YOLO-CIANNA:在无线电数据中进行深度学习的星系检测 I. 一种受YOLO启发的新型源检测方法应用于SKAO SDC1
版权申诉
200 浏览量
2024-04-11
15:16:16
上传
评论
收藏 4.27MB PDF 举报


Astronomy & Astrophysics manuscript no. yolo_sdc1_paper ©ESO 2024
February 9, 2024
YOLO-CIANNA: Galaxy detection with deep learning in radio data
I. A new YOLO-inspired source detection method applied to the SKAO SDC1
D. Cornu
1
, P. Salomé
1
, B. Semelin
1
, A. Marchal
2, 3
, J. Freundlich
4
, S. Aicardi
5
,
X. Lu
6
, G. Sainton
1
, F. Mertens
1
, F. Combes
1, 7
, C. Tasse
8, 9
1
LERMA, Observatoire de Paris, PSL research Université, CNRS, Sorbonne Université, 75014, Paris, France
2
Canadian Institute for Theoretical Astrophysics, University of Toronto, 60 St. George Street, Toronto, ON M5S 3H8
3
Research School of Astronomy & Astrophysics, Australian National University, Canberra ACT 2610 Australia
4
Université de Strasbourg, CNRS UMR 7550, Observatoire astronomique de Strasbourg, 67000 Strasbourg, France
5
DIO, Observatoire de Paris, CNRS, PSL, 75014, Paris, France
6
IDRIS, CNRS, F-91403 Orsay, France
7
Collège de France, 11 Place Marcelin Berthelot, 75005, Paris, France
8
GEPI, Observatoire de Paris, CNRS, Université Paris Diderot, 5 Place Jules Janssen, 92190, Meudon, France
9
Department of Physics & Electronics, Rhodes University, PO Box 94, Grahamstown, 6140, South Africa
Received ..., ...; accepted ..., ...
ABSTRACT
Context. The upcoming Square Kilometer Array (SKA) will set a new standard regarding data volume generated by an astronomical
instrument, which is likely to challenge widely adopted data analysis tools that scale inadequately with the data size.
Aims. This study aims to develop a new source detection and characterization method for massive radio astronomical datasets by
adapting modern deep-learning object detection techniques. These approaches have proved their efficiency on complex computer
vision tasks, and we seek to identify their specific strengths and weaknesses when applied to astronomical data.
Methods. We introduce YOLO-CIANNA, a highly customized deep-learning object detector designed specifically for astronomical
datasets. This paper presents the method and describes all the low-level adaptations required to address the specific challenges of radio-
astronomical images. We demonstrate this method’s capabilities using simulated 2D continuum images from the SKA Observatory
(SKAO) Science Data Challenge 1 (SDC1) dataset.
Results. Our method outperforms every other published result on the specific SDC1 dataset. Using the SDC1 metric, we improve the
challenge-winning score by +139% and the score of the only other post-challenge participation by +61%. Our catalog has a detection
purity of 94% while detecting 40 to 60 % more sources than previous top-score results with a total of almost 680000 properly detected
sources. The trained model can also be forced to reach 99% purity in post-process and still detect 10 to 30% more sources than the
other top-score methods. Our method is efficient at low signal-to-noise ratio and exhibits strong characterization accuracy. It is also
