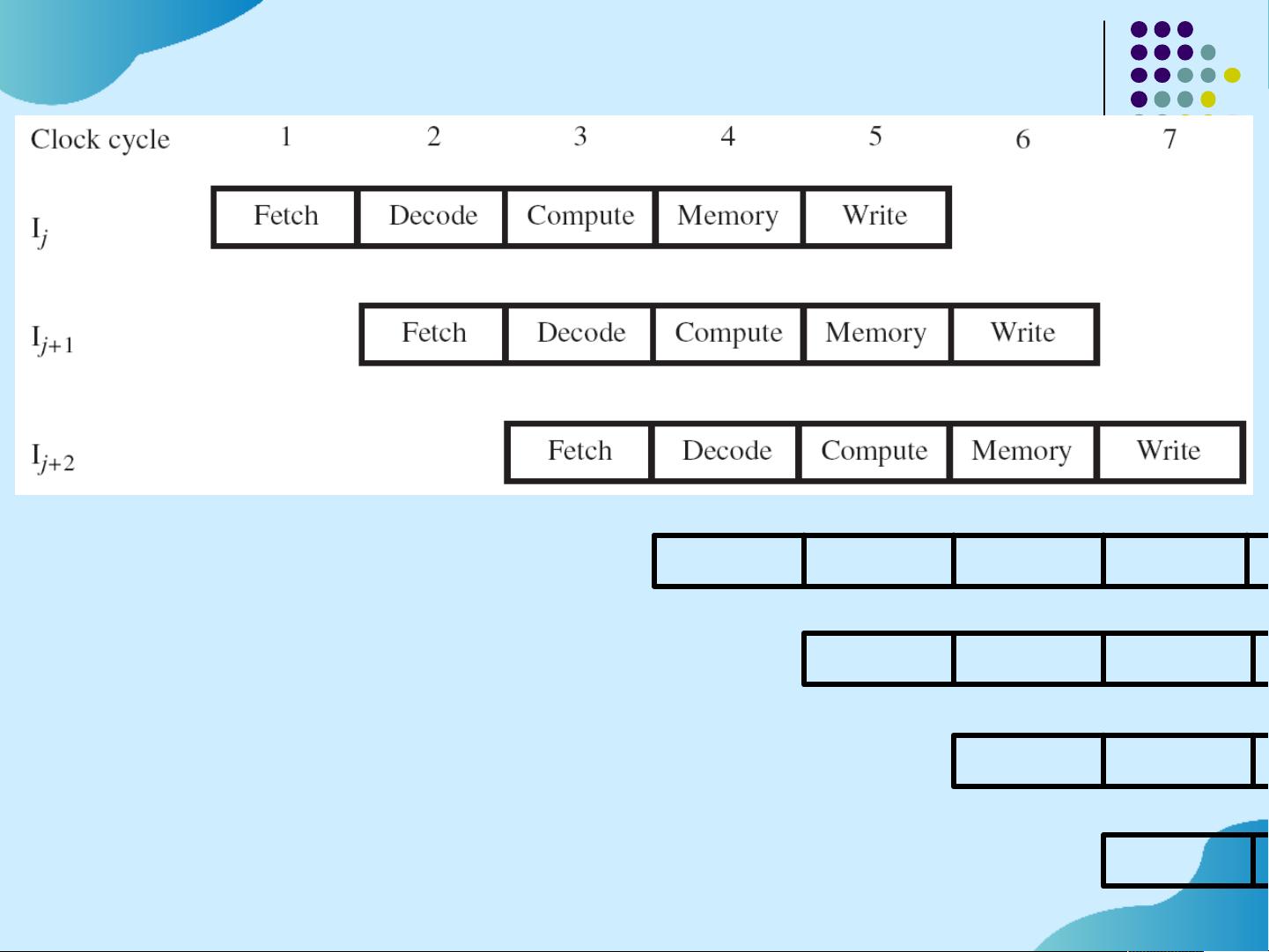
Pipelining in a Computer
Focus on pipelining ofinstruction execution.
Multistage datapath in Chapter 5 consists of:
Fetch, Decode, Compute, Memory, Write.
Instructions fetched & executed one at a time
with only one stage active in any cycle.
With pipelining, multiple stages are active
simultaneously for different instructions.
Still 5 cycles to execute one instruction, butrate
is 1 per cycle.
4