
基于 Sharding-JDBC 分布式数据库培训方案
1 两个假设
假设一:当单表数据量爆炸时,你怎么办?
假设二:当数据库无法承受高强度 IO 时,你怎么办?
2 基本概念
分布式数据库是指利用高速计算机网络将物理上分散的多个数据存储单元连接起来组
成一个逻辑上统一的数据库。分布式数据库的基本思想是将原来集中式数据库中的数
据分散存储到多个通过网络连接的数据存储节点上,以获取更大的存储容量和更高的
并发访问量。
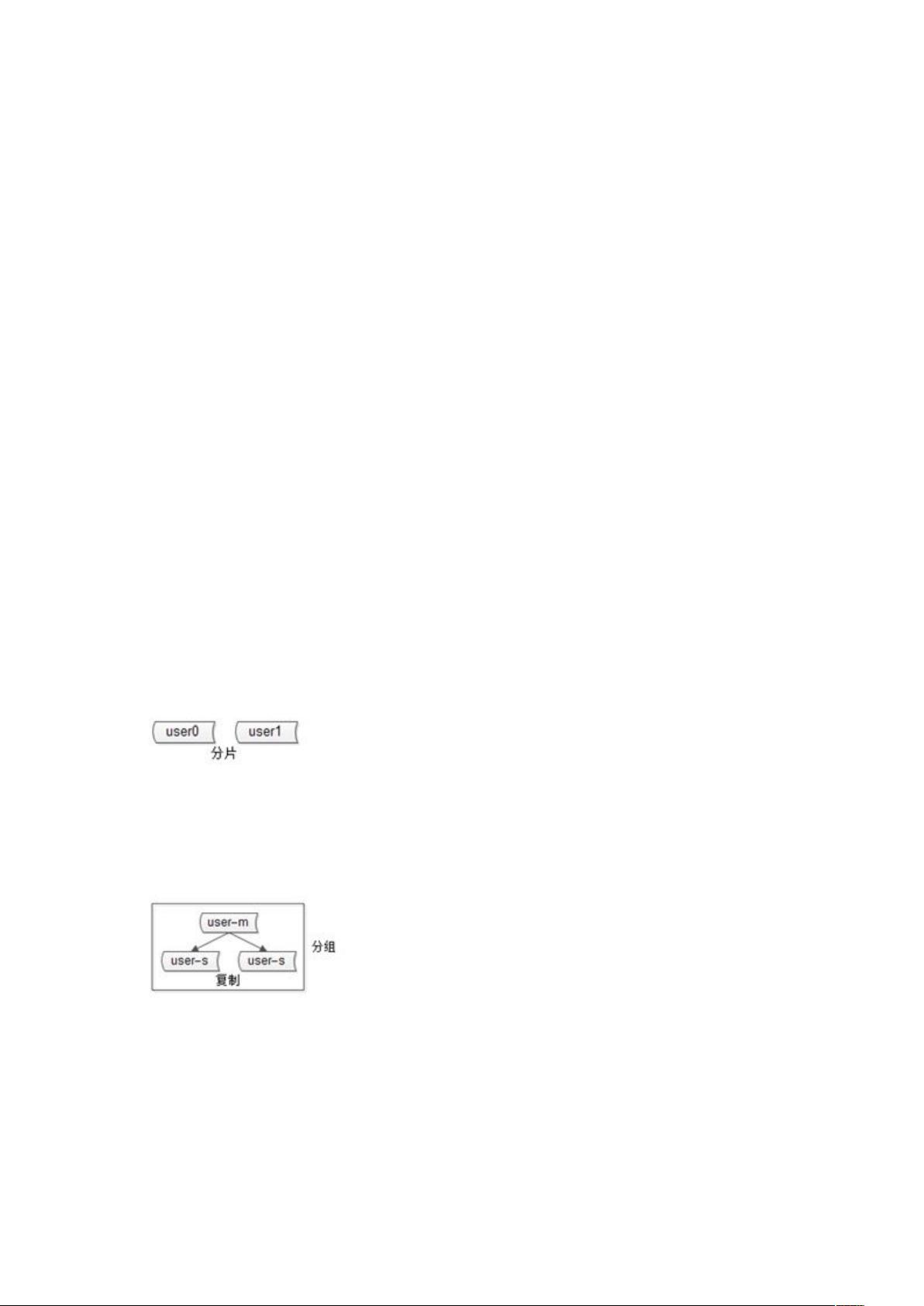
2.1 分片
分片解决扩展性问题,属于水平拆分,引入分片,就引入了数据路由和分区键的概念。
分表:解决数据量过大;
分库:解决数据性能瓶颈 IO;
2.2 分组
分组解决可用性问题,分组通常通过主从复制的方式实现。
2.3 读写分离
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据
库服务器,是对外提供增删改业务的生产服务器;第二台数据库服务器,主要进行读
的操作。
资源评论













