
所谓的内核,其实就是 Spark 的内部核心原理。
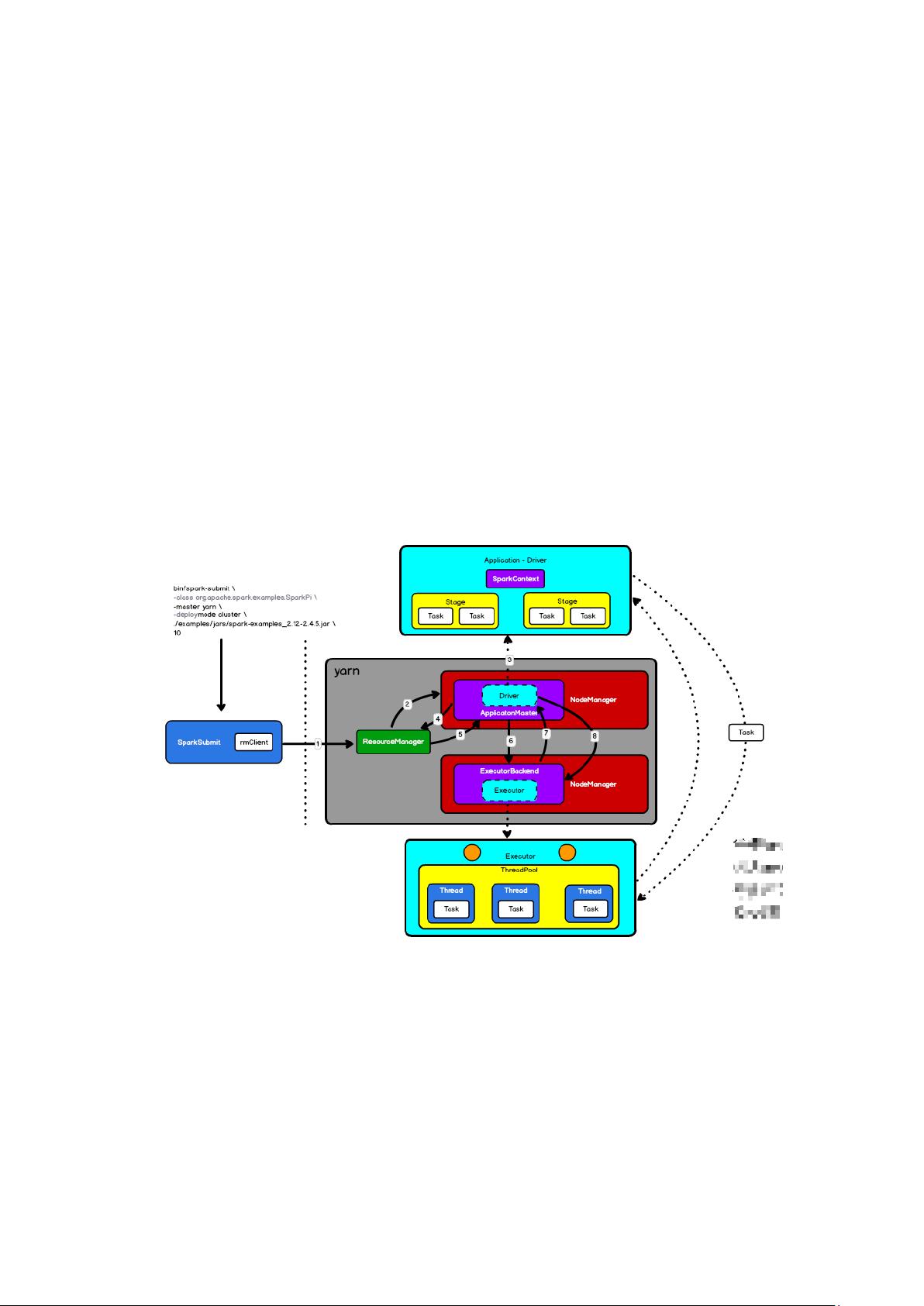
1. Spark 应用提交
(1) Spark 向 Yarn 提交
➢ 当使用 bin/java 执行 java 程序时,会产生 JVM,java 的进程
(2) ApplicationMaster, Driver, Executor
➢ ApplicationMaster 是一个进程
➢ Driver 是一个线程, 但是我们一般会讲 SparkContext 称之为 Driver
➢ Executor 是一个计算对象, 但有时我们将 ExecutorBackend 后台通信对象也称
之为 Executor
2. Spark 内部组件及通信
(1) 通信原理 - IO - RPC
➢ 基本的网络通信:Socket, ServerSocket
➢ 通信框架:AKKA(旧), Netty(新)(AIO)
➢ 三种 IO 方式:BIO(阻塞式), NIO(非阻塞式), AIO(异步)
资源评论


冷酷的本杰明
- 粉丝: 5
- 资源: 11









最新资源
- 2024下半年,CISSP官方10道练习题
- JD-Core是一个用JAVA编写的JAVA反编译器 .zip
- 时间复杂度与数据结构:算法效率的双重奏
- QT 简易项目 网络调试器(未实现连接唯一性) QT5.12.3环境 C++实现
- YOLOv3网络架构深度解析:关键特性与代码实现
- ACOUSTICECHO CANCELLATION WITH THE DUAL-SIGNAL TRANSFORMATION LSTM NETWORK
- 深入解析:动态数据结构与静态数据结构的差异
- YOLOv2:在YOLOv1基础上的飞跃
- imgview图片浏览工具v1.0
- Toony Colors Pro 2 2.2.5的资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


