
- -
Hadoop 云计算平台及相关组件搭建安装过程详细教程
——
Hbase+Pig+Hive+Zookeeper+Ganglia+Chukwa+Eclipse
等
一.安装环境简介
根据官网, 已在 主机组成的集群系统上得到验证,而 平台
是作为开发平台支持的,由于分布式操作尚未在 平台上充分测试,所以
还 不 作 为 一 个 生 产 平 台 。 下 还 需 要 安 装 , 是 在
平台上运行的 模拟环境,提供上述软件之外的 支持。
实际条件下在 系统下进展 伪分布式安装时,出现了许多未知问
题。在 系统下安装,以伪分布式进展测试,然后再进展完全分布式的实验环
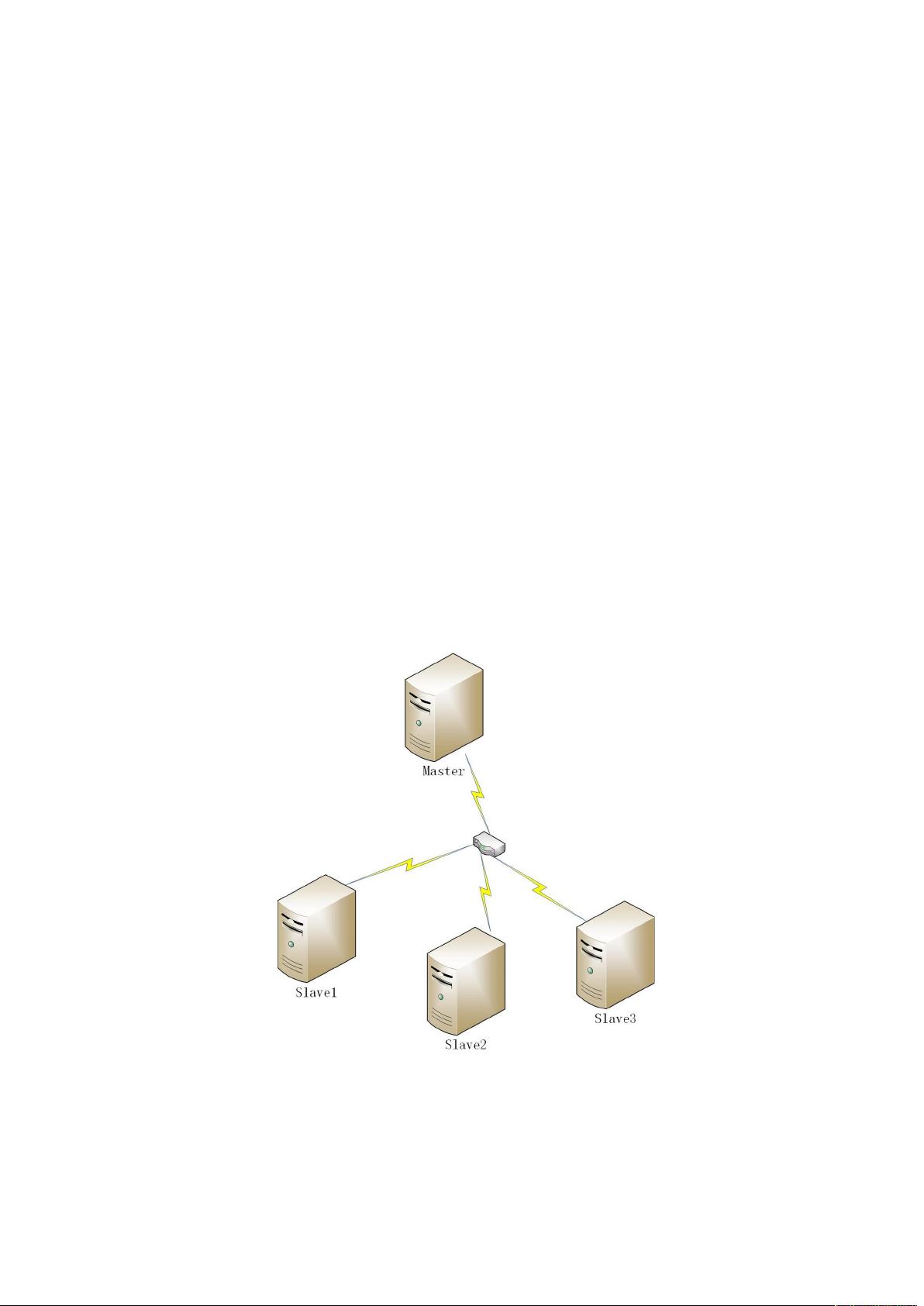
境部署。 完全分布模式的网络拓补图如图六所示:
() 网络拓补图如六所示:
图六完全分布式网络拓补图
() 硬件要求:搭建完全分布式环境需要假设干计算机集群, 和
处理器、存、硬盘等参数要求根据情况而定。
- . word.zl-


剩余22页未读,继续阅读
资源评论


pyhm63
- 粉丝: 10
- 资源: 20万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


