vmware虚拟机下hadoop集群安装过程.docx
版权申诉
18 浏览量
2022-10-30
21:18:41
上传
评论
收藏 3.1MB DOCX 举报

vmware 虚拟机下 hadoop 集群安装过程
Hadoop 俗称分布式计算,最早作为一个开源项目,最初只是来源于谷歌的两份白皮书。
然而正如十年前的 Linux 一样,虽然 Hadoop 最初十分简单,但随着近些年来大数据的兴起,
其也获得了一个充分体现价值的舞台。这也正是业内普遍将Hadoop 看做是下一个 Linux 的
原因。
一.基于 vmware 的 hadoop 环境简述
本文介绍基于多台 vmware 虚拟机来安装 hadoop 集群的过程及方法,通过这个小的集
群让您在本地电脑上就可以研究 hadoop 的相关工作过程,有人会有疑问在小的虚拟机集群
上研究的结果, 写的程序能否在大集群上工作正常?可以肯定的没问题的。
Hadoop 的一个特性是线性增长特性,即当前数量情况下,处理时间是1, 若是数据量
加倍, 后处理时间加倍, 若是在这种情况下, 处理能力也加倍则处理时间也是 1.
正常情况 hadoop 需要较多的服务器才能搭建,但是我们在家里学习如何去找那么服务
器, 解决办法可以找几台 pc 机,在 pc 机上安装 linux 系统就可以了。
