# 手把手教你使用YOLOV5训练自己的目标检测模型
大家好,这里是肆十二(dejahu),好几个月没有更新了,这两天看了一下关注量,突然多了1k多个朋友关注,想必都是大作业系列教程来的小伙伴。既然有这么多朋友关注这个大作业系列,并且也差不多到了毕设开题和大作业提交的时间了,那我直接就是一波更新。这期的内容相对于上期的果蔬分类和垃圾识别无论是在内容还是新意上我们都进行了船新的升级,我们这次要使用YOLOV5来训练一个口罩检测模型,比较契合当下的疫情,并且目标检测涉及到的知识点也比较多,这次的内容除了可以作为大家的大作业之外,也可以作为一些小伙伴的毕业设计。废话不多说,我们直接开始今天的内容。
> B站讲解视频:[手把手教你使用YOLOV5训练自己的目标检测模型_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1YL4y1J7xz)
>
> CSDN博客:[手把手教你使用YOLOV5训练自己的目标检测模型-口罩检测-视频教程_dejahu的博客-CSDN博客](https://blog.csdn.net/ECHOSON/article/details/121939535)
>
> 代码地址:[YOLOV5-mask-42: 基于YOLOV5的口罩检测系统-提供教学视频 (gitee.com)](https://gitee.com/song-laogou/yolov5-mask-42)
>
> 处理好的数据集和训练好的模型:[YOLOV5口罩检测数据集+代码+模型2000张标注好的数据+教学视频.zip-深度学习文档类资源-CSDN文库](https://download.csdn.net/download/ECHOSON/63290559)
>
> 更多相关的数据集:[目标检测数据集清单-附赠YOLOV5模型训练和使用教程_dejahu的博客-CSDN博客](https://blog.csdn.net/ECHOSON/article/details/121892887)
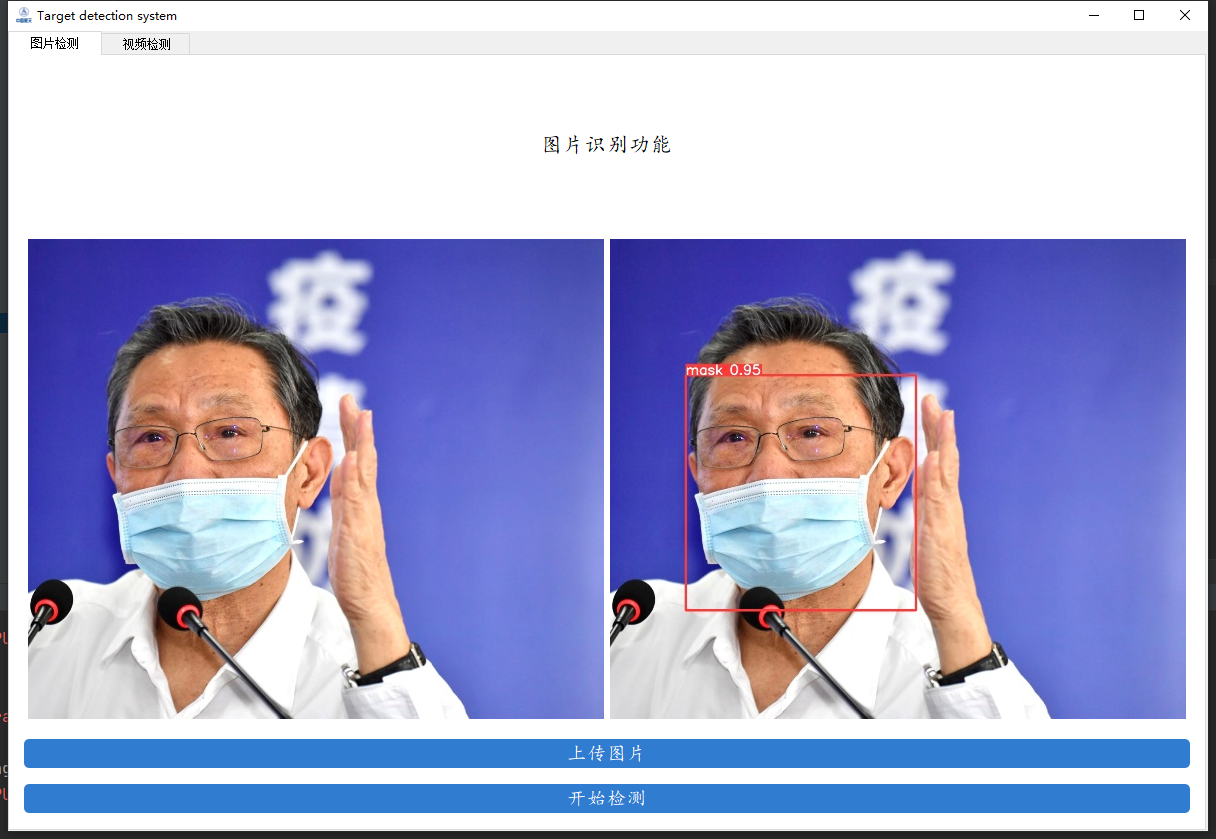
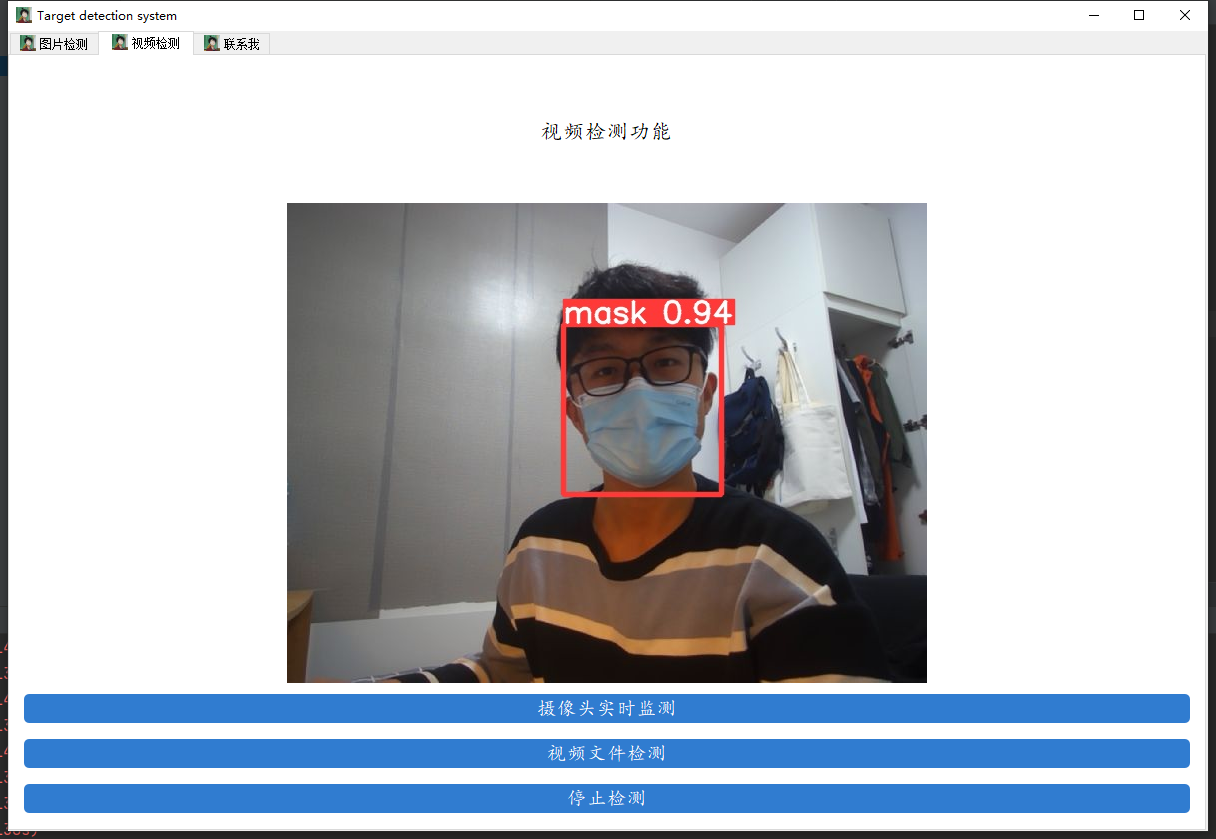
先来看看我们要实现的效果,我们将会通过数据来训练一个口罩检测的模型,并用pyqt5进行封装,实现图片口罩检测、视频口罩检测和摄像头实时口罩检测的功能。
## 下载代码
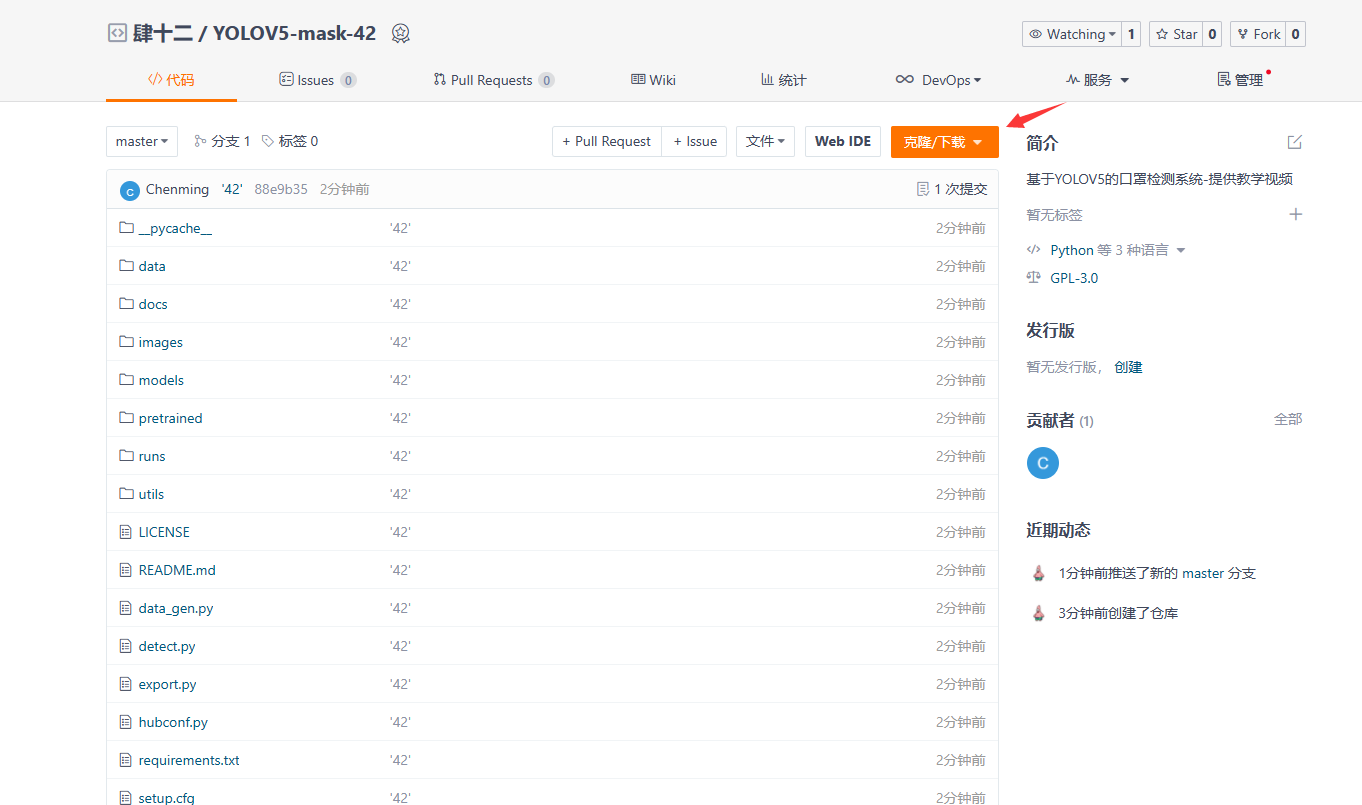