capable of real-time detection, with a peak prediction speed of 500 images of 512×512 pixels per second on a single GPU.
Conclusions. YOLO-CIANNA achieves state-of-the-art detection and characterization results on the simulated SDC1 dataset. This is
encouraging regarding its potential capability over observational data from SKA precursors. The method is open source and included
in the wider CIANNA framework. We provide scripts to train and apply this method to the SDC1 dataset in the CIANNA repository.
Key words. Methods: numerical – Methods: statistical – Methods: data analysis – Galaxies: statistics – Radio continuum: galaxies
1. Introduction
Modern astronomical instruments generate ever-increasing data
volumes, following the need for better resolution, sensitivity,
and larger wavelength coverage. Astronomical datasets are often
highly dimensional and require precise encoding of the measure-
ments due to a high dynamic range. In addition, it is often nec-
essary to preserve the raw data due to iterative improvement of
the analysis pipelines. Radio-astronomy is strongly affected by
the explosion of data volumes, especially regarding giant radio
interferometers. In particular, the upcoming Square Kilometer
Array (SKA, Braun et al. 2019) is expected to have an unprece-
dented real-time data rate and to produce a remarkable amount
of stored science data products with around 700 PB of archived
data per year. This instrument is foreseen to have the necessary
sensitivity to set constraints on the cosmic dawn and the epoch
of reionization and to trace the evolution of astronomical objects
over cosmological times. With such volume and complexity of
data, some classical analysis methods and tools employed in ra-
dio astronomy for decades start to exhibit scaling limits.
In this context, the SKA Observatory (SKAO) started the
organization of recurrent Science Data Challenges (SDCs) to
gather astronomers from the international community around
simulated datasets that resemble future SKA data products. The
objective is to evaluate the suitability of existing analysis meth-
ods and encourage the development of new ones. It is also an
opportunity for astronomers to get familiar with the nature of
such datasets and to gain experience in their exploration.
The first edition, SDC1 (Bonaldi et al. 2021), focused on a
source detection and characterization task over simulated contin-
uum radio images at different frequencies and integration times.
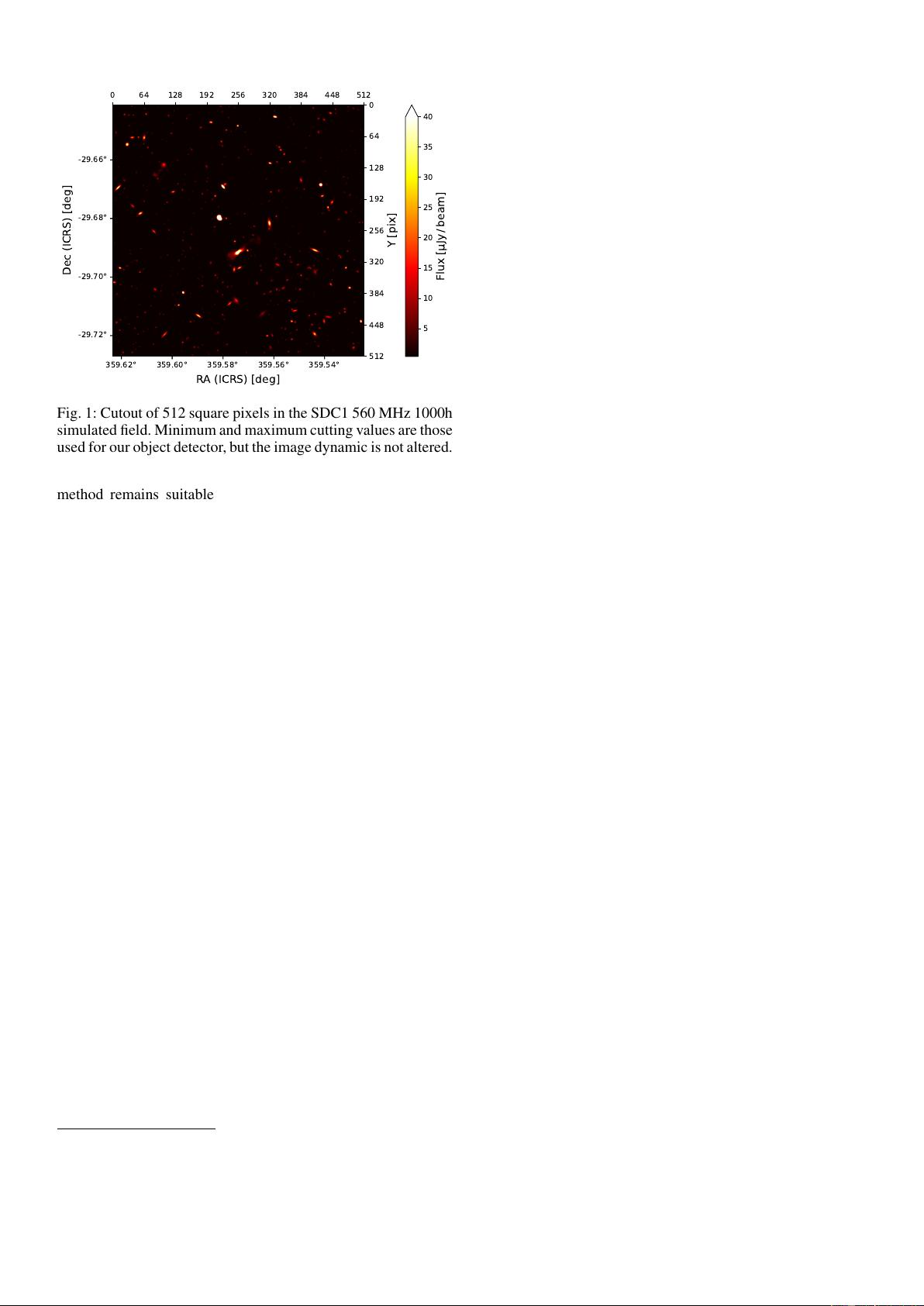
We show a cutout from one of the SDC1 images in Fig. 1, illus-
trating the source density and the high dynamical range. Source-
Article number, page 1 of 40
arXiv:2402.05925v1 [astro-ph.IM] 8 Feb 2024



剩余39页未读,继续阅读
资源评论



人工智能_SYBH
- 粉丝: 4w+
- 资源: 200









最新资源
- WS2-32.lib,在编译程序中可以链接使用
- 秒懂傅里叶变换matlab程序实现过程
- ZEND解密dezender12
- sony 索尼IMX334摄像头模组电路板AD版硬件PCB图(6层板).zip
- 基于flask和echarts融合交易策略的bitfinex可视化微服务.zip
- 包含了wvp-assist.tar wvp-talk.tar zlmediakit.tar .
- 3r4efgh53wgrf43tw
- 2024新版Java基础从入门到精通全套视频+资料下载
- Spring AI大模型视频教程+ChatGPT视频教程+OpenAI大模型视频教程(资料+视频教程)
- ABB工业机器人教程PDF版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


