

Javen-Studio 咖啡小屋 – Annotated Lucene(源码剖析中文版)
作者
naven
网站
http://javenstudio.org/
- 1 -
Annotated Lucene(源码剖析中文版)
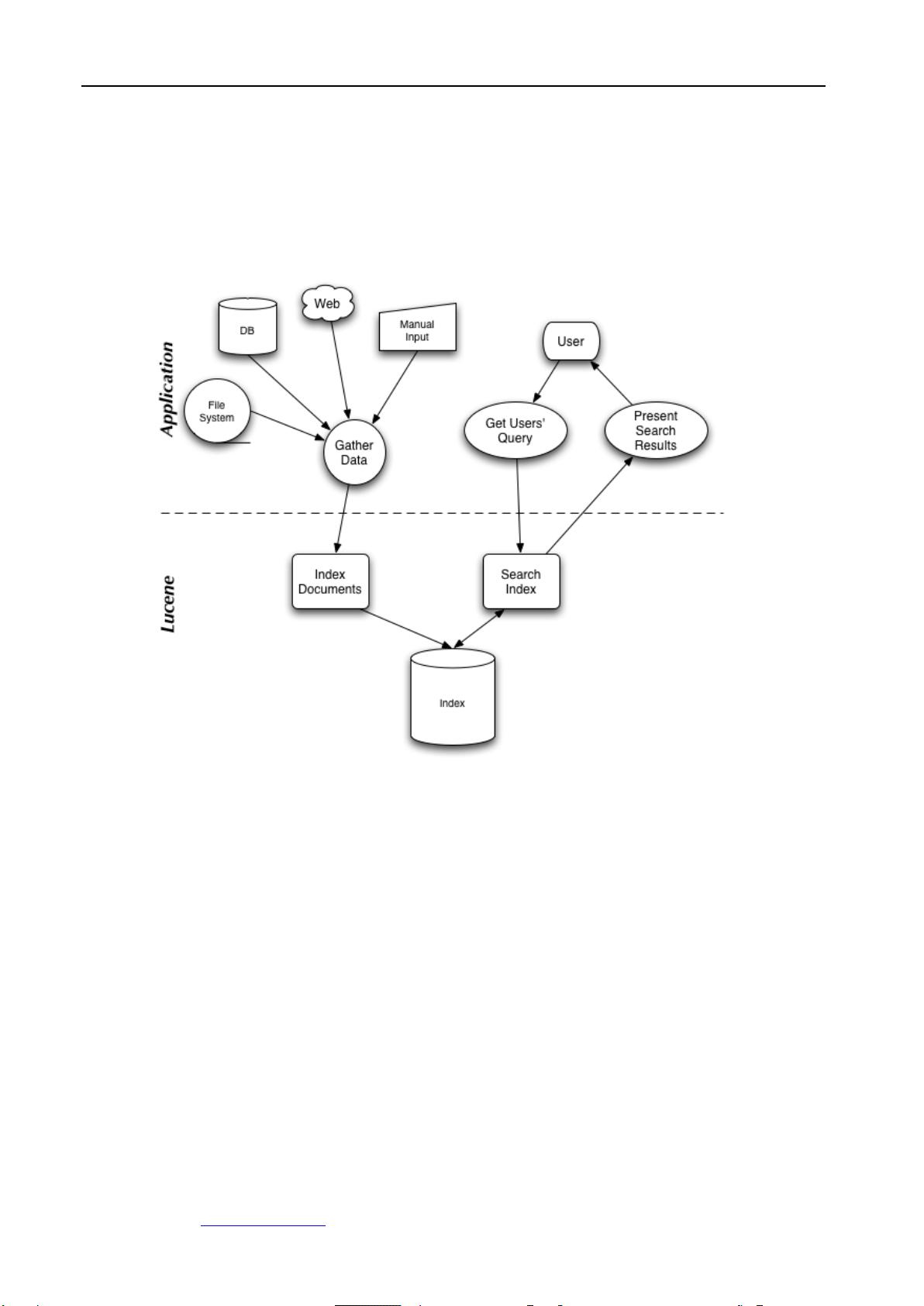
Annotated Lucene 作者:naven
1 目录
Annotated Lucene(源码剖析中文版) ......................................................................................................... - 1 -
1 目录 ............................................................................................................................................................. - 1 -
2 Lucene 是什么 ............................................................................................................................................ - 3 -
2.1.1 强大特性 ............................................................................................................................. - 3 -
2.1.2 API 组成 .............................................................................................................................. - 4 -
2.1.3 Hello World! ..................................................................................................................... - 5 -
2.1.4 Lucene roadmap ................................................................................................................. - 6 -
3 索引文件结构 ............................................................................................................................................. - 7 -
3.1 索引数据术语和约定 ................................................................................................................. - 7 -
3.1.1 术语定义 ............................................................................................................................. - 7 -
3.1.2 倒排索引(inverted indexing) .................................................................................... - 8 -
3.1.3 Fields 的种类 .................................................................................................................... - 8 -
3.1.4 片断(segments) ............................................................................................................. - 8 -
3.1.5 文档编号(document numbers) ...................................................................................... - 9 -
3.1.6 索引结构概述 ..................................................................................................................... - 9 -
3.1.7 索引文件中定义的数据类型 ........................................................................................... - 10 -
3.2 索引文件结构 ........................................................................................................................... - 10 -
3.2.1 索引文件概述 ................................................................................................................... - 10 -
3.2.2 每个 Index 包含的文件 ................................................................................................... - 11 -
3.2.2.1 Segments 文件 ........................................................................................................ - 11 -
3.2.2.2 Lock 文件 ................................................................................................................ - 14 -
3.2.2.3 Deletable 文件 ...................................................................................................... - 14 -
3.2.2.4 Compound 文件(.cfs)......................................................................................... - 14 -
3.2.3 每个 Segment 包含的文件 ............................................................................................... - 15 -
3.2.3.1 Field 信息(.fnm) .............................................................................................. - 15 -
3.2.3.2 Field 数据(.fdx 和.fdt).................................................................................. - 16 -
3.2.3.3 Term 字典(.tii 和.tis) .................................................................................... - 18 -
3.2.3.4 Term 频率数据(.frq)......................................................................................... - 21 -
3.2.3.5 Positions 位置信息数据(.prx) ....................................................................... - 23 -
3.2.3.6 Norms 调节因子文件(.nrm) ............................................................................... - 24 -
3.2.3.7 Term 向量文件 ........................................................................................................ - 25 -
3.2.3.8 删除的文档 (.del)........................................................................................... - 28 -
3.3 局限性(Limitations) ............................................................................................................. - 29 -
4 索引是如何创建的 ................................................................................................................................... - 30 -
4.1 索引创建示例 ........................................................................................................................... - 30 -