代码的下载地址是:[[YOLOV5-mask-42: 基于YOLOV5的口罩检测系统-提供教学视频 (gitee.com)](https://gitee.com/song-laogou/yolov5-mask-42)](https://github.com/ultralytics/yolov5)
## 配置环境
不熟悉pycharm的anaconda的小伙伴请先看这篇csdn博客,了解pycharm和anaconda的基本操作
[如何在pycharm中配置anaconda的虚拟环境_dejahu的博客-CSDN博客_如何在pycharm中配置anaconda](https://blog.csdn.net/ECHOSON/article/details/117220445)
anaconda安装完成之后请切换到国内的源来提高下载速度 ,命令如下:
```bash
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
```
首先创建python3.8的虚拟环境,请在命令行中执行下列操作:
```bash
conda create -n yolo5 python==3.8.5
conda activate yolo5
```
### pytorch安装(gpu版本和cpu版本的安装)
实际测试情况是YOLOv5在CPU和GPU的情况下均可使用,不过在CPU的条件下训练那个速度会令人发指,所以有条件的小伙伴一定要安装GPU版本的Pytorch,没有条件的小伙伴最好是租服务器来使用。
GPU版本安装的具体步骤可以参考这篇文章:[2021年Windows下安装GPU版本的Tensorflow和Pytorch_dejahu的博客-CSDN博客](https://blog.csdn.net/ECHOSON/article/details/118420968)
需要注意以下几点:
* 安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装
* 30系显卡只能使用cuda11的版本
* 一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突
我这里创建的是python3.8的环境,安装的Pytorch的版本是1.8.0,命令如下:
```cmd
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
```
