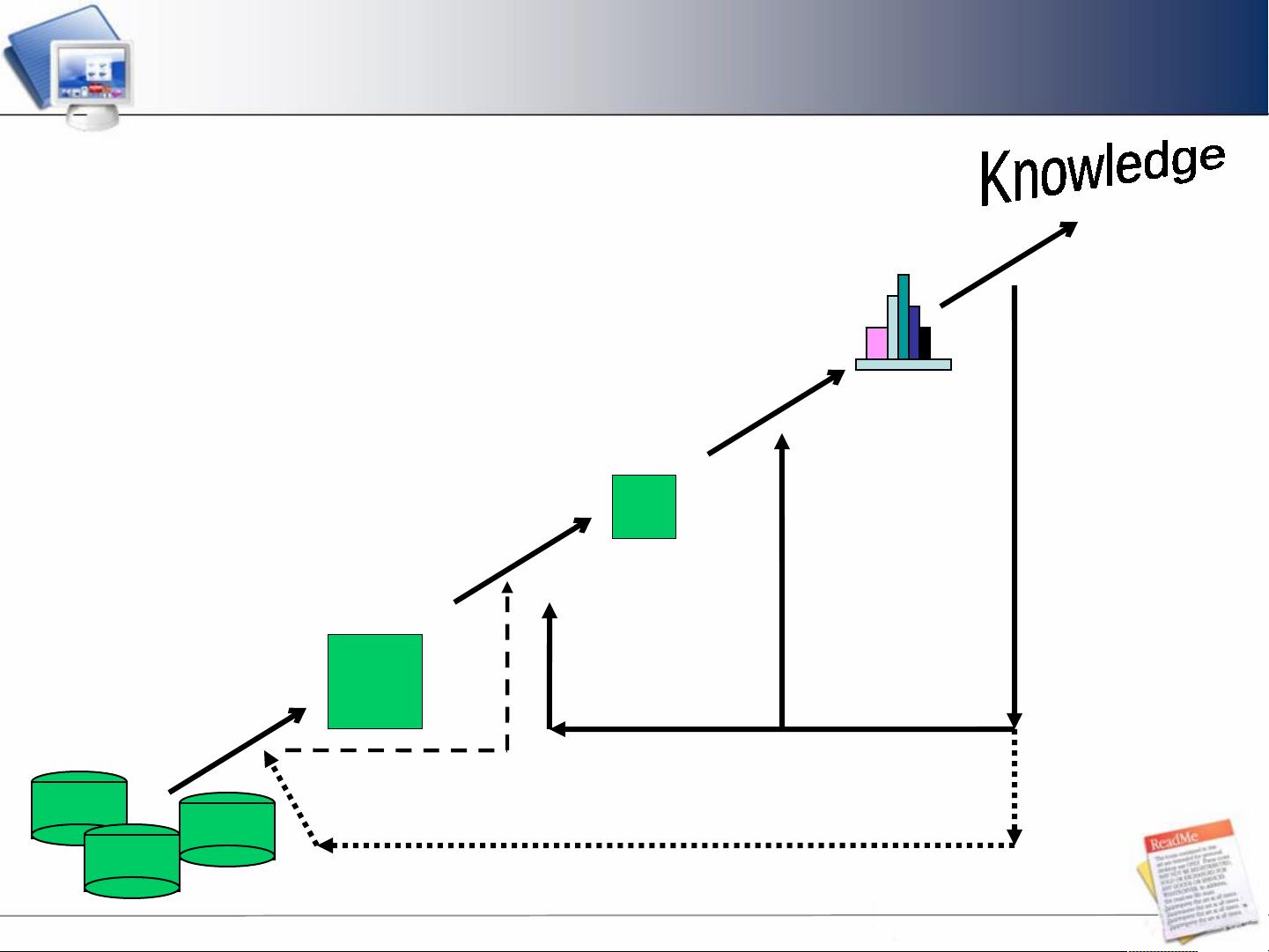
数据仓库与数据挖掘是现代信息技术领域中的重要概念,它们在大数据分析和决策支持中发挥着核心作用。数据仓库是为企业决策提供服务的大型集中式存储系统,它整合了来自多个异构源的数据,以支持复杂的分析和报表生成。数据挖掘则是从海量数据中发现有价值信息的过程,它利用各种算法和技术,如关联规则、分类、聚类和异常检测,从数据中抽取新知识。
数据仓库的发展主要源于数据爆炸的问题。随着自动化数据收集工具和成熟数据库技术的进步,大量数据被不断积累,但这些数据并未自动转化为有用的信息。因此,数据仓库技术应运而生,它提供了对历史数据的集中存储和高效访问,以支持在线分析处理(OLAP)。数据仓库的设计通常包括数据清理、集成、选择和转换,以确保数据质量并适应分析需求。
数据挖掘,又称为数据库中的知识发现(KDD),是一个多步骤的过程。这个过程涵盖了数据预处理、模式发现、评估和知识表示。数据清理是最重要的一步,大约占据了整个过程的60%工作量,它涉及消除噪声、不一致性、缺失值和冗余数据。数据集成将来自不同源的数据合并到单一视图中,数据选择则挑选出与特定任务相关的数据。数据变换是为了优化数据挖掘算法的性能,例如规范化或特征提取。数据挖掘阶段是应用各种算法(如决策树、聚类、关联规则等)来寻找潜在模式,然后通过模式评估来判断发现的模式是否具有实际意义。知识表示将挖掘出的模式以易于理解的形式呈现,如图表或报告。
数据挖掘不仅限于数据仓库环境,还可以应用于传统的数据库、数据库统计分析系统以及信息系统。然而,数据挖掘系统与基于数据仓库的OLAP系统、机器学习系统或信息查询系统有所不同,它更加关注复杂模式的发现和多学科的融合。
数据挖掘的主要功能包括描述性和预测性分析。描述性数据挖掘通过概念描述和类描述揭示数据的概括特征,比如对消费者群体的特征化和区分。关联分析则寻找项目之间的频繁模式,如购物篮分析,帮助商家了解商品之间的购买关联。分类和预测是数据挖掘的另一个重要方面,用于识别数据的类别模式,并对未知数据进行分类或预测,如信用评级或销售预测。
例如,在一个信用评估场景中,数据挖掘可以生成规则:如果年龄在31至40岁之间且收入较高,那么信用程度可能被预测为优质。这样的规则有助于银行或金融机构做出信贷决策。
总结来说,数据仓库与数据挖掘是现代信息技术的关键组成部分,它们帮助企业从大量数据中挖掘出有价值的信息,支持智能决策,并推动业务增长。随着大数据和人工智能技术的不断发展,这两个领域的应用将会越来越广泛,为企业带来更大的竞争优势。