





在日常工作中你会从哪些维度进行 MySQL 性能优化呢?
所谓的性能优化,一般针对的是 MySQL 查询的优化。既然是优化查询,我们自然要先知道
查询操作要经过哪些环节,然后思考可以在哪些环节进行优化。
我用一张图展示查询操作需要经历的基本环节。
SQL 查询的环节
下面从 5 个角度介绍一下 MySQL 优化的一些策略。
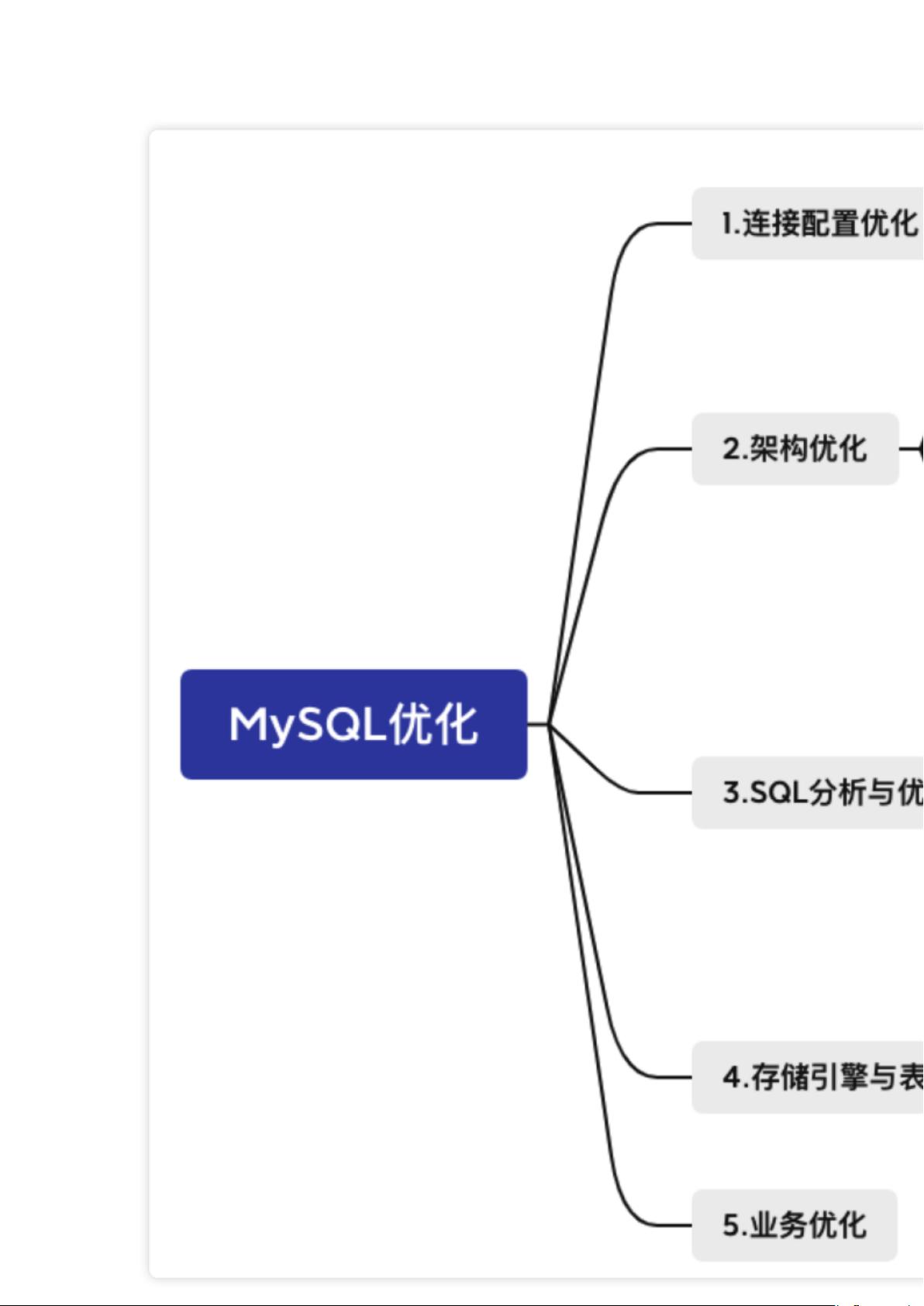