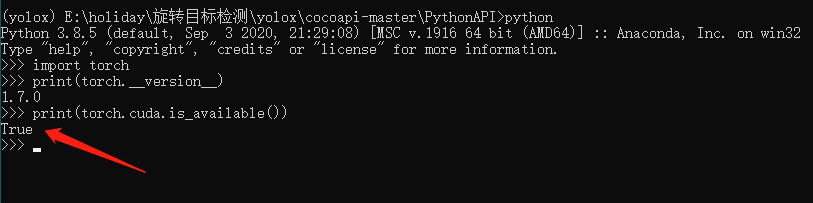
安装完毕之后,我们来测试一下GPU是否
### pycocotools的安装
<font color='red'>后面我发现了windows下更简单的安装方法,大家可以使用下面这个指令来直接进行安装,不需要下载之后再来安装</font>
```
pip install pycocotools-windows
```
### 其他包的安装
另外的话大家还需要安装程序其他所需的包,包括opencv,matplotlib这些包,不过这些包的安装比较简单,直接通过pip指令执行即可,我们cd到yolov5代码的目录下,直接执行下列指令即可完成包的安装。
```bash
pip install -r requirements.txt
pip install pyqt5
pip install labelme
```
### 测试一下
在yolov5目录下执行下列代码
```bash
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt
```
执行完毕之后将会输出下列信息

在runs目录下可以找到检测之后的结果
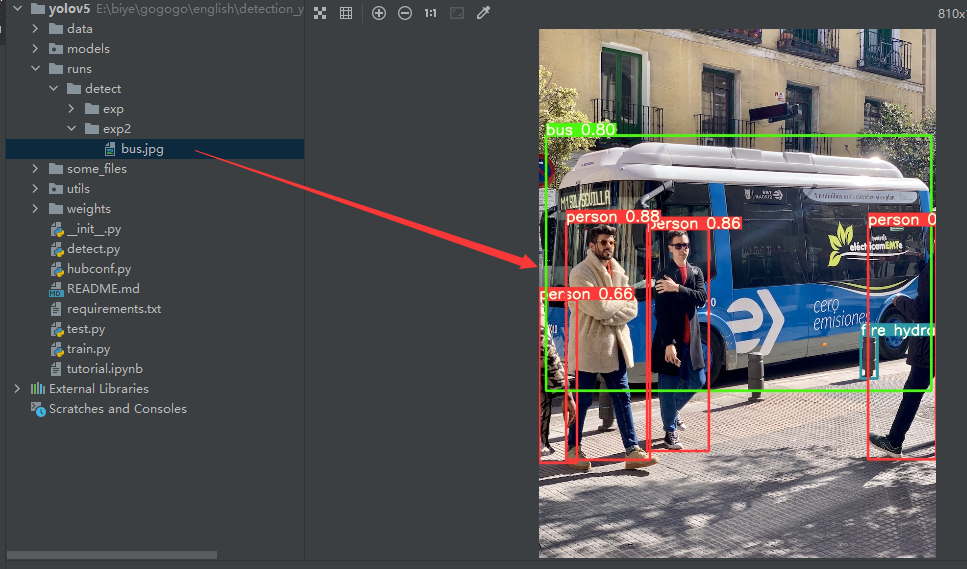
按照官方给出的指令,这里的检测代码功能十分强大,是支持对多种图像和视频流进行检测的,具体的使用方法如下:
```bash
python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube video
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
```
## 数据处理
这里改成yolo的标注形式,之后专门出一期数据转换的内容。
数据标注这里推荐的软件是labelimg,通过pip指令即可安装
在你的虚拟环境下执行`pip install labelimg -i https://mirror.baidu.com/pypi/simple`命令进行安装,然后在命令行中直接执行labelimg软件即可启动数据标注软件。
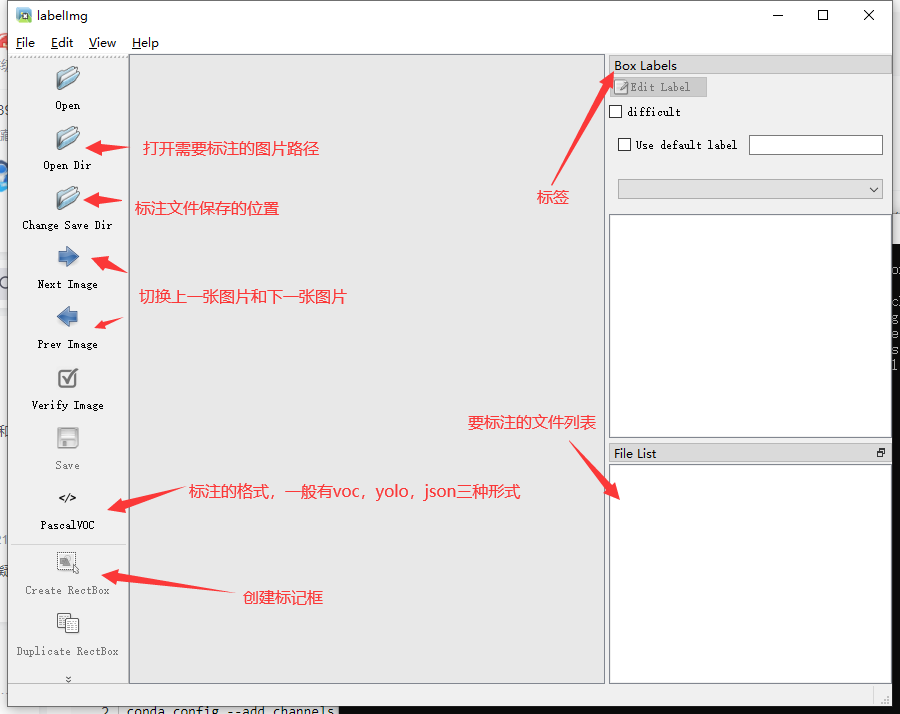
软件启动后的界面如下:
### 数据标注
虽然是yolo的模型训练,但是这里我们还是选择进行voc格式的标注,一是方便在其他的代码中使用数据集,二是我提供了数据格式转化
**标注的过程是:**
**1.打开图片目录**
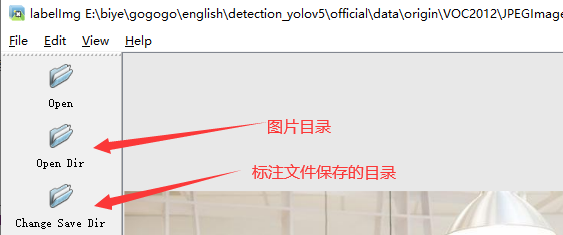
