

978-1-4577-0557-1/12/$26.00 ©2012 IEEE
1
Considerations for Big Data: Architecture and Approach
Kapil Bakshi
Cisco Systems Inc.
13635 Dulles Technology Drive
Herndon, VA 20171
703-484-2057
kabakshi@cisco.com
Abstract—The amount of data in our industry and the world is
exploding. Data is being collected and stored at unprecedented
rates. The challenge is not only to store and manage the vast
volume of data (“big data”), but also to analyze and extract
meaningful value from it. There are several approaches to
collecting, storing, processing, and analyzing big data. The main
focus of the paper is on unstructured data analysis. Unstructured
data refers to information that either does not have a pre-defined
data model or does not fit well into relational tables. Unstructured
data is the fastest growing type of data, some example could be
imagery, sensors, telemetry, video, documents, log files, and e-
mail data files. There are several techniques to address this
problem space of unstructured analytics. The techniques share a
common character tics of scale-out, elasticity and high availability.
MapReduce, in conjunction with the Hadoop Distributed File
System (HDFS) and HBase database, as part of the Apache
Hadoop project is a modern approach to analyze unstructured data.
Hadoop clusters are an effective means of processing massive
volumes of data, and can be improved with the right architectural
approach.
TABLE OF CONTENTS
1. INTRODUCTION ................................................. 1!
2. SQL BASED AND NOSQL DATABASES ............. 1!
3. UNSTRUCTURED ANALYTICS ............................ 2!
4. BENCHMARKS ................................................... 3!
5. PERFORMANCE CONSIDERATIONS ................... 4!
6. CAPACITY PLANNING CONSIDERATIONS ......... 5!
7. SUMMARY ......................................................... 6!
REFERENCES ......................................................... 6!
BIOGRAPHY .......................................................... 7!
1. INTRODUCTION
As the data grows in the industry, new techniques and
approaches need to be adopted. This paper focuses on the
unstructured aspects of data analytics and reviews as a case
study, some of the key projects in Apache Hadoop. This
paper also describes the fundamentals of relational database
management systems (RDBMS) and their use for traditional
big data sets in data warehousing, decision support, and
analytics. The paper then reviews non-relational big data
approaches such as distributed/shared-nothing architectures,
horizontal scaling, key/value stores, and eventual
consistency. This part of the paper differentiates between
structured versus unstructured data. The paper describes
various building blocks and techniques for Map Reduce and
HDFS, HBase and their implementation in an open source
Hadoop framework. This paper focuses on the infrastructure
planning (compute, network, and storage systems), and
reviews Hadoop design criteria and implementation
considerations. Hadoop includes many technologies,
including MapReduce, which interact with the infrastructure
elements while analyzing data. This paper reviews
performance considerations and describes relevant
benchmarks with a Hadoop analytics cluster. In conclusion,
the paper review the alternatives to hosting an analytics
cluster in a public cloud.
2. SQL BASED AND NOSQL DATABASES
The traditional method of managing structured data includes
a relational database and schema to manage the storage and
retrieval of the dataset. For managing large datasets in a
structured fashion, the primary approaches are data
warehouses and data marts. A data warehouse is a relational
database system used for storing, analyzing, and reporting
functions. The data mart is the layer used to access the data
warehouse. The data stored in the warehouse is sourced
from the operational systems. A data warehouse focuses on
data storage. The main source of the data is cleaned,
transformed, catalogued, and made available for data mining
and online analytical functions. The data warehouse and
marts are SQL (Standard Query Language) based databases
systems. The two main approaches to storing data in a data
warehouse are the following:
• Dimensional: Transaction data are partitioned into “facts”
tables, which are generally transaction data and dimensions
tables, which are the reference information that gives
context to the facts.
• Normalized: The tables are grouped together by subject
areas that reflect data categories, such as data on products,
customers, and so on. The normalized structure divides data
into entities, which create several tables in a relational
database.
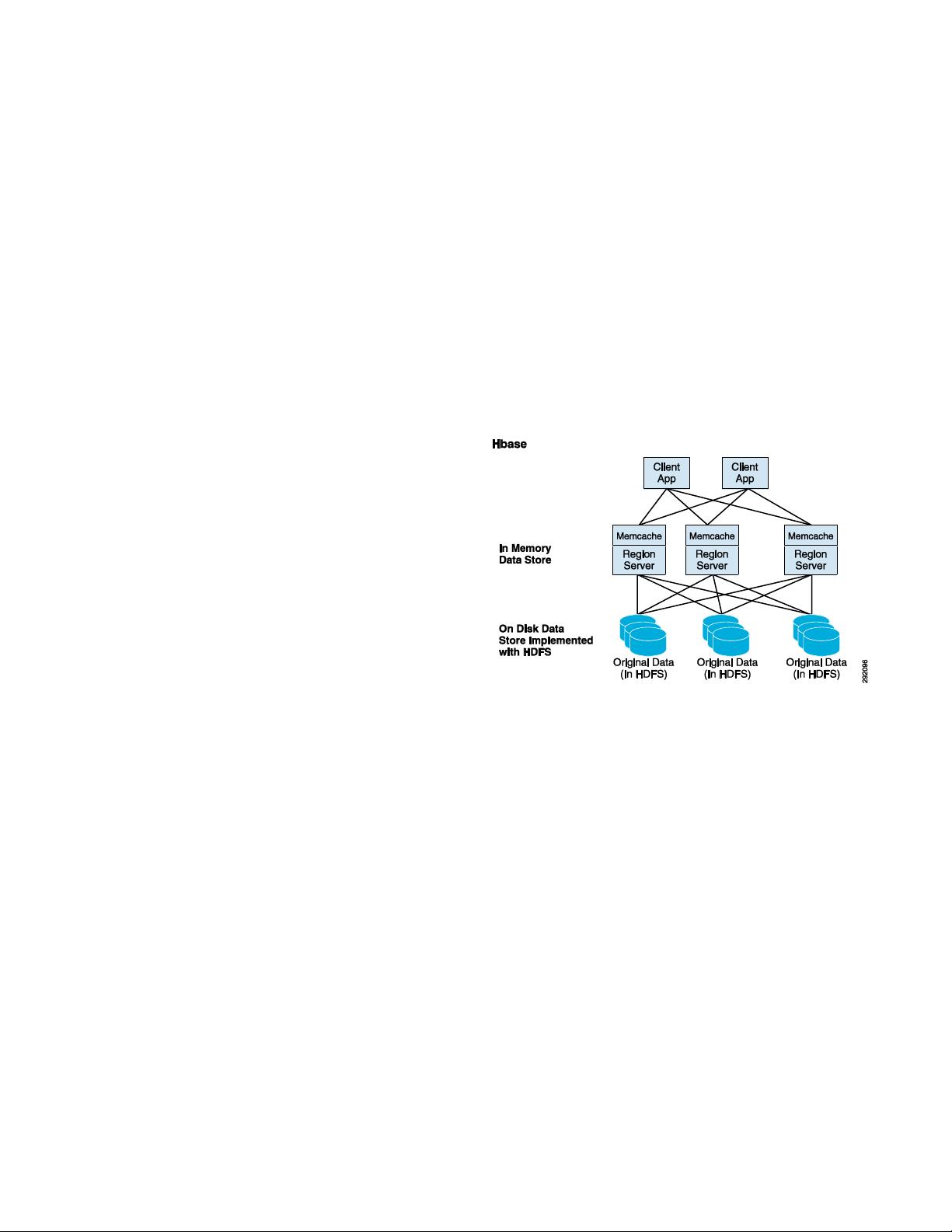
There are several approaches adopted by NoSQL (Not Only
SQL) for storing and managing unstructured data, also
referred to as “non-relational data”. These systems, which
are sometimes also called “key-value stores”, share the
goals of massive scaling “on demand” (elasticity), data
model flexibility and simplified application development
and deployment. NoSQL databases separate data
management and data storage, whereas relational databases
attempt to satisfy both concerns with databases. One of the
剩余6页未读,继续阅读
资源评论

 嘉和的空间2014-05-26不错的书,其中对HDFS的文件系统的讲解和例子很具体清晰。谢谢分享。
嘉和的空间2014-05-26不错的书,其中对HDFS的文件系统的讲解和例子很具体清晰。谢谢分享。

oYiChuangShanHai
- 粉丝: 0
- 资源: 1









最新资源
- YOLOv8完整网络结构图详细visio
- LCD1602电子时钟程序
- 西北太平洋热带气旋【灾害风险统计】及【登陆我国次数评估】数据集-1980-2023
- 全球干旱数据集【自校准帕尔默干旱程度指数scPDSI】-190101-202312-0.5x0.5
- 基于Python实现的VAE(变分自编码器)训练算法源代码+使用说明
- 全球干旱数据集【标准化降水蒸发指数SPEI-12】-190101-202312-0.5x0.5
- C语言小游戏-五子棋-详细代码可运行
- 全球干旱数据集【标准化降水蒸发指数SPEI-03】-190101-202312-0.5x0.5
- spring boot aop记录修改前后的值demo
- 全球干旱数据集【标准化降水蒸发指数SPEI-01】-190101-202312-0.5x0.5
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


