
馃摎 This guide explains how to use **Weights & Biases** (W&B) with YOLOv5 馃殌. UPDATED 29 September 2021.
* [About Weights & Biases](#about-weights-&-biases)
* [First-Time Setup](#first-time-setup)
* [Viewing runs](#viewing-runs)
* [Disabling wandb](#disabling-wandb)
* [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
* [Reports: Share your work with the world!](#reports)
## About Weights & Biases
Think of [W&B](https://wandb.ai/site?utm_campaign=repo_yolo_wandbtutorial) like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models 鈥� architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
* [Debug](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Free-2) model performance in real time
* [GPU usage](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#System-4) visualized automatically
* [Custom charts](https://wandb.ai/wandb/customizable-charts/reports/Powerful-Custom-Charts-To-Debug-Model-Peformance--VmlldzoyNzY4ODI) for powerful, extensible visualization
* [Share insights](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Share-8) interactively with collaborators
* [Optimize hyperparameters](https://docs.wandb.com/sweeps) efficiently
* [Track](https://docs.wandb.com/artifacts) datasets, pipelines, and production models
## First-Time Setup
<details open>
<summary> Toggle Details </summary>
When you first train, W&B will prompt you to create a new account and will generate an **API key** for you. If you are an existing user you can retrieve your key from https://wandb.ai/authorize. This key is used to tell W&B where to log your data. You only need to supply your key once, and then it is remembered on the same device.
W&B will create a cloud **project** (default is 'YOLOv5') for your training runs, and each new training run will be provided a unique run **name** within that project as project/name. You can also manually set your project and run name as:
