
基本概念
2.1 Messages And Batches
的基本数据单元被称为 消息,为减少网络开销,提高效率,多个消息会被放入同一批次 中后再
写入。
2.2 Topics And Partitions
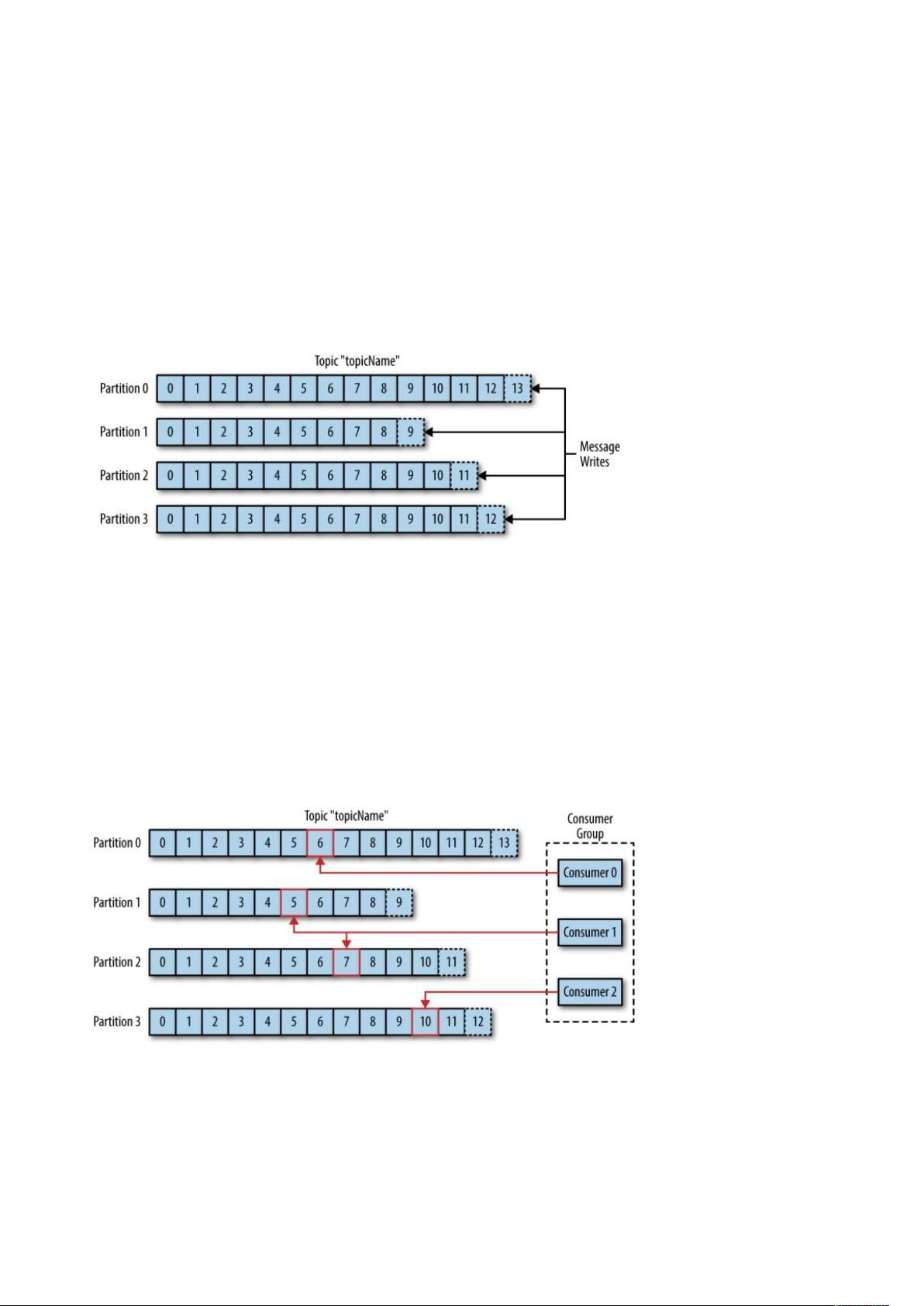
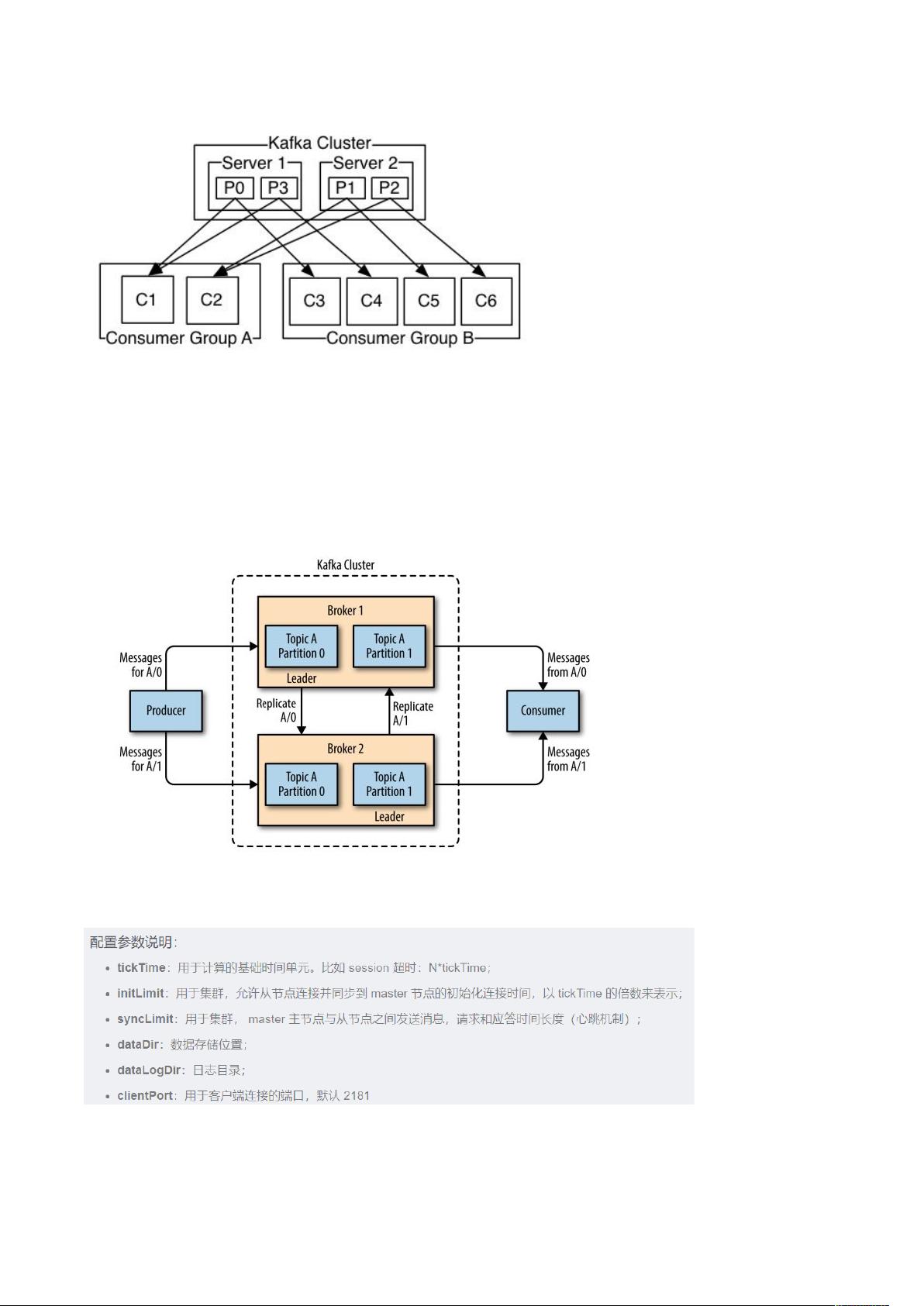
的消息通过 主题进行分类,一个主题可以被分为若干个 分区,一个分区就是一个提交日志
