
→_→ 欢迎去各大电商平台选购纸质版苹果书《深度学习详解》 ←_←
第 3 章 深度学习基础
本章介绍了深度学习常见的概念,理解这些概念能够帮助我们从不同角度来更好地优化
神经网络。要想更好地优化神经网络,首先,要理解为什么优化会失败,收敛在局部极限值与
鞍点会导致优化失败。其次,可以对学习率进行调整,使用自适应学习率和学习率调度。最
后,批量归一化可以改变误差表面,这对优化也有帮助。
3.1 局部极小值与鞍点
我们在做优化的时候经常会发现,随着参数不断更新,训练的损失不会再下降, 但是我们
对这个损失仍然不满意。把深层网络(deep network)、线性模型和浅层网络(shallow network)
做比较,可以发现深层网络没有做得更好——深层网络没有发挥出它完整的力量,所以优化
是有问题的。但有时候,模型一开始就训练不起来,不管我们怎么更新参数,损失都降不下
去。这个时候到底发生了什么事情?
3.1.1 临界点及其种类
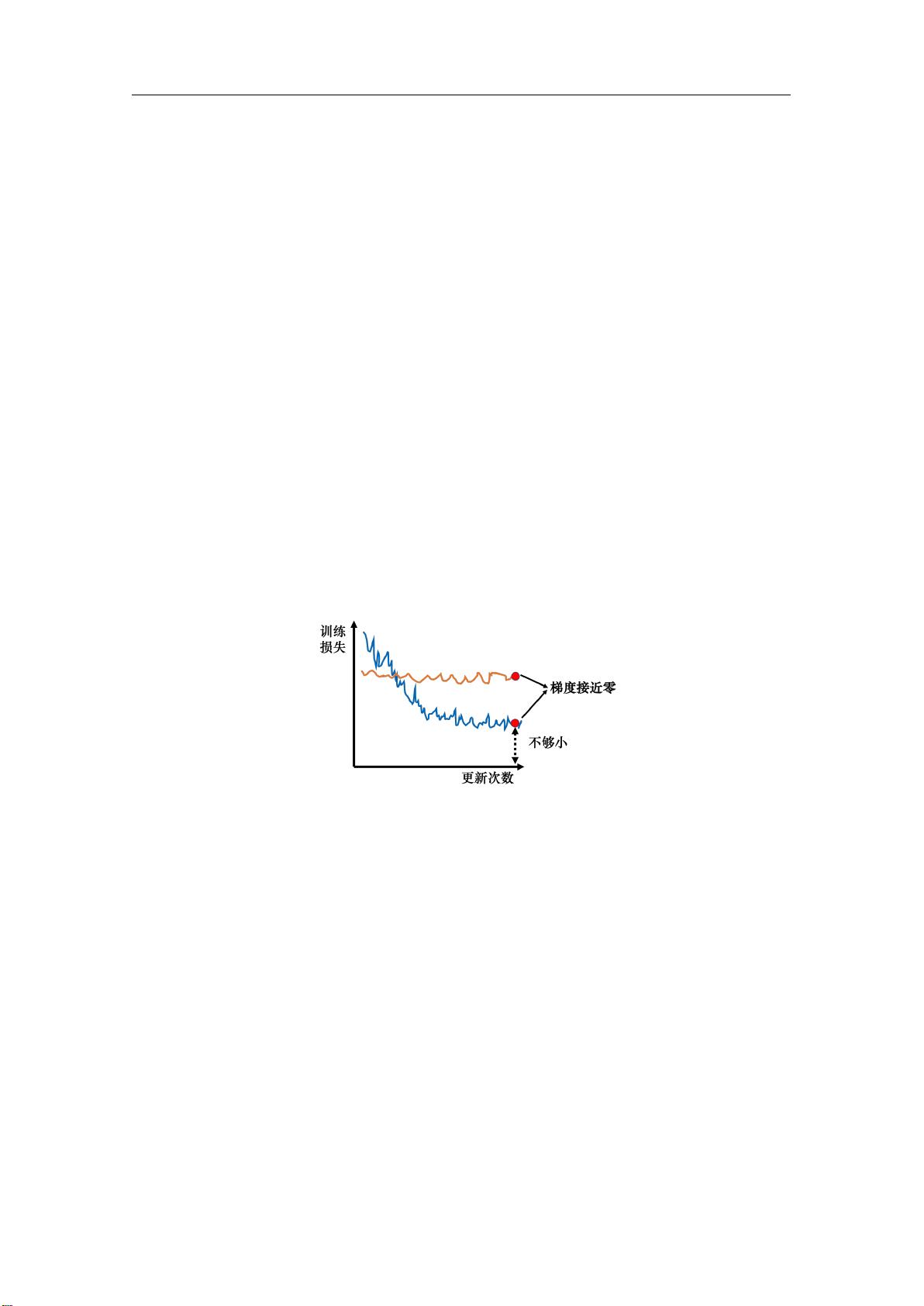
过去常见的一个猜想是我们优化到某个地方,这个地方参数对损失的微分为零,如图 3.1
所示。图 3.1 中的两条曲线对应两个神经网络训练的过程。当参数对损失微分为零的时候,梯
度下降就不能再更新参数了,训练就停下来了,损失不再下降了。
图 3.1 梯度下降失效的情况
提到梯度为零的时候,大家最先想到的可能就是局部极小值(local minimum),如
图 3.2a 所示。所以经常有人说,做深度学习时使用梯度下降会收敛在局部极小值,梯度下降
不起作用。但其实损失不是只在局部极小值的梯度是零,还有其他可能会让梯度是零的点,比
如鞍点(saddle point)。鞍点其实就是梯度是零且区别于局部极小值和局部极大值(local
maximum)的点。图 3.2b 红色的点在 y 轴方向是比较高的,在 x 轴方向是比较低的,这就
是一个鞍点。鞍点的叫法是因为其形状像马鞍。鞍点的梯度为零,但它不是局部极小值。我们
把梯度为零的点统称为临界点(critical point)。损失没有办法再下降,也许是因为收敛在了
临界点,但不一定收敛在局部极小值,因为鞍点也是梯度为零的点。
但是如果一个点的梯度真的很接近零,我们走到临界点的时候,这个临界点到底是局部
极小值还是鞍点,是一个值得去探讨的问题。因为如果损失收敛在局部极小值,我们所在的位
置已经是损失最低的点了,往四周走损失都会比较高,就没有路可以走了。但鞍点没有这个问
题,旁边还是有路可以让损失更低的。只要逃离鞍点,就有可能让损失更低。
39
资源评论


m0_58854572
- 粉丝: 44
- 资源: 5









最新资源
- 数据集-目标检测系列- 戒指 检测数据集 ring >> DataBall
- 数据集-目标检测系列- 皇冠 头饰 检测数据集 crown >> DataBall
- 利用哨兵 2 号卫星图像和 GRanD 大坝数据集进行的首次大坝检测迭代.ipynb
- 数据集-目标检测系列- 红色裙子 检测数据集 red-skirt >> DataBall
- DNS服务器搭建-单机部署
- 数据集-目标检测系列- 猫咪 小猫 检测数据集 cat >> DataBall
- matlab写的导弹轨迹代码
- 金融贷款口子超市V2源码 Thinkphp开发的贷款和超市平台源码
- 数据集-目标检测系列- 土拨鼠 检测数据集 marmot >> DataBall
- 数据集-目标检测系列- 婚纱 检测数据集 wedding-dress >> DataBall
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