```shell
$ python train.py --project ... --name ...
```
YOLOv5 notebook example: <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
<img width="960" alt="Screen Shot 2021-09-29 at 10 23 13 PM" src="https://user-images.githubusercontent.com/26833433/135392431-1ab7920a-c49d-450a-b0b0-0c86ec86100e.png">
</details>
## Viewing Runs
<details open>
<summary> Toggle Details </summary>
Run information streams from your environment to the W&B cloud console as you train. This allows you to monitor and even cancel runs in <b>realtime</b> . All important information is logged:
* Training & Validation losses
* Metrics: Precision, Recall, mAP@0.5, mAP@0.5:0.95
* Learning Rate over time
* A bounding box debugging panel, showing the training progress over time
* GPU: Type, **GPU Utilization**, power, temperature, **CUDA memory usage**
* System: Disk I/0, CPU utilization, RAM memory usage
* Your trained model as W&B Artifact
* Environment: OS and Python types, Git repository and state, **training command**
<p align="center"><img width="900" alt="Weights & Biases dashboard" src="https://user-images.githubusercontent.com/26833433/135390767-c28b050f-8455-4004-adb0-3b730386e2b2.png"></p>
</details>
## Disabling wandb
* training after running `wandb disabled` inside that directory creates no wandb run
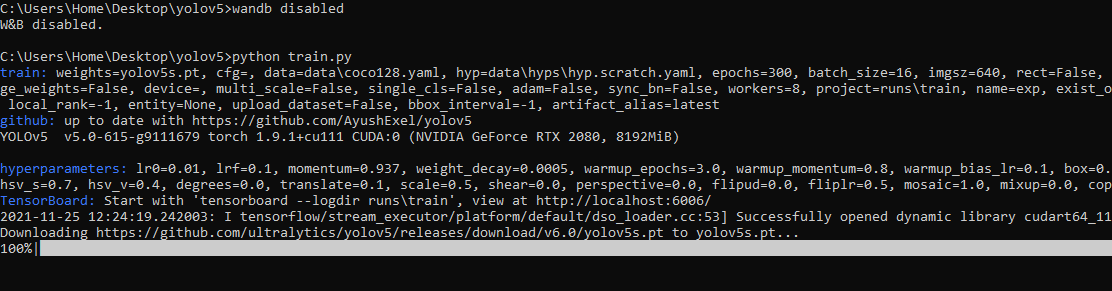
* To enable wandb again, run `wandb online`
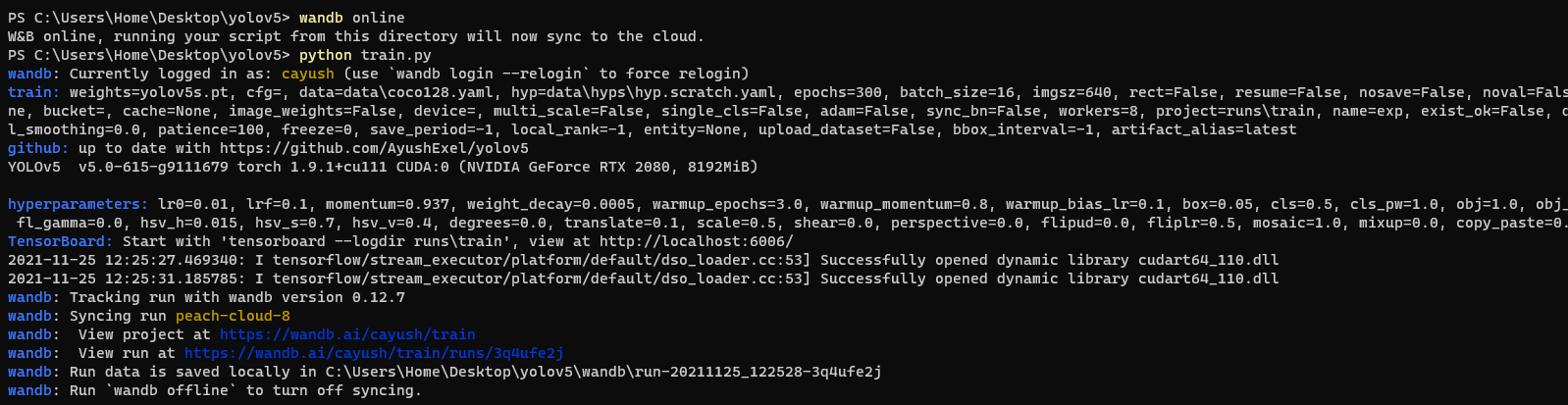
## Advanced Usage
You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
<details open>
<h3> 1: Train and Log Evaluation simultaneousy </h3>
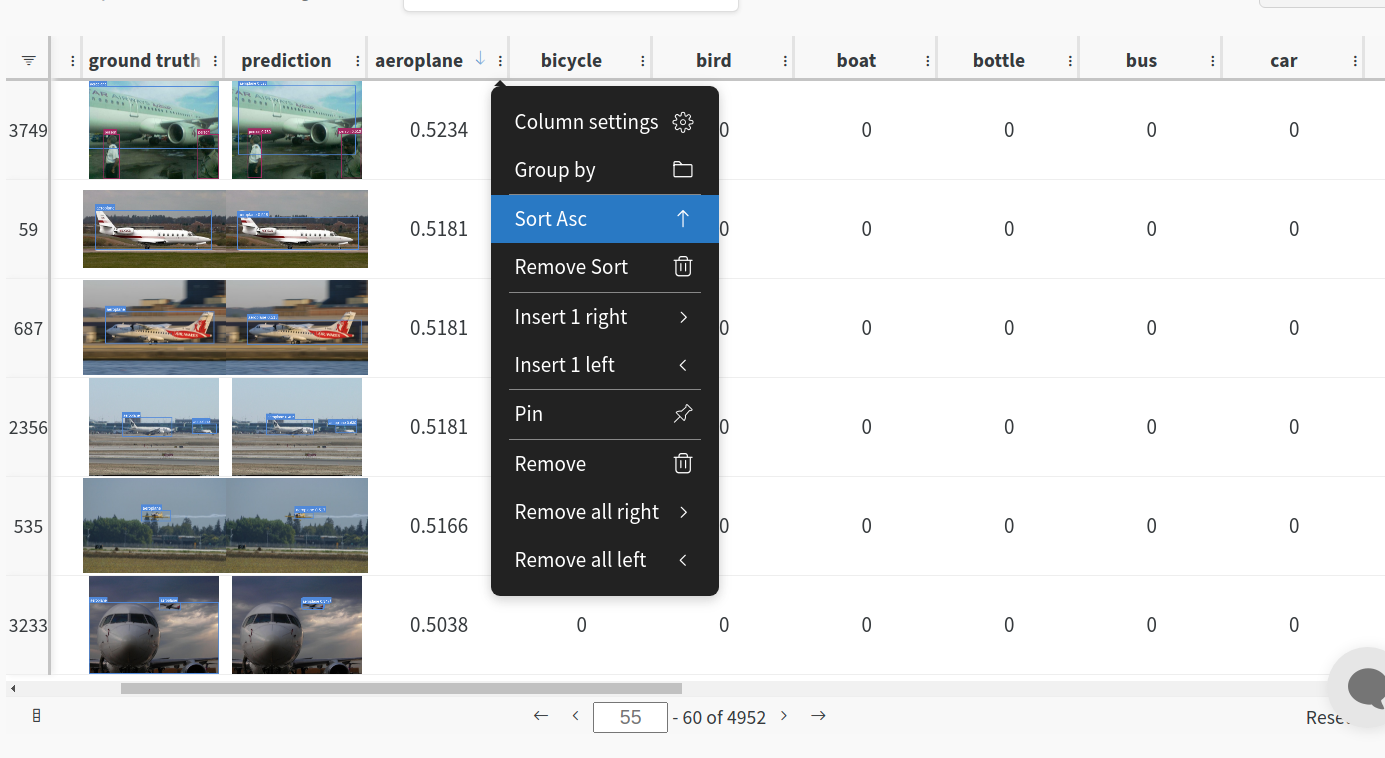
This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
so no images will be uploaded from your system more than once.