**2.设置标注文件保存的目录并设置自动保存**
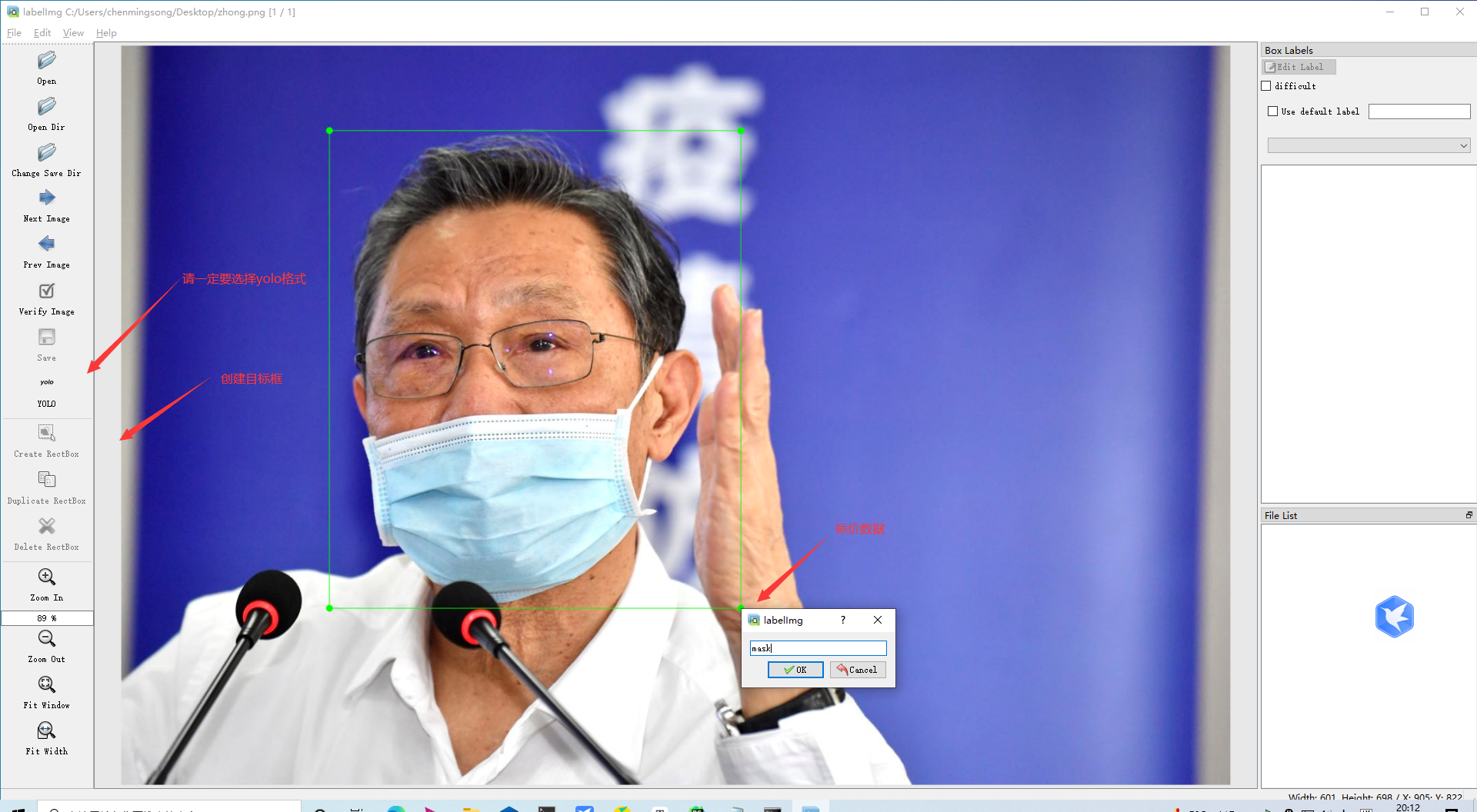
**3.开始标注,画框,标记目标的label,`crtl+s`保存,然后d切换到下一张继续标注,不断重复重复**
labelimg的快捷键如下,学会快捷键可以帮助你提高数据标注的效率。

版权申诉
 YOLO v5安全帽检测模型代码和已训练好的模型权重 (201个子文件)
YOLO v5安全帽检测模型代码和已训练好的模型权重 (201个子文件)  events.out.tfevents.1651388459.USER-20190512PJ.12012.0 988KB events.out.tfevents.1651586473.USER-20190512PJ.16468.0 965KB setup.cfg 923B results.csv 29KB results.csv 15KB Dockerfile 2KB Dockerfile 821B .gitignore 229B yolov5-mask-42-master.iml 495B tutorial.ipynb 55KB logo.jpeg 33KB up.jpeg 28KB right.jpeg 27KB right.jpeg 25KB up.jpeg 21KB tmp_upload.jpeg 21KB
events.out.tfevents.1651388459.USER-20190512PJ.12012.0 988KB events.out.tfevents.1651586473.USER-20190512PJ.16468.0 965KB setup.cfg 923B results.csv 29KB results.csv 15KB Dockerfile 2KB Dockerfile 821B .gitignore 229B yolov5-mask-42-master.iml 495B tutorial.ipynb 55KB logo.jpeg 33KB up.jpeg 28KB right.jpeg 27KB right.jpeg 25KB up.jpeg 21KB tmp_upload.jpeg 21KB phone_419.jpg 646KB bus.jpg 476KB phone_89.jpg 444KB phone_1310.jpg 392KB phone_633.jpg 