EfficientDet: Scalable and Efficient Object Detection
Mingxing Tan Ruoming Pang Quoc V. Le
Google Research, Brain Team
{tanmingxing, rpang, qvl}@google.com
Abstract
Model efficiency has become increasingly important in
computer vision. In this paper, we systematically study neu-
ral network architecture design choices for object detection
and propose several key optimizations to improve efficiency.
First, we propose a weighted bi-directional feature pyra-
mid network (BiFPN), which allows easy and fast multi-
scale feature fusion; Second, we propose a compound scal-
ing method that uniformly scales the resolution, depth, and
width for all backbone, feature network, and box/class pre-
diction networks at the same time. Based on these optimiza-
tions and better backbones, we have developed a new family
of object detectors, called EfficientDet, which consistently
achieve much better efficiency than prior art across a wide
spectrum of resource constraints. In particular, with single-
model and single-scale, our EfficientDet-D7 achieves state-
of-the-art 55.1 AP on COCO test-dev with 77M param-
eters and 410B FLOPs
1
, being 4x – 9x smaller and using
13x – 42x fewer FLOPs than previous detectors. Code is
available at https://github.com/google/automl/tree/
master/efficientdet.
1. Introduction
Tremendous progresses have been made in recent years
towards more accurate object detection; meanwhile, state-
of-the-art object detectors also become increasingly more
expensive. For example, the latest AmoebaNet-based NAS-
FPN detector [45] requires 167M parameters and 3045B
FLOPs (30x more than RetinaNet [24]) to achieve state-of-
the-art accuracy. The large model sizes and expensive com-
putation costs deter their deployment in many real-world
applications such as robotics and self-driving cars where
model size and latency are highly constrained. Given these
real-world resource constraints, model efficiency becomes
increasingly important for object detection.
There have been many previous works aiming to de-
velop more efficient detector architectures, such as one-
1
Similar to [14, 39], FLOPs denotes number of multiply-adds.
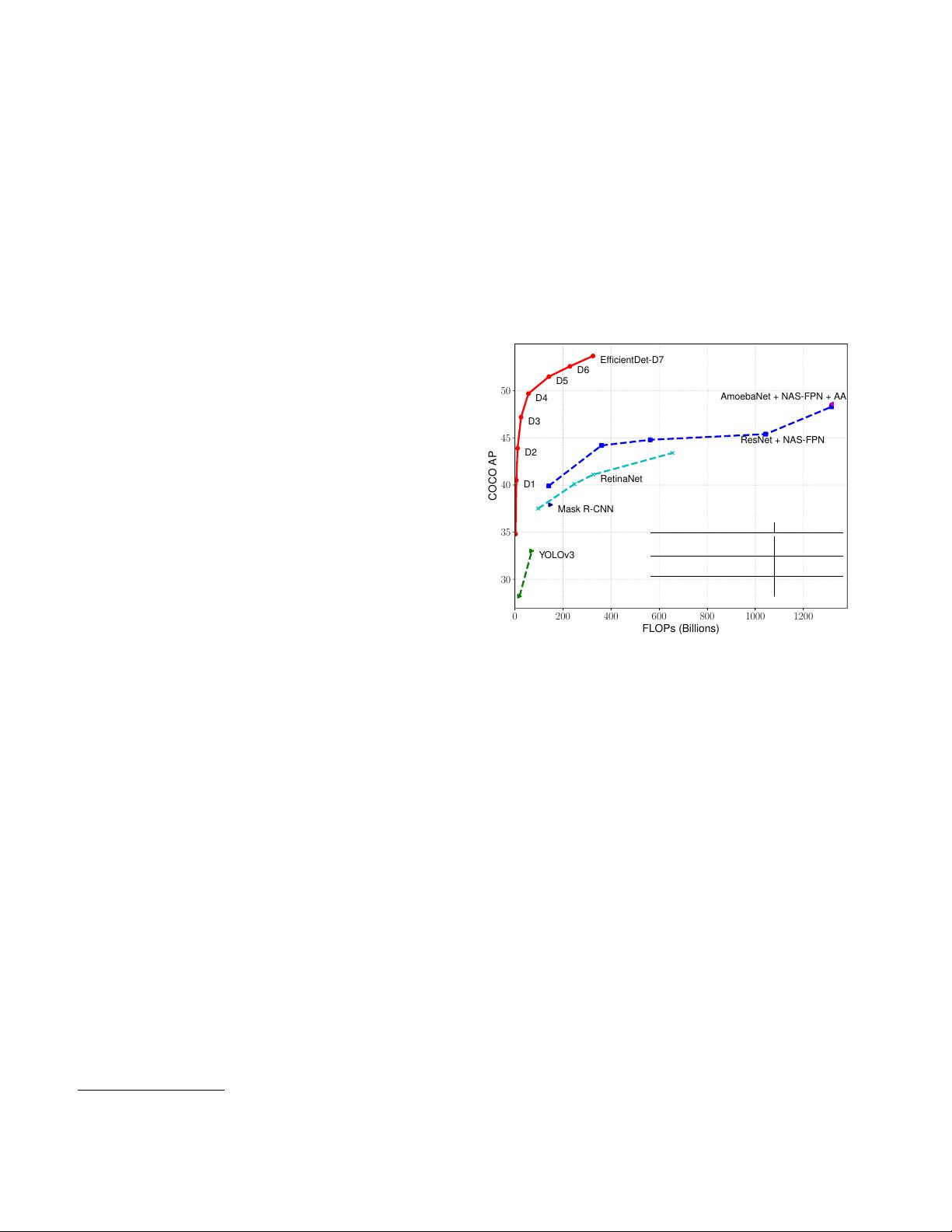
0 200 400 600 800 1000 1200
FLOPs (Billions)
30
35
40
45
50
COCO AP
D1
D5
EfficientDet-D7
D6
D2
D4
D3
YOLOv3
Mask R-CNN
RetinaNet
ResNet + NAS-FPN
AmoebaNet + NAS-FPN + AA
AP FLOPs (ratio)
EfficientDet-D0 33.8 2.5B
YOLOv3 [34] 33.0 71B (28x)
EfficientDet-D1 39.6 6.1B
RetinaNet [24] 39.2 97B (16x)
EfficientDet-D7x
†
55.1 410B
AmoebaNet+ NAS-FPN +AA [45]
†
50.7 3045B (13x)
†
Not plotted.
