nutch 详细分析(包括配置文件等)


分析
1 Nutch 简介......................................................................................................................................2
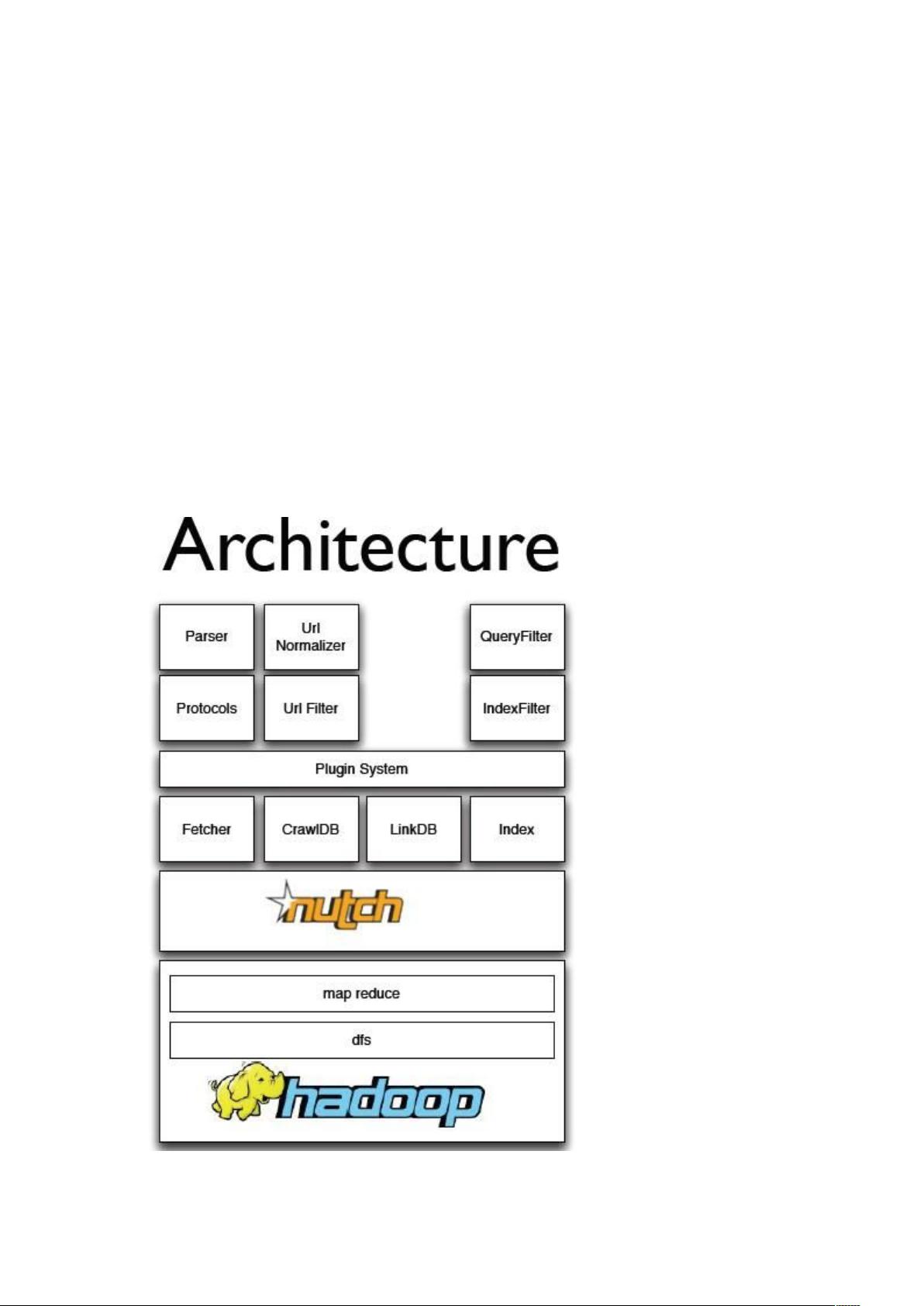
1.1 nutch 体系结构....................................................................................................................2
2 抓取部分.........................................................................................................................................3
2.1 爬虫的数据结构及含义......................................................................................................3
2.2 抓取目录分析......................................................................................................................4
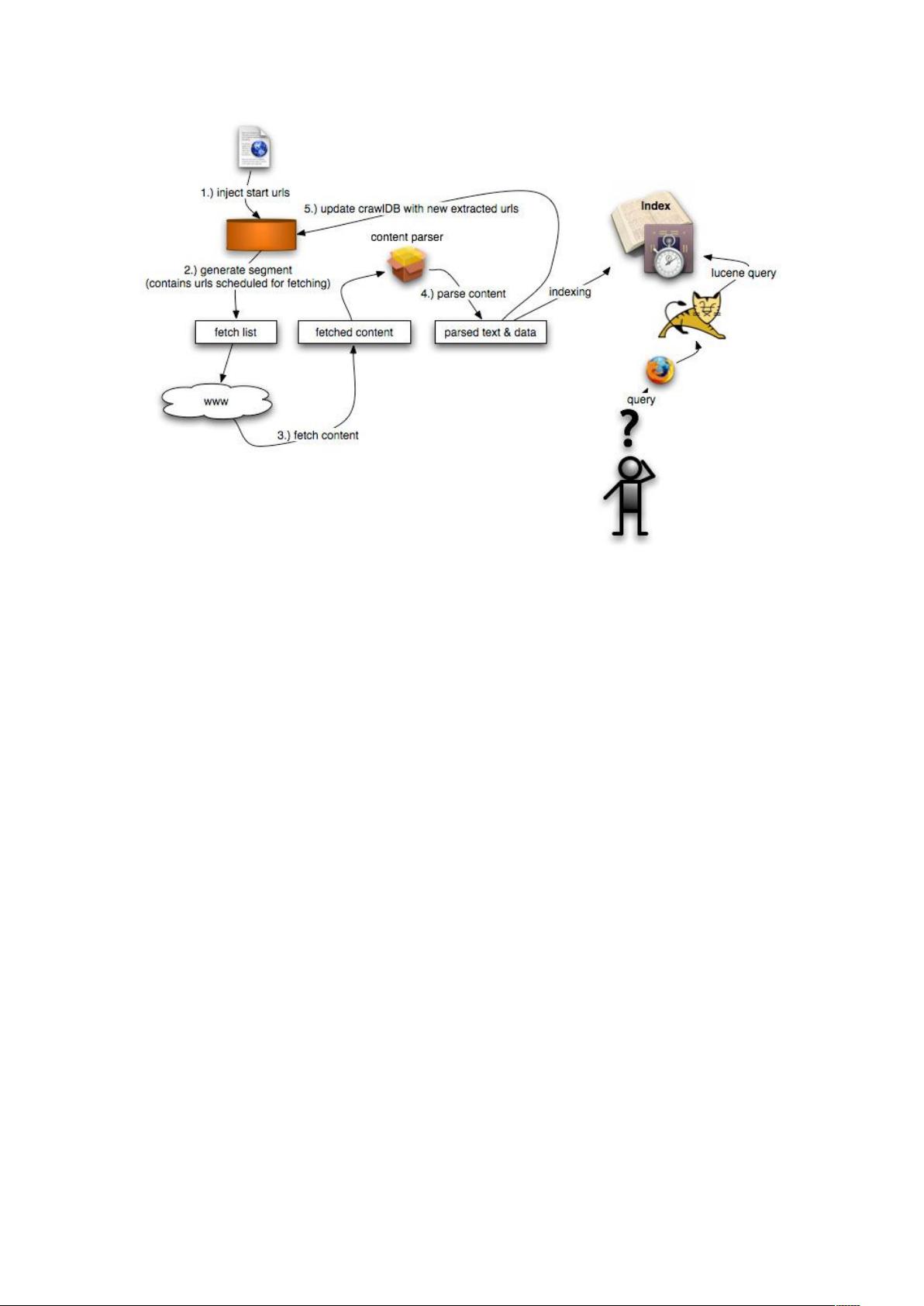
2.3 抓取过程概述......................................................................................................................4
2.4 抓取过程分析......................................................................................................................5
2.4.1 inject 方法.................................................................................................................6
2.4.2 generate 方法..........................................................................................................12
2.4.3 fetch 方法................................................................................................................14
2.4.4 parse 方法................................................................................................................17
2.4.5 update 方法.............................................................................................................17
2.4.6 invert 方法...............................................................................................................20
2.4.7 index 方法...............................................................................................................24
2.4.8 dedup 方法..............................................................................................................28
2.4.9 merge 方法..............................................................................................................32
3 配置文件分析...............................................................................................................................32
3.1 nutch-default.xml 分析......................................................................................................33
3.1.1 <!-- file properties -->.............................................................................................33
3.1.2 <!-- HTTP properties -->.........................................................................................34