344KB val_batch2_pred.jpg 332KB val_batch2_pred.jpg 331KB val_batch2_labels.jpg 328KB val_batch2_labels.jpg 328KB val_batch1_pred.jpg 318KB val_batch1_pred.jpg 318KB phone_689.jpg 315KB val_batch1_labels.jpg 315KB val_batch1_labels.jpg 315KB val_batch0_pred.jpg 243KB val_batch0_pred.jpg 242KB val_batch0_labels.jpg 237KB val_batch0_labels.jpg 237KB phone_2096.jpg 223KB phone_2423.jpg 197KB phone_2402.jpg 181KB train_batch1.jpg 174KB train_batch1.jpg 174KB zidane.jpg 165KB single_result_vid.jpg 161KB train_batch2.jpg 117KB train_batch2.jpg 117KB train_batch0.jpg 96KB train_batch0.jpg 96KB single_result.jpg 90KB upload_show_result.jpg 88KB fishman.jpg 74KB tmp_upload.jpg 59KB LICENSE 34KB README.md 15KB README.md 14KB README.md 10KB README.md 2KB
phone_419.jpg 646KB bus.jpg 476KB phone_89.jpg 444KB phone_1310.jpg 392KB phone_633.jpg 344KB val_batch2_pred.jpg 332KB val_batch2_pred.jpg 331KB val_batch2_labels.jpg 328KB val_batch2_labels.jpg 328KB val_batch1_pred.jpg 318KB val_batch1_pred.jpg 318KB phone_689.jpg 315KB val_batch1_labels.jpg 315KB val_batch1_labels.jpg 315KB