自考 02331 数据结构重点总结(最终修订)
第一章 概论
1.瑞士计算机科学家沃思提出:算法+数据结构=程序。算法是对数据运算的描述,而数据结构包括逻辑结构和存储
结构.由此可见,程序设计的实质是针对实际问题选择一种好的数据结构和设计一个好的算法,而好的算法在很大程
度上取决于描述实际问题的数据结构。
2.数据是信息的载体。数据元素是数据的基本单位。一个数据元素可以由若干个数据项组成,数据项是具有独立含
义的最小标识单位。数据对象是具有相同性质的数据元素的集合.
3.数据结构指的是数据元素之间的相互关系,即数据的组织形式。
数据结构一般包括以下三方面内容:数据的逻辑结构、数据的存储结构、数据的运算
①数据的逻辑结构是从逻辑关系上描述数据,与数据元素的存储结构无关,是独立于计算机的。
数据的逻辑结构分类: 线性结构和非线性结构.
线性表是一个典型的线性结构。栈、队列、串等都是线性结构。数组、广义表、树和图等数据结构都是非线性结构。
②数据元素及其关系在计算机内的存储方式,称为数据的存储结构(物理结构)。
数据的存储结构是逻辑结构用计算机语言的实现,它依赖于计算机语言。
③数据的运算。最常用的检索、插入、删除、更新、排序等.
4.数据的四种基本存储方法: 顺序存储、链接存储、索引存储、散列存储
(1)顺序存储:通常借助程序设计语言的数组描述。
(2)链接存储:通常借助于程序语言的指针来描述。
(3)索引存储:索引表由若干索引项组成。关键字是能唯一标识一个元素的一个或多个数据项的组合。
(4)散列存储:该方法的基本思想是:根据元素的关键字直接计算出该元素的存储地址。
5。算法必须满足 5 个准则:输入,0 个或多个数据作为输入;输出,产生一个或多个输出;有穷性,算法执行有限步
后结束;确定性,每一条指令的含义都明确;可行性,算法是可行的。
算法与程序的区别:程序必须依赖于计算机程序语言,而一个算法可用自然语言、计算机程序语言、数学语言或约
定的符号语言来描述.目前常用的描述算法语言有两类:类 Pascal 和类 C。
6。评价算法的优劣:算法的"正确性”是首先要考虑的.此外,主要考虑如下三点:
① 执行算法所耗费的时间,即时间复杂性;
② 执行算法所耗费的存储空间,主要是辅助空间,即空间复杂性;
③ 算法应易于理解、易于编程,易于调试等,即可读性和可操作性。
以上几点最主要的是时间复杂性,时间复杂度常用渐进时间复杂度表示。
7。算法求解问题的输入量称为问题的规模,用一个正整数 n 表示.
8。常见的时间复杂度按数量级递增排列依次为:常数阶 0(1)、对数阶 0(log
2
n)、线性阶 0(n)、线性对数阶 0
(nlog
2
n)、平方阶 0(n
2
)立方阶 0(n
3
)、…、k 次方阶 0(n
k
)、指数阶 0(2
n
)和阶乘阶 0(n!)。
9.一个算法的空间复杂度 S(n)定义为该算法所耗费的存储空间,它是问题规模 n 的函数,它包括存储算法本身所
占的存储空间、算法的输入输出数据所占的存储空间和算法在运行过程中临时占用的存储空间。
第二章 线性表
1.数据的运算是定义在逻辑结构上的,而运算的具体实现是在存储结构上进行的。
2.只要确定了线性表存储的起始位置,线性表中任意一个元素都可随机存取,所以顺序表是一种随机存取结构.
3。常见的线性表的基本运算:
(1)置空表 InitList(L) 构造一个空的线性表 L。
(2)求表长 ListLength(L)求线性表 L 中的结点个数,即求表长.
(3)GetNode(L,i) 取线性表 L 中的第 i 个元素。(4)LocateNode(L,x)在 L 中查找第一个值为 x 的元素,并返
回该元素在 L 中的位置。若 L 中没有元素的值为 x ,则返回 0 值.