<details open>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --upload_data val</code>
</details>
<h3>2. Visualize and Version Datasets</h3>
Log, visualize, dynamically query, and understand your data with <a href='https://docs.wandb.ai/guides/data-vis/tables'>W&B Tables</a>. You can use the following command to log your dataset as a W&B Table. This will generate a <code>{dataset}_wandb.yaml</code> file which can be used to train from dataset artifact.
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data .. </code>

</details>
<h3> 3: Train using dataset artifact </h3>
When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that
can be used to train a model directly from the dataset artifact. <b> This also logs evaluation </b>
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --data {data}_wandb.yaml </code>

</details>
<h3> 4: Save model checkpoints as artifacts </h3>
To enable saving and versioning checkpoints of your experiment, pass `--save_period n` with the base cammand, where `n` represents checkpoint interval.
You can also log both the dataset and model checkpoints simultaneously. If not passed, only the final model will be logged
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --save_period 1 </code>

</details>
</details>
<h3> 5: Resume runs from checkpoint artifacts. </h3>
Any run can be resumed using artifacts if the <code>--resume</code> argument starts with聽<code>wandb-artifact://</code>聽prefix followed by the run path, i.e,聽<code>wandb-artifact://username/project/runid </code>. This doesn't require the model checkpoint to be present on the local system.
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --resume wandb-artifact://{run_path} </code>

</details>
<h3> 6: Resume runs from dataset artifact & checkpoint artifacts. </h3>
<b> Local dataset or model checkpoints are not required. This can be used to resume runs directly on a different device </b>
The syntax is same as the previous section, but you'll need to lof both the dataset and model checkpoints as artifacts, i.e, set bot <code>--upload_dataset<
 人工智能项目资料-基于Yolov5和DeepSORT算法.zip (217个子文件)
人工智能项目资料-基于Yolov5和DeepSORT算法.zip (217个子文件)  Dockerfile 821B Dockerfile 821B .gitignore 2KB .gitignore 2KB .gitignore 176B .gitignore 176B .gitkeep 0B .gitkeep 0B 校园车辆人流监控.iml 484B 校园车辆人流监控.iml 484B
Dockerfile 821B Dockerfile 821B .gitignore 2KB .gitignore 2KB .gitignore 176B .gitignore 176B .gitkeep 0B .gitkeep 0B 校园车辆人流监控.iml 484B 校园车辆人流监控.iml 484B train.jpg 59KB train.jpg 59KB README.md 11KB README.md 11KB README.md 2KB README.md 2KB README.md 986B README.md 65B README.md 65B
train.jpg 59KB train.jpg 59KB README.md 11KB README.md 11KB README.md 2KB README.md 2KB README.md 986B README.md 65B README.md 65B test.mp4 3.54MB test.mp4 3.54MB .name 7B .name 7B yolov5m.pt 40.82MB yolov5m.pt 40.82MB datasets.py 45KB datasets.py 45KB general.py 36KB general.py 36KB common.py 32KB common.py 32KB wandb_utils.py 27KB wandb_utils.py 27KB tf.py 20KB tf.py 20KB plots.py 20KB plots.py 20KB yolo.py 15KB yolo.py 15KB metrics.py 14KB metrics.py 14KB