当然我们还有更简单的办法, 就是找一台高性能的电脑, 在电脑上安装虚拟机软件,
里面创建若干台虚拟机, 然后让这些虚拟机构成一个小的内部局域网络,在这个网络上我
们安装 linux 软件, java 软件, 安装 hadoop 程序,我们就可以创建一个简单 hadoop 的研
究系统, 进行软件的开发调试, 在这个小的分布式集群上开发的程序可以无缝移植到相同
版本的 hadoop(不同 hadoop 的版本兼容性不是很好, 特别是低版本同高版本, 他们的 api
也有些许变化)集群中。
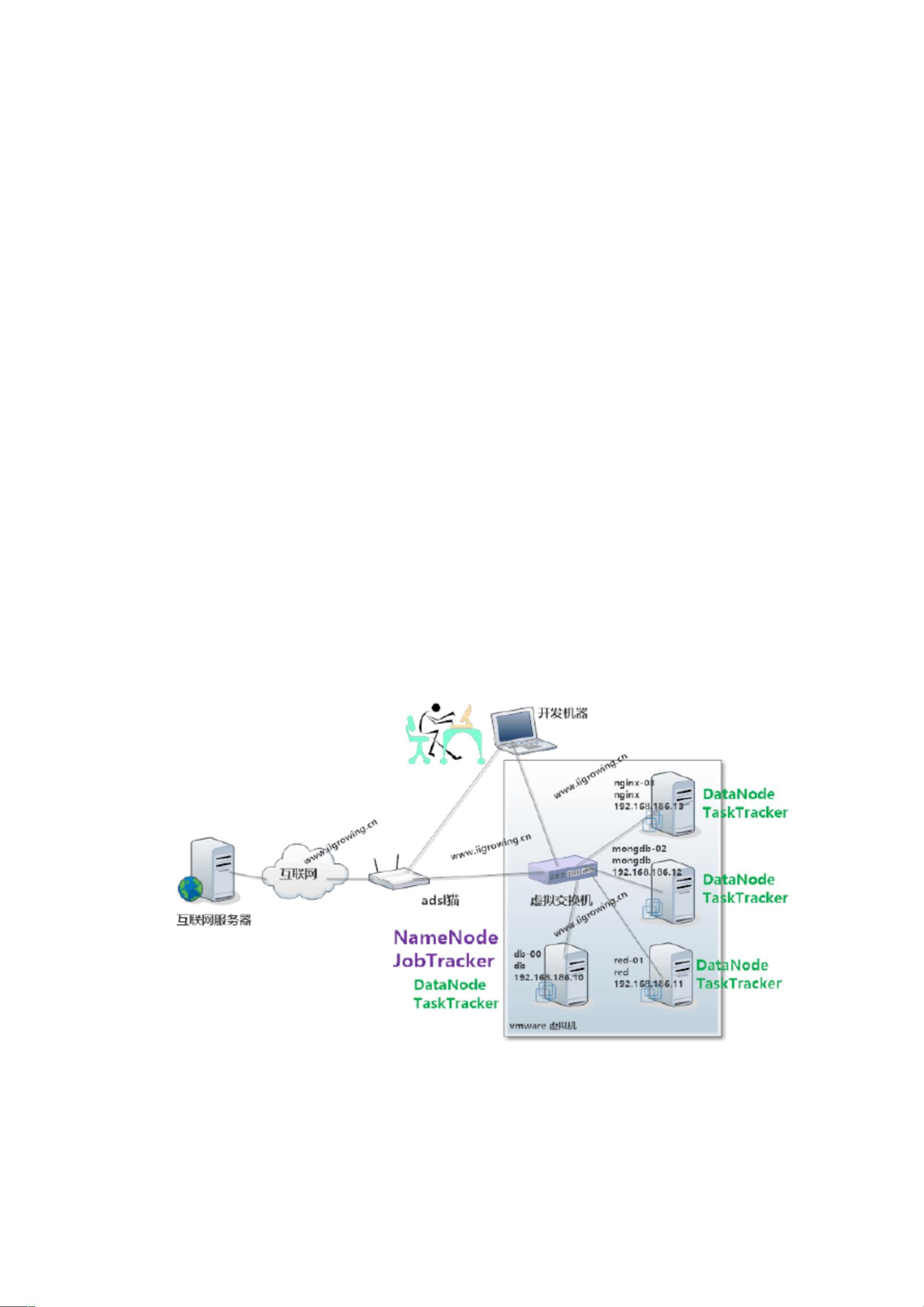
如下是在笔者笔记本上构建的一个 hadoop 的虚拟机系统, 相关网络拓扑结构如下:
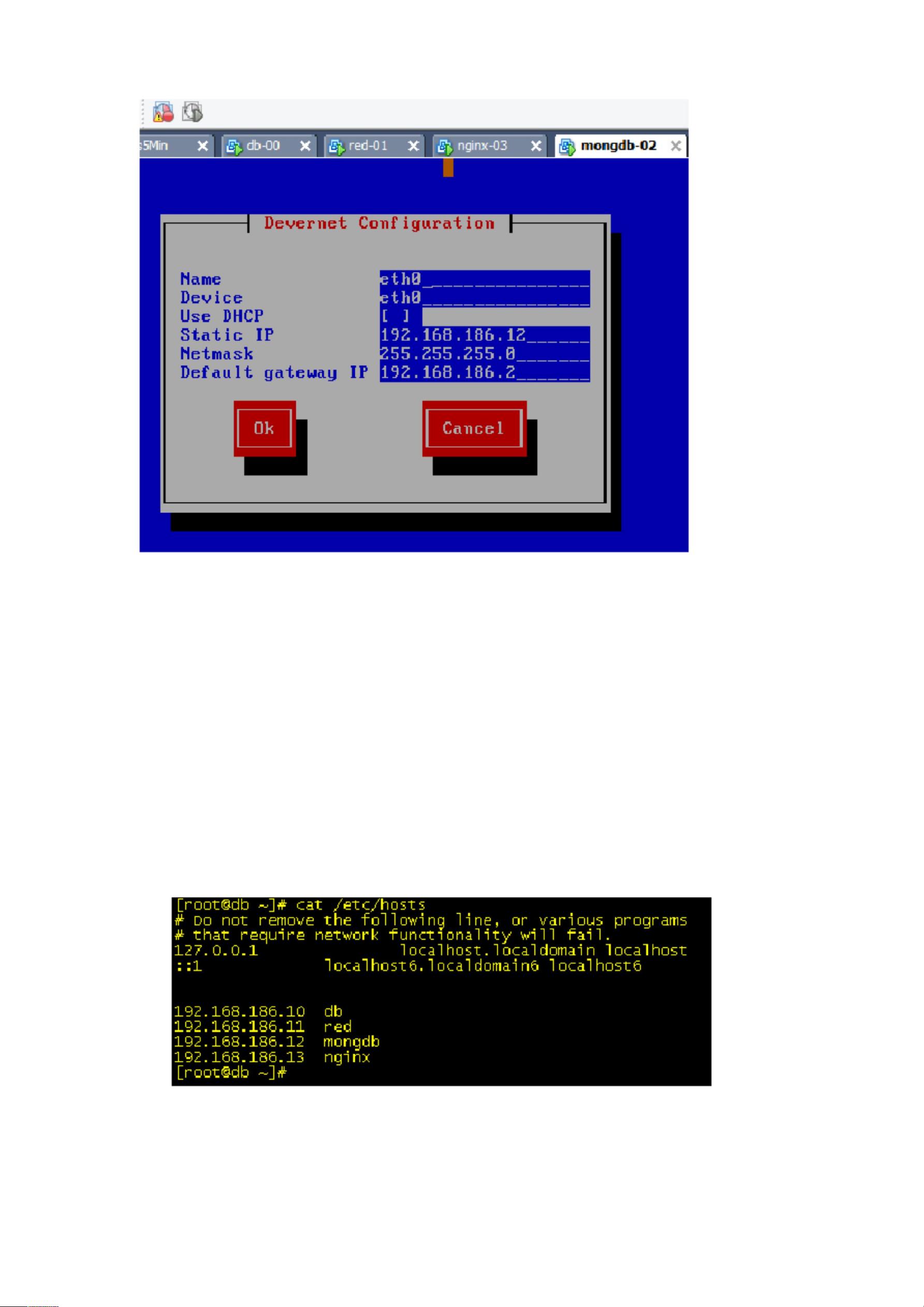
虚拟机 0,机器名称:db, ip:192.168.186.10
虚拟机 1,机器名称:red, ip:192.168.186.11
虚拟机 2,机器名称:mongdb, ip:192.168.186.12
虚拟机 3,机器名称:nginx,ip:192.168.186.13

剩余15页未读,继续阅读






评论0
最新资源