剩余52页未读,继续阅读

nicky_zs
- 粉丝: 138
- 资源: 81









最新资源
- Magica Cloth 2 V 2.13布料模拟插件
- 基于SpringBoot的在线考试系统源代码全套技术资料.zip
- 运行在PostgreSQL中的AdventureWorks示例数据库
- 最新女神大秀直播间打赏视频付费观看网站源码 自带直播数据
- 客户购物 (最新趋势) 数据集
- 配电网优化模型matlab 考虑可转移负荷、中断负荷以及储能、分布式能源的33节点系统优化模型,采用改进麻雀搜索算法,以IEEE33节点为例,以风电运维成本、网损成本等为目标,得到系统优化结果,一共有
- MATLAB代码:基于条件风险价值的合作型Stackerlberg博弈微网动态定价与优化调度 关键词:微网优化调度 条件风险价值 合作博弈 纳什谈判 参考文档:A cooperative Stack
- 述职报告PPT模板及样例文章
- MATLAB代码:基于分布式优化的多产消者非合作博弈能量共享 关键词:分布式优化 产消者 非合作博弈 能量共享 仿真平台: matlab 主要内容:为了使光伏用户群内各经济主体能实现有序的电能交易
- 学生抑郁数据集-可以用于分析学生的心理健康趋势
- CRUISE纯电动车双电机四驱仿真模型,基于simulink DLL联合仿真模型,实现前后电机效率最优及稳定性分配 关于模型: 1.策略是用64位软件编译的,如果模型运行不了请将软件切成64位 切
- Android程序开发初级教程WORD文档doc格式最新版本
- cruise混动仿真,P2并联混动仿真模型,Cruise混动仿真模型,可实现并联混动汽车动力性经济性仿真 关于模型 1.模型是基于cruise simulink搭建的base模型,策略模型基于MAT
- HCIP 复习内容实验 ia
- BGP路由协议模拟器,网络路由条目实时监控
- MATLAB代码:含多种需求响应及电动汽车的微网 电厂日前优化调度 关键词:需求响应 空调负荷 电动汽车 微网优化调度 电厂调度 仿真平台:MATLAB+CPLEX 主要内容:代码主要做的是一
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
前往页