关系数据库设计理论是数据库设计的基础,它涉及到如何创建高效、无冗余且易于维护的数据模型。本章主要探讨了关系数据库设计中的一些关键概念和范式,这些理论有助于避免存储异常,如数据冗余、更新异常、插入异常和删除异常。
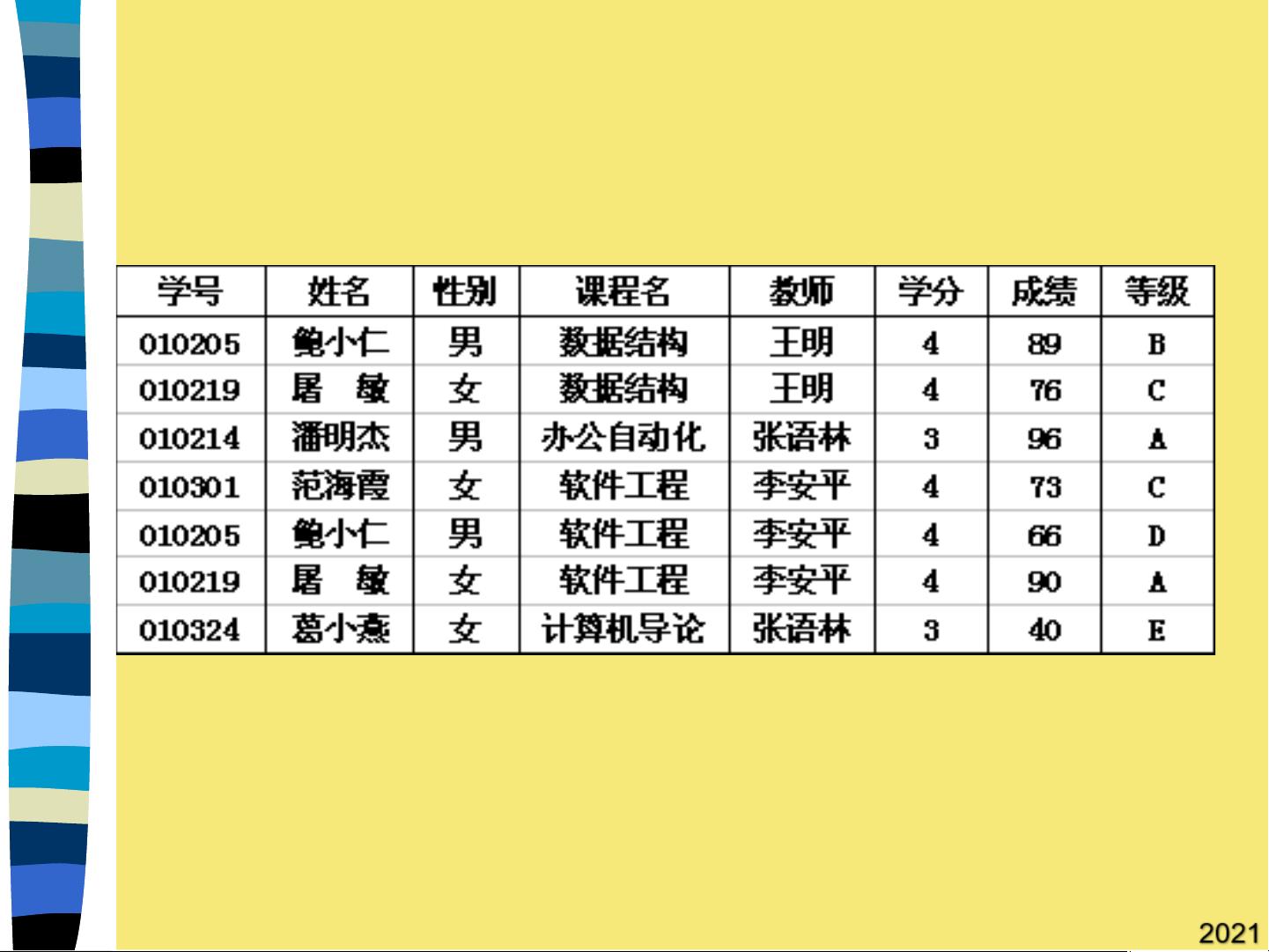
函数依赖是关系模型中的核心概念,它描述了一个属性(或属性集合)如何决定另一个属性。例如,在学生选课关系中,"课程名"可以决定"教师",记为"课程名→教师"。函数依赖分为完全函数依赖和部分函数依赖,前者是指Y完全依赖于X,后者则表示Y只部分依赖于X的一部分。例如,如果"(学号,课程名)"决定了"成绩",那么"课程名"就部分决定了"成绩"。
第一范式(1NF)要求关系中的每个字段都必须是不可分的原子值,避免了数据冗余。但仅满足1NF的关系模式仍可能出现问题,如更新异常,例如在含有"性别"和"姓名"的记录中,若只修改"性别"而没有同时修改"姓名",可能导致数据不一致。
第二范式(2NF)是在1NF基础上,要求每个非主属性完全依赖于整个主键,而不是主键的一部分。以"学号,课程名"为候选码的关系中,如果"学分"只依赖于"课程名",则不符合2NF,需要将关系分解为"学号,课程名,学分"和"学号,课程名,教师"两个关系。
第三范式(3NF)进一步要求每个非主属性不能传递依赖于主键,即不存在A→B→C的情况,其中A、B、C均为非主属性。例如,如果"(学号,课程名)"决定"等级",而"等级"又决定"成绩",那么"成绩"就传递依赖于"(学号,课程名)",此时应将"等级"和"成绩"独立出来。
在更高的规范形式中,有巴斯-科德范式(BCNF),它要求每个决定因素(决定其他属性的属性集合)都是候选码。这意味着任何属性都不能依赖于非候选码的非平凡函数依赖。例如,如果"科目"和"考生"是候选码,但"时间"也决定"考生",那么这个关系就不是BCNF,需要进一步分解。
通过理解并应用这些范式,我们可以设计出更合理的关系模型,从而提高数据库的性能和数据一致性。在实际操作中,数据库设计师通常会根据需求和性能考虑,选择合适的范式来规范化关系模式,以达到最优的数据结构。