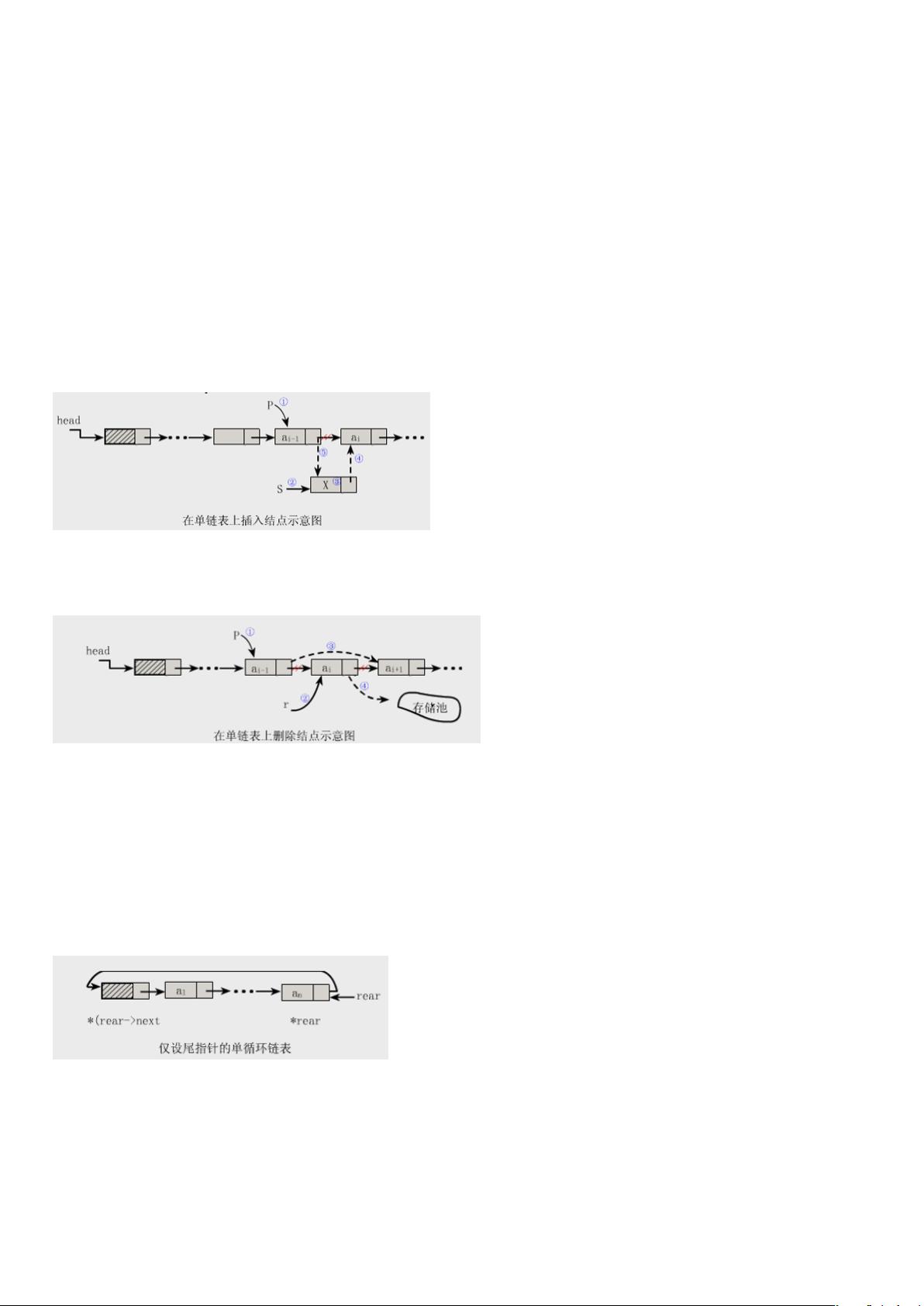
(5)InsertList(L,i,x)在线性表 L 的第 i 个元素之前插入一个值为 x 的新元素,表 L 的长度加 1。
(6)DeleteList(L,i)删除线性表 L 的第 i 个元素,删除后表 L 的长度减 1.