3.1.3 <!-- FTP properties -->............................................................................................37
3.1.4 <!-- web db properties -->.......................................................................................39
3.1.5 <!-- generate properties -->.....................................................................................43
3.1.6 <!-- fetcher properties -->.......................................................................................44
3.1.7 <!-- indexer properties -->......................................................................................45
3.1.8 <!-- indexingfilter plugin properties -->.................................................................47
3.1.9 <!-- analysis properties -->.....................................................................................47
3.1.10 <!-- searcher properties -->...................................................................................47
3.1.11 <!-- URL normalizer properties -->......................................................................50
3.1.12 <!-- mime properties -->.......................................................................................50
3.1.13 <!-- plugin properties -->......................................................................................51
3.1.14 <!-- parser properties -->.......................................................................................52
3.1.15 <!-- urlfilter plugin properties -->.........................................................................53
3.1.16 <!-- scoring filters properties -->..........................................................................54
3.1.17 <!-- clustering extension properties -->................................................................55
3.1.18 <!-- ontology extension properties -->..................................................................55
3.1.19 <!-- query-basic plugin properties -->..................................................................56
3.1.20 <!-- creative-commons plugin properties -->.......................................................57
3.1.21 <!-- query-more plugin properties -->..................................................................57
3.1.22 <!-- microformats-reltag plugin properties -->.....................................................58
3.1.23 <!-- language-identifier plugin properties -->......................................................58
3.1.24 <!-- Temporary Hadoop 0.17.x workaround. -->..................................................59


剩余62页未读,继续阅读













- 1
- 2
前往页