SIMCA-P(System for Multivariate Analysis by Pattern Recognition,多变量分析模式识别系统)是一款由瑞典Umetrics公司开发的先进软件工具,用于多变量数据分析、建模和验证。该软件广泛应用于化学、生物工程、制药、食品科学和工程等领域,以帮助企业通过多元统计分析来优化生产流程、提升产品质量以及进行科学研究。
SIMCA-P软件提供了一个交互式的图形界面,可以方便地导入数据集,并运用主成分分析(PCA)、偏最小二乘法(PLS)、聚类分析等多种先进的统计方法进行数据处理。用户能够借助这一软件直观地了解数据结构,识别异常值,以及发现数据中的潜在模式和关联性。
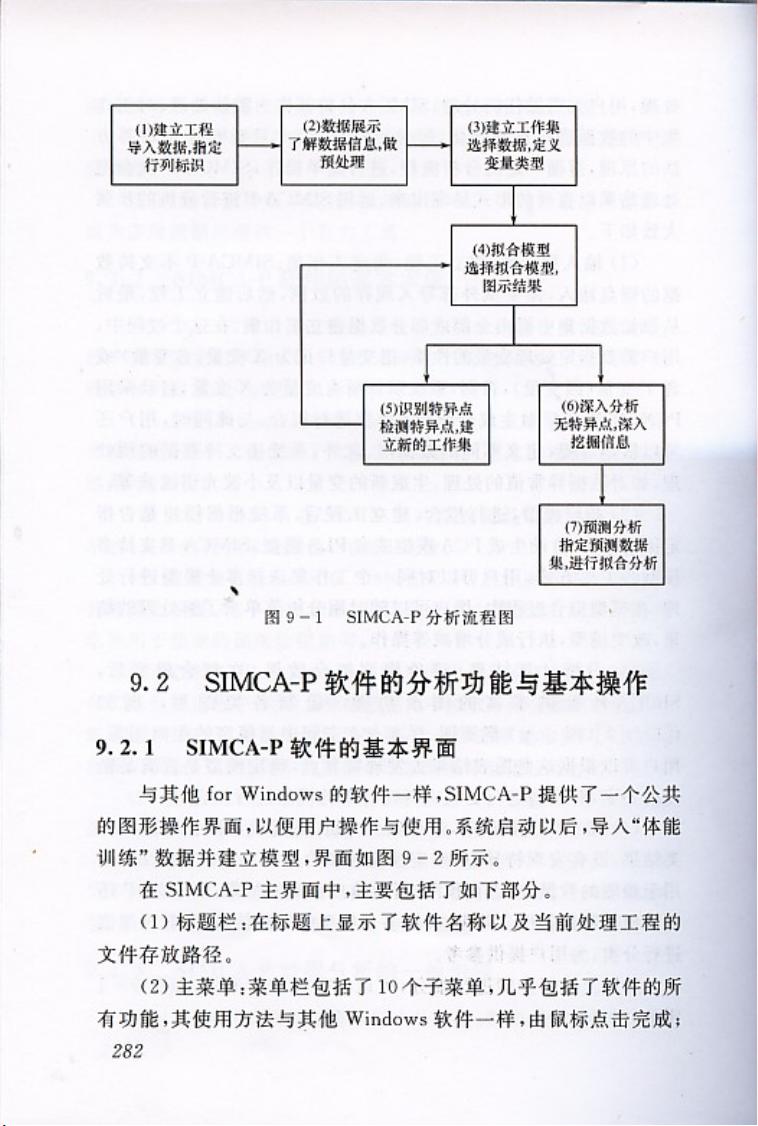
由于SIMCA-P软件功能强大,用户往往需要通过阅读使用说明来掌握软件的各项操作。本部分将尝试从软件的安装、数据导入、模型建立、结果分析和验证等方面详细阐述如何使用SIMCA-P软件进行多变量数据分析。
软件安装:
1. 在安装SIMCA-P之前,确保计算机满足最低配置要求,包括操作系统版本、处理器、内存和硬盘空间等。
2. 将安装介质或下载的安装文件运行,启动安装程序。
3. 根据安装向导提示选择安装路径和配置选项。
4. 完成安装后,进行软件激活或许可证注册,以获取完整的软件功能。
数据导入:
1. 打开SIMCA-P软件,选择“File”菜单中的“Import”选项,选择合适的文件格式来导入数据集。
2. 数据集通常需要以表格形式存在,例如CSV、Excel或特定的实验数据格式(如Jcamp-DX)。
3. 在导入过程中,需要指定数据的行列信息,如数据的分隔符、标题行、缺失值标记等。
4. 导入后,可以进行初步的数据浏览和预处理,包括数据清洗、筛选和转换等操作。
模型建立:
1. 选择合适的数据集后,通过“Model”菜单建立新的模型,常用的模型类型包括PCA、PLS等。
2. 在建立模型的过程中,需要选择合适的变量(X变量和Y变量),并对数据进行标准化和中心化等预处理。
3. 设置好模型参数后,启动模型训练过程,软件将进行迭代计算,直至收敛。
4. 模型建立完成后,需要进行模型质量评估,包括R²、Q²等统计指标的分析。
结果分析:
1. SIMCA-P提供了丰富的图表和图形用于展示分析结果,如得分图(Score Plot)、载荷图(Loading Plot)、变量重要性投影(VIP)等。
2. 用户可以通过分析这些图表来识别数据中的模式和趋势,理解变量之间的关系。
3. 对于异常值和离群点,可以通过模型诊断工具进行识别,并进一步分析其原因。
模型验证:
1. 模型验证是一个确保模型预测能力和泛化能力的重要步骤。
2. 可以通过交叉验证(如Venetian Blinds、Leave-One-Out等方法)来评估模型的稳健性。
3. 此外,还需要通过外部验证集来测试模型的预测准确性。
除了上述主要功能之外,SIMCA-P软件还包含了其他辅助工具和功能,如批量处理、脚本编写以及自定义报告等,这进一步扩展了软件的使用范围和灵活性。用户在学习和使用SIMCA-P的过程中,应该注意不断积累实际操作经验,结合专业知识,这样才能最大程度地发挥出软件的分析潜力。