
Kafka 集群文档
一、入门
1、简介
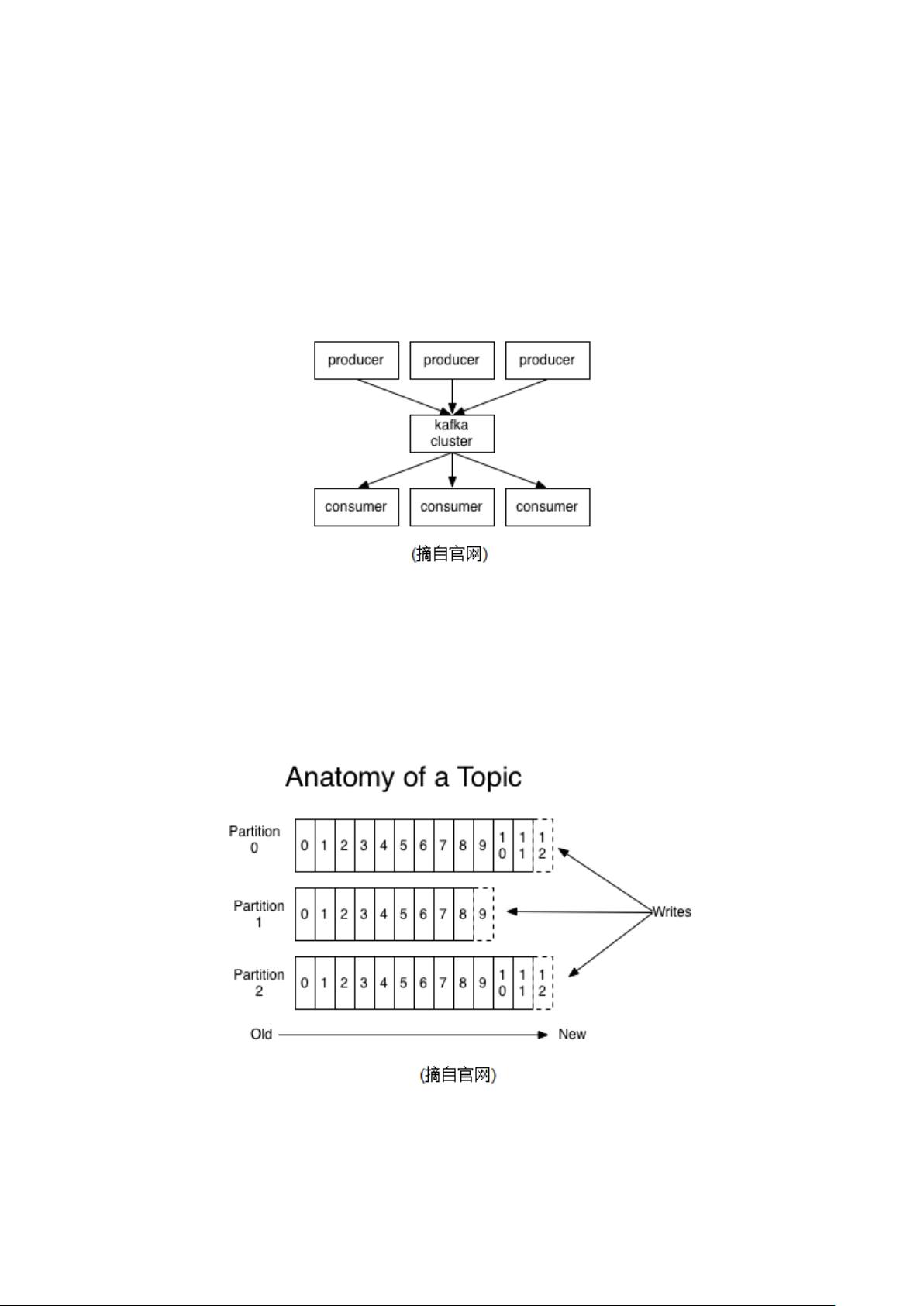
Kafka is a distributed,partitioned,replicated commit log service。它提供了类
似于 JMS 的特性,但是在设计实现上完全不同,此外它并不是 JMS 规范的实现。kafka 对消
息保存时根据 Topic 进行归类,发送消息者成为 Producer,消息接受者成为 Consumer,此外
kafka 集群有多个 kafka 实例组成,每个实例(server)成为 broker。无论是 kafka 集群,还
是 producer 和 consumer 都依赖于 zookeeper 来保证系统可用性集群保存一些 meta 信息。
2、Topics/logs
一个 Topic 可以认为是一类消息,每个 topic 将被分成多个 partition(区),每个
partition 在存储层面是 append log 文件。任何发布到此 partition 的消息都会被直接追
加到 log 文件的尾部,每条消息在文件中的位置称为 offset(偏移量),offset 为一个 long
型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka 并没有提供其他额外的索
引机制来存储 offset,因为在 kafka 中几乎不允许对消息进行“随机读写”。
kafka 和 JMS 实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日
志文件将会根据 broker 中的配置要求,保留一定的时间之后删除;比如 log 文件保留 2 天,
那么两天后,文件会被清除,无论其中的消息是否被消费.kafka 通过这种简单的手段,来释


剩余14页未读,继续阅读
资源评论


mcuppt
- 粉丝: 0
- 资源: 3









最新资源
- 【java毕业设计】智慧社区智慧共享资源搜索与推荐系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧共享资源分类管理系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧共享资源评价系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧会员等级与积分管理系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区活动报名与签到系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧会员活动中心管理系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区活动反馈与评价系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区留言板与回复系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区公告发布与查询系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区管理员日志审计系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区新闻资讯分类管理系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区管理员角色与权限管理系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区新闻资讯评论与点赞系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区智慧社区新闻资讯搜索与订阅系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区在线影院影片分类系统(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区在线影院观影记录与评分系统(源代码+论文+PPT模板).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