torch_utils.py 14KB torch_utils.py 14KB json_logger.py 11KB json_logger.py 11KB augmentations.py 11KB augmentations.py 11KB loss.py 9KB loss.py 9KB linear_assignment.py 8KB linear_assignment.py 8KB kalman_filter.py 8KB kalman_filter.py 8KB __init__.py 7KB __init__.py 7KB autoanchor.py 7KB autoanchor.py 7KB downloads.py 6KB downloads.py 6KB train.py 6KB train.py 6KB nn_matching.py 5KB nn_matching.py 5KB tracker.py 5KB tracker.py 5KB track.py 5KB track.py 5KB experimental.py 4KB experimental.py 4KB io.py 4KB io.py 4KB tracker.py 4KB tracker.py 4KB deep_sort.py 4KB deep_sort.py 4KB benchmarks.py 4KB benchmarks.py 4KB activations.py 4KB activations.py 4KB evaluation.py 3KB evaluation.py 3KB original_model.py 3KB original_model.py 3KB model.py 3KB model.py 3KB main.py 3KB main.py 3KB iou_matching.py 3KB iou_matching.py 3KB callbacks.py 2KB callbacks.py 2KB test.py 2KB test.py 2KB autobatch.py 2KB autobatch.py 2KB detector.py 2KB detector.py 2KB preprocessing.py 2KB preprocessing.py 2KB feature_extractor.py 2KB
test.mp4 3.54MB test.mp4 3.54MB .name 7B .name 7B yolov5m.pt 40.82MB yolov5m.pt 40.82MB datasets.py 45KB datasets.py 45KB general.py 36KB general.py 36KB common.py 32KB common.py 32KB wandb_utils.py 27KB wandb_utils.py 27KB tf.py 20KB tf.py 20KB plots.py 20KB plots.py 20KB yolo.py 15KB yolo.py 15KB metrics.py 14KB metrics.py 14KB torch_utils.py 14KB torch_utils.py 14KB json_logger.py 11KB json_logger.py 11KB augmentations.py 11KB augmentations.py 11KB loss.py 9KB loss.py 9KB linear_assignment.py 8KB linear_assignment.py 8KB kalman_filter.py 8KB kalman_filter.py 8KB __init__.py 7KB __init__.py 7KB autoanchor.py 7KB autoanchor.py 7KB downloads.py 6KB downloads.py 6KB train.py 6KB train.py 6KB nn_matching.py 5KB nn_matching.py 5KB tracker.py 5KB tracker.py 5KB track.py 5KB track.py 5KB experimental.py 4KB experimental.py 4KB io.py 4KB io.py 4KB tracker.py 4KB tracker.py 4KB deep_sort.py 4KB deep_sort.py 4KB benchmarks.py 4KB benchmarks.py 4KB activations.py 4KB activations.py 4KB evaluation.py 3KB evaluation.py 3KB original_model.py 3KB original_model.py 3KB model.py 3KB model.py 3KB main.py 3KB main.py 3KB iou_matching.py 3KB iou_matching.py 3KB callbacks.py 2KB callbacks.py 2KB test.py 2KB test.py 2KB autobatch.py 2KB autobatch.py 2KB detector.py 2KB detector.py 2KB preprocessing.py 2KB preprocessing.py 2KB feature_extractor.py 2KB共 217 条
- 1
- 2
- 3
资源评论



妄北y
- 粉丝: 2w+
- 资源: 1万+









最新资源
- 新年主题-3.花生采摘-猴哥666.py
- (6643228)词法分析器 vc 程序及报告
- mysql安装配置教程.txt
- 动手学深度学习(Pytorch版)笔记
- mysql安装配置教程.txt
- mysql安装配置教程.txt
- 彩页资料 配变智能环境综合监控系统2025.doc
- 棉花叶病害图像分类数据集5类别:健康的、蚜虫、粘虫、白粉病、斑点病(9000张图片).rar
- (176205830)编译原理 词法分析器 lex词法分析器
- 使用Python turtle库绘制哈尔滨亚冬会特色图像-含可运行代码及详细解释
- 2023年全国职业院校技能大赛GZ033大数据应用开发赛题答案(2).zip
- 【天风证券-2024研报-】水利部发布《对‘水利测雨雷达’的新质生产力研究》,重点推荐纳睿雷达.pdf
- 【国海证券-2024研报-】海外消费行业周更新:LVMH中国市场挑战严峻,泉峰控股发布盈喜.pdf
- 【招商期货-2024研报-】2024、25年度新疆棉花调研专题报告:北疆成本倒挂,南疆出现盘面利润.pdf
- 【宝城期货-2024研报-】宝城期货股指期货早报:IF、IH、IC、IM.pdf
- 【国元证券(香港)-2024研报-】即时点评:9月火电和风电增速加快,电力运营商盈利有望改善.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