val_batch0_pred.jpg 243KB val_batch0_pred.jpg 242KB val_batch0_labels.jpg 237KB val_batch0_labels.jpg 237KB phone_2096.jpg 223KB phone_2423.jpg 197KB phone_2402.jpg 181KB train_batch1.jpg 174KB train_batch1.jpg 174KB zidane.jpg 165KB single_result_vid.jpg 161KB train_batch2.jpg 117KB train_batch2.jpg 117KB train_batch0.jpg 96KB train_batch0.jpg 96KB single_result.jpg 90KB upload_show_result.jpg 88KB fishman.jpg 74KB tmp_upload.jpg 59KB LICENSE 34KB README.md 15KB README.md 14KB README.md 10KB README.md 2KB tmp_upload.png 1.63MB results.png 240KB results.png 228KB lufei.png 216KB qq.png 151KB F1_curve.png 137KB F1_curve.png 137KB R_curve.png 129KB R_curve.png 126KB PR_curve.png 103KB PR_curve.png 103KB P_curve.png 102KB P_curve.png 101KB confusion_matrix.png 86KB confusion_matrix.png 84KB yolov5l.pt 89.21MB yolov5m.pt 40.72MB yolov5s.pt 14.02MB best.pt 13.72MB last.pt 13.72MB best.pt 13.72MB last.pt 13.72MB best.pt 13.72MB last.pt 13.72MB datasets.py 44KB datasets_not_print.py 44KB general.py 34KB mytrain.py 33KB train.py 33KB train_server.py 32KB window.py 27KB common.py 