

275
This is the Title of the Book, eMatter Edition
Copyright © 2000 O’Reilly & Associates, Inc. All rights reserved.
Chapter 7
In this chapter:
• XSLT Processing
Mechanics
• Single-Template
Stylesheets
• Understanding Input
and Output Options
• Improving Flexibility
with Multiple
Templates
7
Transforming XML
with XSLT
We’ve used XSLT stylesheets in previous chapters to transform database-driven
XML into HTML pages, XML datagrams of a particular vocabulary, SQL scripts,
emails, and so on. If you’re a developer trying to harness your database informa-
tion to maximum advantage on the Web, you’ll find that XSLT is the Swiss Army
knife you want permanently attached to your belt. In a world where the exchange
of structured information is core to your success, and where the ability to rapidly
evolve and repurpose information is paramount, Oracle XML developers who fully
understand how to exploit XSLT are way ahead of the pack.
XSLT 1.0 is the W3C standard language for describing transformations between
XML documents. It is closely aligned with the companion XPath 1.0 standard and
works in concert with it. As we’ll see in this chapter, XPath let’s you say what to
transform, and XSLT provides the complementary language describing how to
carry out the transformation. An XSLT stylesheet describes a set of rules for trans-
forming a source XML document into a result XML document. An XSLT processor
is the software that carries out the transformation based on these rules.
In the simple examples in previous chapters, we have seen three primary ways to
use the Oracle XSLT processor. We’ve used the oraxsl command-line utility, the
XSLT processor’s programmatic API, and the <?xml-stylesheet?> instruction to
associate a stylesheet with an XSQL page. In this chapter, we begin exploring the full
power of the XSLT language to understand how best to use it in our applications.
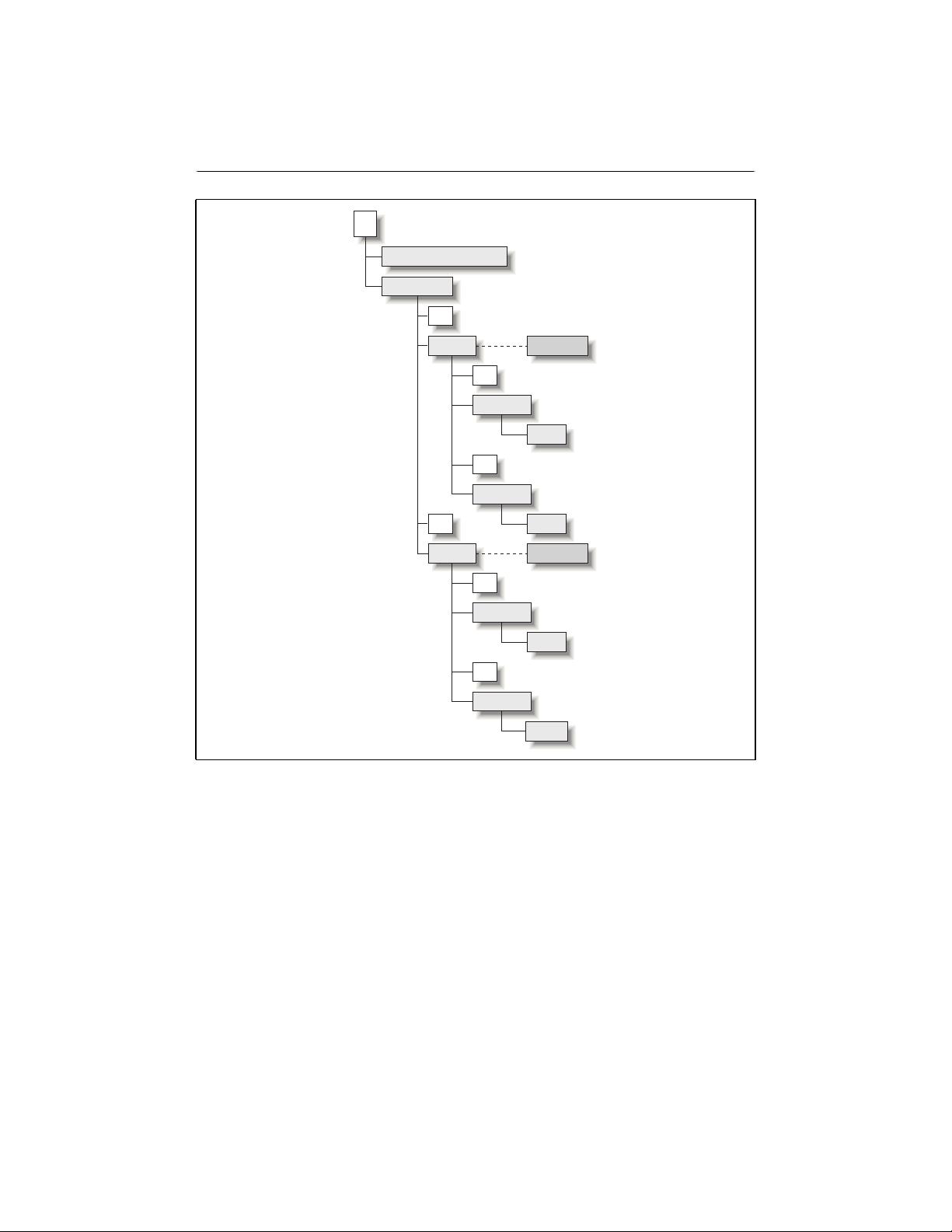
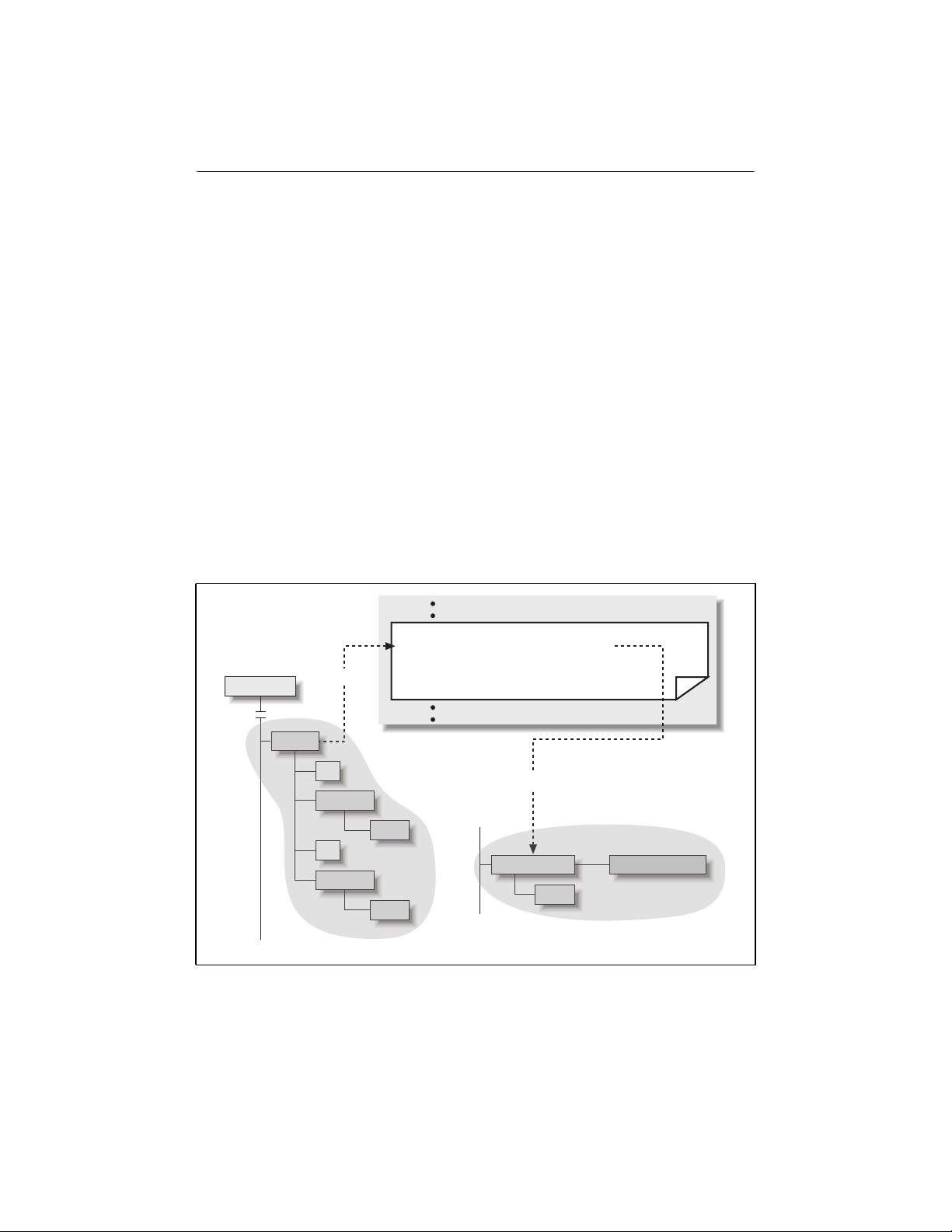
XSLT Processing Mechanics
An XSLT stylesheet describes a transformation that operates on the tree-structured
infoset of a source XML document and produces a tree of nodes as its output.


剩余34页未读,继续阅读
资源评论


pwl2014
- 粉丝: 1
- 资源: 12









最新资源
- 使用Python和Pygame实现圣诞节动画效果
- 数据分析-49-客户细分-K-Means聚类分析
- 企业可持续发展性数据集,ESG数据集,公司可持续发展性数据(可用于多种企业可持续性研究场景)
- chapter9.zip
- 使用Python和Pygame库创建新年烟花动画效果
- 国际象棋检测10-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- turbovnc-2.2.6.x86-64.rpm
- 艾利和iriver Astell&Kern SP3000 V1.30升级固件
- VirtualGL-2.6.5.x86-64.rpm
- dbeaver-ce-24.3.1-x86-64-setup.exe
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