Figure 1: Model FLOPs vs. COCO accuracy – All num-
bers are for single-model single-scale. Our EfficientDet
achieves new state-of-the-art 55.1% COCO AP with much
fewer parameters and FLOPs than previous detectors. More
studies on different backbones and FPN/NAS-FPN/BiFPN
are in Table 4 and 5. Complete results are in Table 2.
stage [27, 33, 34, 24] and anchor-free detectors [21, 44, 40],
or compress existing models [28, 29]. Although these meth-
ods tend to achieve better efficiency, they usually sacrifice
accuracy. Moreover, most previous works only focus on a
specific or a small range of resource requirements, but the
variety of real-world applications, from mobile devices to
datacenters, often demand different resource constraints.
A natural question is: Is it possible to build a scal-
able detection architecture with both higher accuracy and
better efficiency across a wide spectrum of resource con-
straints (e.g., from 3B to 300B FLOPs)? This paper aims
to tackle this problem by systematically studying various
design choices of detector architectures. Based on the one-
stage detector paradigm, we examine the design choices for
backbone, feature fusion, and class/box network, and iden-
tify two main challenges:
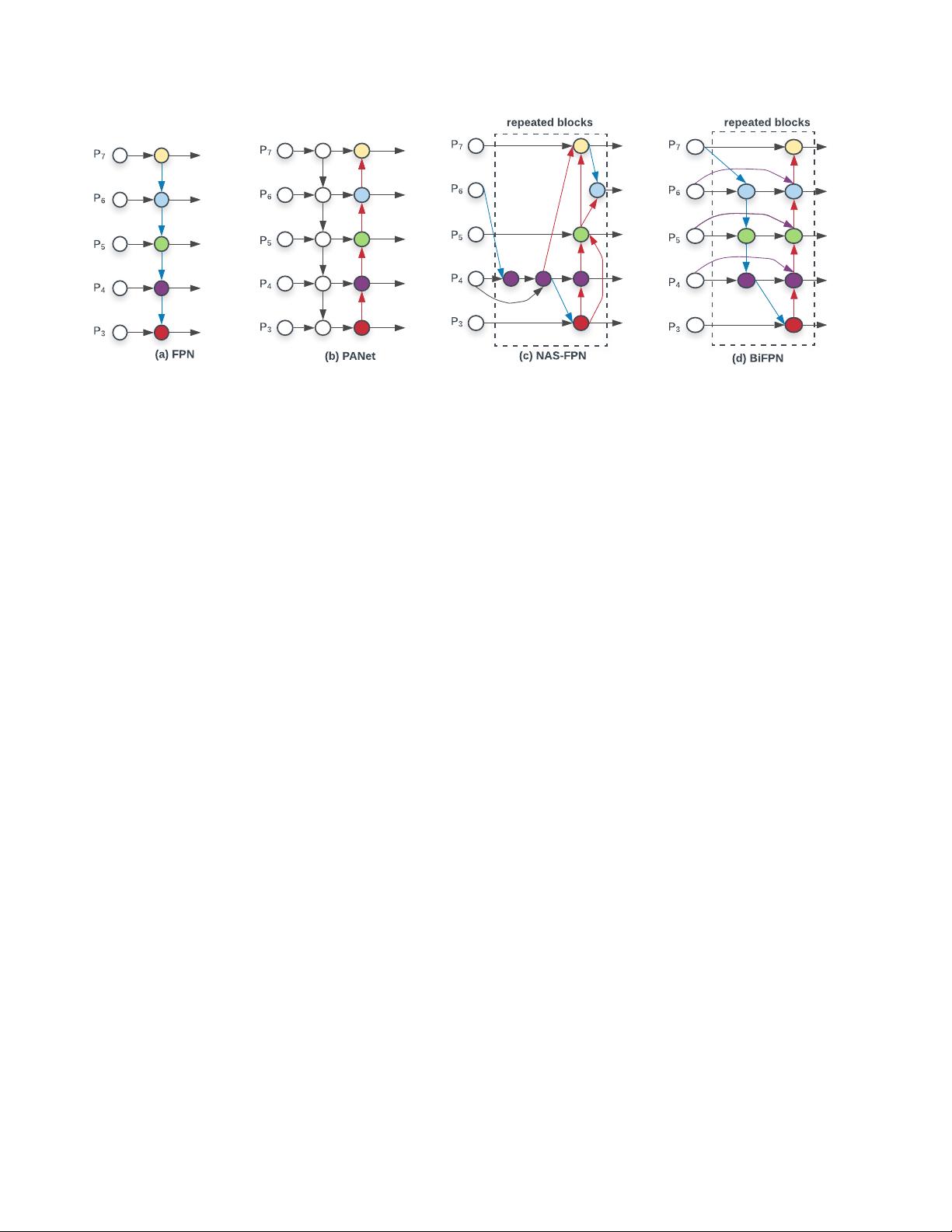
Challenge 1: efficient multi-scale feature fusion – Since
introduced in [23], FPN has been widely used for multi-
1
arXiv:1911.09070v7 [cs.CV] 27 Jul 2020