1. 连接配置优化
处理连接是 MySQL 客户端和 MySQL 服务端亲热的第一步,第一步都迈不好,也就别谈后
来的故事了。
既然连接是双方的事情,我们自然从服务端和客户端两个方面来进行优化喽。
1.1 服务端配置
服务端需要做的就是尽可能地多接受客户端的连接,或许你遇到过 error 1040: Too many
connections 的错误?就是服务端的胸怀不够宽广导致的,格局太小!
我们可以从两个方面解决连接数不够的问题:
. 增加可用连接数,修改环境变量 max_connections,默认情况下服务端的最大连接
数为 151 个
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+1 row in set (0.01 sec)
. 及时释放不活动的连接,系统默认的客户端超时时间是 28800 秒(8 小时),我们
可以把这个值调小一点
mysql> show variables like 'wait_timeout';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+1 row in set (0.01 sec)
MySQL 有非常多的配置参数,并且大部分参数都提供了默认值,默认值是
MySQL 作者经过精心设计的,完全可以满足大部分情况的需求,不建议在
不清楚参数含义的情况下贸然修改。
1.2 客户端优化
客户端能做的就是尽量减少和服务端建立连接的次数,已经建立的连接能凑合用就凑合用,
别每次执行个 SQL 语句都创建个新连接,服务端和客户端的资源都吃不消啊。
解决的方案就是使用连接池来复用连接。
常见的数据库连接池有 DBCP、C3P0、阿里的 Druid、Hikari,前两者用得很少了,后两
者目前如日中天。
但是需要注意的是连接池并不是越大越好,比如 Druid 的默认最大连接池大小是 8,Hikari
默认最大连接池大小是 10,盲目地加大连接池的大小,系统执行效率反而有可能降低。为
什么?
对于每一个连接,服务端会创建一个单独的线程去处理,连接数越多,服务端创建的线程自
然也就越多。而线程数超过 CPU 个数的情况下,CPU 势必要通过分配时间片的方式进行线
程的上下文切换,频繁的上下文切换会造成很大的性能开销。

Hikari 官方给出了一个 PostgreSQL 数据库连接池大小的建议值公式,CPU 核心数*2+1。
假设服务器的 CPU 核心数是 4,把连接池设置成 9 就可以了。这种公式在一定程度上对其
他数据库也是适用的,大家面试的时候可以吹一吹。
2. 架构优化
2.1 使用缓存
系统中难免会出现一些比较慢的查询,这些查询要么是数据量大,要么是查询复杂(关联的
表多或者是计算复杂),使得查询会长时间占用连接。
如果这种数据的实效性不是特别强(不是每时每刻都会变化,例如每日报表),我们可以把
此类数据放入缓存系统中,在数据的缓存有效期内,直接从缓存系统中获取数据,这样就可
以减轻数据库的压力并提升查询效率。
缓存的使用
2.2 读写分离(集群、主从复制)
项目的初期,数据库通常都是运行在一台服务器上的,用户的所有读写请求会直接作用到这
台数据库服务器,单台服务器承担的并发量毕竟是有限的。
针对这个问题,我们可以同时使用多台数据库服务器,将其中一台设置为为小组长,称之为
master 节点,其余节点作为组员,叫做 slave。用户写数据只往 master 节点写,而读的请
求分摊到各个 slave 节点上。这个方案叫做读写分离。给组长加上组员组成的小团体起个名
字,叫集群。