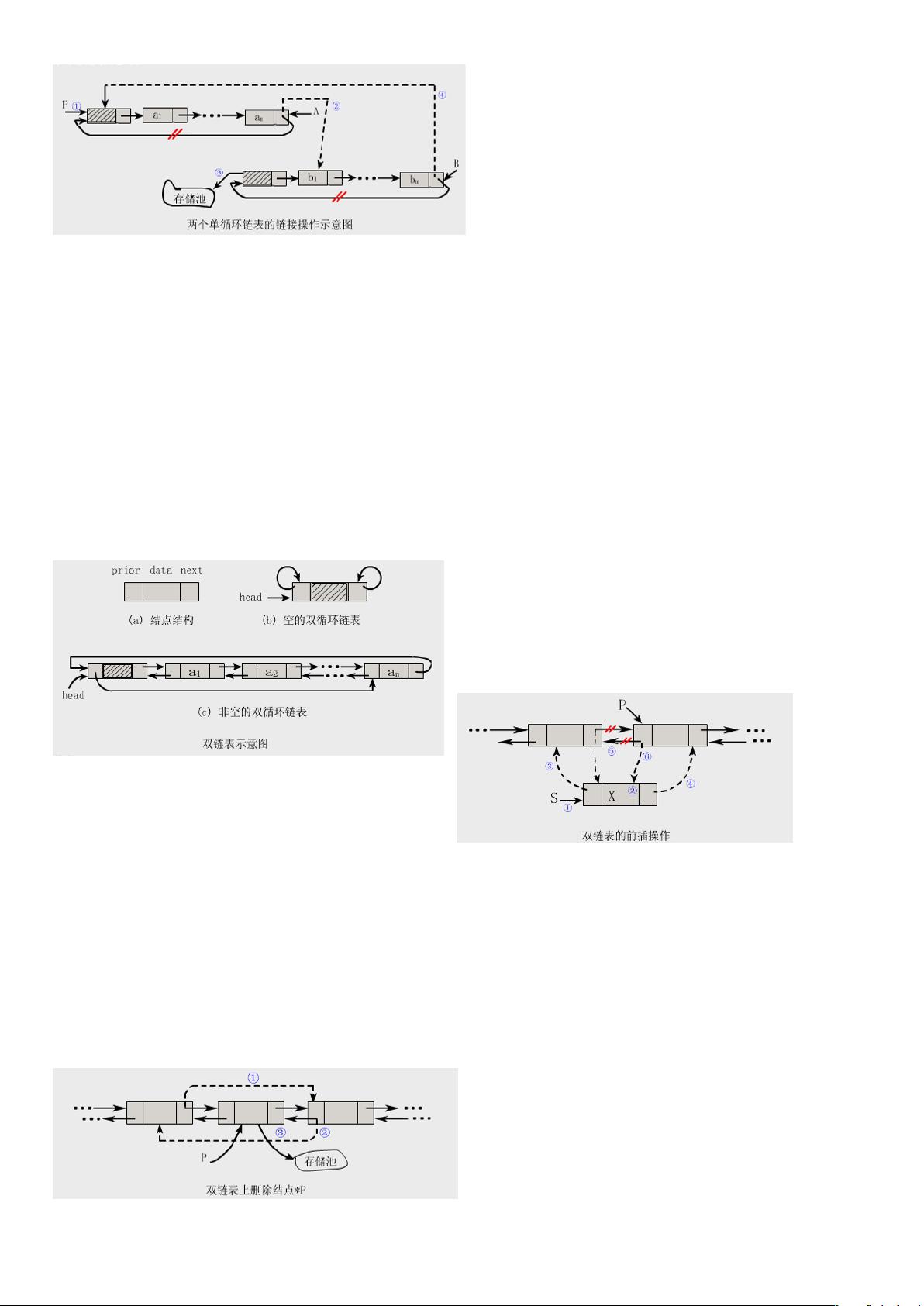
4.顺序存储方法:把线性表的数据元素按逻辑次序依次存放在一组地址连续的存储单元里的方法。
顺序表(Sequential List):用顺序存储方法存储的线性表称为顺序表。顺序表是一种随机存取结构,顺序表的
特点是逻辑上相邻的结点其物理位置亦相邻。
顺序表中结点 a
i
的存储地址: LOC(a
i
)= LOC(a
1
)+(i-1)*c 1≤i≤n,
5.顺序表上实现的基本运算: