Hue是Apache Hadoop生态系统中的一个开源Web界面,它提供了一个用户友好的图形界面,用于交互式地探索大数据。Hue的Workflow(工作流)组件则是用于构建和管理复杂的Hadoop作业流程,允许用户通过拖拽操作来设计数据处理任务,而无需编写复杂的命令行脚本或Java代码。在本文中,我们将深入探讨如何使用Hue配置和运行一个Workflow。
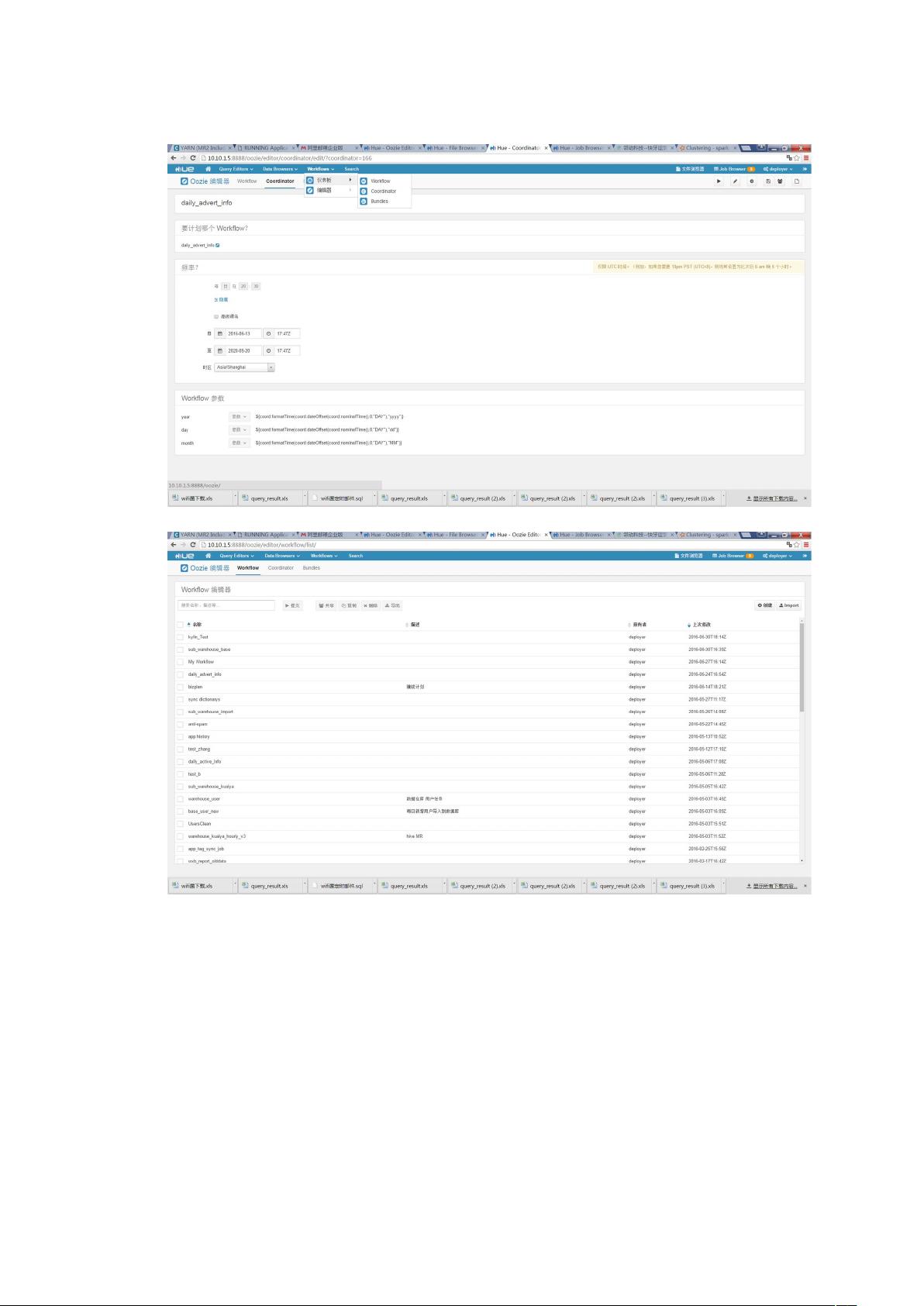
我们从创建Workflow开始。在Hue的工作流编辑器中,你可以看到一个空白的工作区,这就是你构建流程的地方。点击右上角的“创建”按钮,一个新的workflow就会被添加到画布上。这个名字可以自定义,以便于后续识别和管理。
接下来,我们需要添加HQL(Hive查询语言)脚本文件和JAR包。HQL脚本文件通常包含对Hive表的查询,用于数据处理和分析。在Workflow中,你可以通过点击“添加”按钮,然后选择“Hive Action”来导入HQL脚本。确保你已经将HQL脚本上传到了Hue的文件系统,然后在配置界面输入脚本路径。JAR包则可能包含自定义函数或者MapReduce程序,同样,通过“添加”->“Java Action”来引入,指定JAR包的路径。
编辑完Workflow后,别忘了保存你的工作。这一步是确保你的设计不会丢失,尤其是在进行复杂流程设计时尤为重要。在保存后,你可以在预览模式下检查流程的逻辑是否正确,各步骤之间是否有正确的依赖关系。
提交Workflow时,可以添加参数。这些参数可以是环境变量,也可以是Workflow内部使用的变量,它们可以动态地改变Workflow的行为。例如,你可以设置一个参数来控制HQL查询的目标表名,这样在不同环境中运行时,只需更改这个参数,而无需修改整个工作流。
我们来谈谈设置定时。Hue的Workflow支持Cron表达式来设定定时任务,这意味着你可以设置任何你需要的执行频率,如每天的特定时间、每周的某一天等。在“调度”选项卡下,输入Cron表达式并保存,你的Workflow就会按照设定的时间自动执行。
当一切配置完毕,点击“运行”按钮,Workflow就会开始执行。你可以在工作流的运行历史中查看状态,包括成功、失败或其他可能的状态。如果遇到问题,日志信息会帮助你诊断错误原因。
Hue的Workflow配置流程是一个强大的工具,它简化了大数据处理任务的创建和管理工作,使得非程序员也能轻松管理复杂的Hadoop作业。理解并熟练掌握这个流程,对于提升数据处理效率和团队协作具有重要意义。