27KB wandb_utils.py 25KB tf.py 20KB plots.py 20KB val.py 17KB export.py 16KB yolo.py 15KB metrics.py 13KB torch_utils.py 13KB detect.py 12KB augmentations.py 11KB loss.py 9KB data_gen.py 8KB autoanchor.py 7KB __init__.py 7KB
tmp_upload.png 1.63MB results.png 240KB results.png 228KB lufei.png 216KB qq.png 151KB F1_curve.png 137KB F1_curve.png 137KB R_curve.png 129KB R_curve.png 126KB PR_curve.png 103KB PR_curve.png 103KB P_curve.png 102KB P_curve.png 101KB confusion_matrix.png 86KB confusion_matrix.png 84KB yolov5l.pt 89.21MB yolov5m.pt 40.72MB yolov5s.pt 14.02MB best.pt 13.72MB last.pt 13.72MB best.pt 13.72MB last.pt 13.72MB best.pt 13.72MB last.pt 13.72MB datasets.py 44KB datasets_not_print.py 44KB general.py 34KB mytrain.py 33KB train.py 33KB train_server.py 32KB window.py 27KB common.py 27KB wandb_utils.py 25KB tf.py 20KB plots.py 20KB val.py 17KB export.py 16KB yolo.py 15KB metrics.py 13KB torch_utils.py 13KB detect.py 12KB augmentations.py 11KB loss.py 9KB data_gen.py 8KB autoanchor.py 7KB __init__.py 7KB共 201 条
- 1
- 2
- 3













- 1
- 2
- 3
- 4
- 5
- 6
前往页