Web 页面并存入索引文件中。

开发环境
开发环境
我们开发一个
我们开发一个
Web
Web
应用程序利用
应用程序利用
Lucene
Lucene
来检索存放在
来检索存放在
文件服务器上的
文件服务器上的
HTML
HTML
文档。在开始之前,需要准备如
文档。在开始之前,需要准备如
下环境:
下环境:
Heritrix 1.10.0
Heritrix 1.10.0
Eclipse
Eclipse
集成开发环境 (
集成开发环境 (
Eclipse 3.3+WTP 2.0)
Eclipse 3.3+WTP 2.0)
Tomcat 6.0
Tomcat 6.0
Lucene Library (lucene 2.0+luceneHtmlPaser)
Lucene Library (lucene 2.0+luceneHtmlPaser)
JDK 1.6
JDK 1.6
这个工程使用
这个工程使用
Eclipse
Eclipse
进行
进行
Web
Web
应用程序的开发,
应用程序的开发,
最终这个
最终这个
Web
Web
应用程序跑在
应用程序跑在
Tomcat 6.0
Tomcat 6.0
上面。在准备
上面。在准备
好开发所必需的环境之后,我们接下来进行
好开发所必需的环境之后,我们接下来进行
Web
Web
应用程
应用程
序的开发。
序的开发。
在
在
Eclipse
Eclipse
里配置
里配置
Heritrix
Heritrix
的开发环
的开发环
境
境
Heritrix
Heritrix
在
在
Eclipse
Eclipse
中的工程配置好后的截图,以及
中的工程配置好后的截图,以及
workspace
workspace
中文件夹的预览
中文件夹的预览
图
图
2. Eclipse
2. Eclipse
工程视图下的包结构
工程视图下的包结构
图
图
3 .
3 .
文件夹中的工程
文件夹中的工程













