
代码包括构建倒排列表和对短语进行搜索两个部分;
C++,windows 下运行。
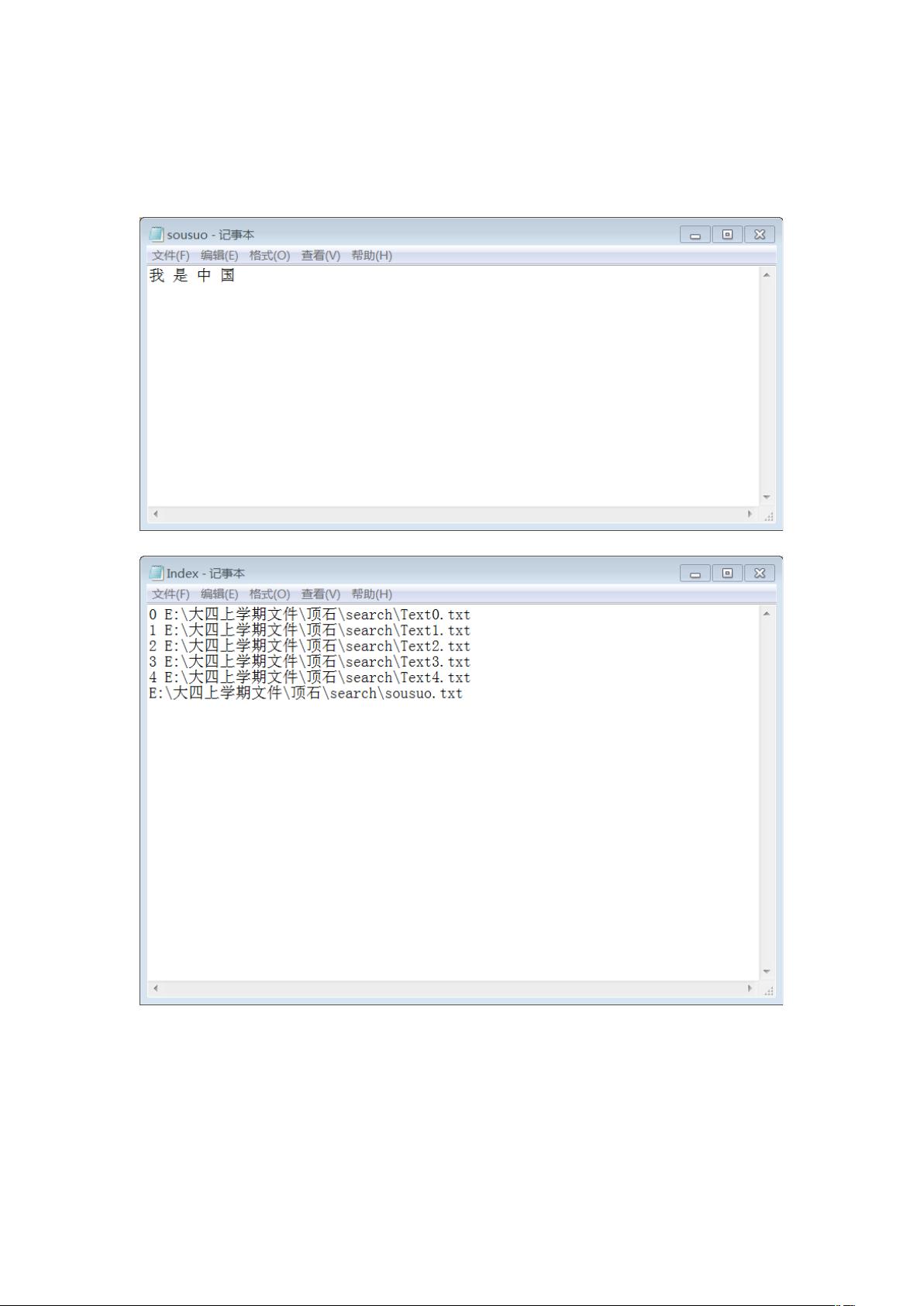
由文档的存储位置来读取文档内容;
文件 sousuo.txt 存储待搜索的短语;
文件 index.txt 存储文档路径以及文档编号;
文件 result.txt 存储所构建出的倒排列表以及短语的搜索结果;
 search.zip (16个子文件)
search.zip (16个子文件)  daopai
daopai  Text4.txt 15B bin Debug
Text4.txt 15B bin Debug  daopai.exe 1.16MB
daopai.exe 1.16MB daopai.depend 193B obj Debug main.o 223KB sousuo.txt 11B result.txt 213B daopai.layout 359B Text3.txt 11B Text1.txt 14B main.cpp 3KB Text0.txt 8B 未命名1.c 3KB Text2.txt 18B Index.txt 259B daopai.cbp 1KB
daopai.depend 193B obj Debug main.o 223KB sousuo.txt 11B result.txt 213B daopai.layout 359B Text3.txt 11B Text1.txt 14B main.cpp 3KB Text0.txt 8B 未命名1.c 3KB Text2.txt 18B Index.txt 259B daopai.cbp 1KB 简单说明.docx 76KB
简单说明.docx 76KB