。消息以追加的方式写入分区,然后以先入先出的顺序读取。通过分区来实现数据的冗余和伸缩性,
分区可以分布在不同的服务器上,这意味着一个 可以横跨多个服务器,以提供比单个服务器更强大的性能。
由于一个 包含多个分区,因此无法在整个 范围内保证消息的顺序性,但可以保证消息在单个分区内的顺序性。
2.3 Producers And Consumers
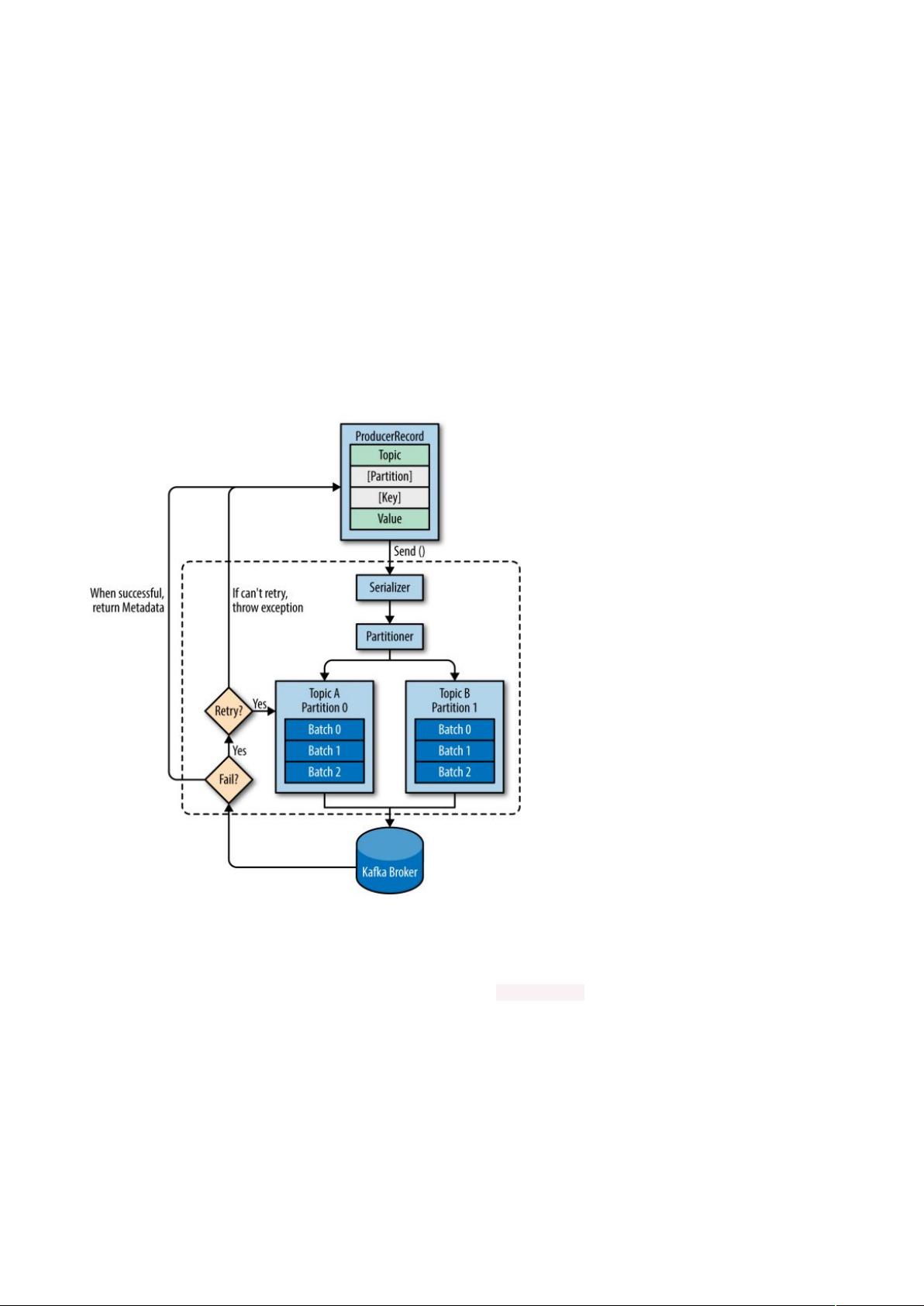
1. 生产者
生产者负责创建消息。一般情况下,生产者在把消息均衡地分布到在主题的所有分区上,而并不关心消息会被写到哪个分区。
如果我们想要把消息写到指定的分区,可以通过自定义分区器来实现。
2. 消费者
消费者是消费者群组的一部分,消费者负责消费消息。消费者可以订阅一个或者多个主题,并按照消息生成的顺序来读取它
们。消费者通过检查消息的偏移量 来区分读取过的消息。偏移量是一个不断递增的数值,在创建消息时,
会把它添加到其中,在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的偏移量保存在
或 上,如果消费者关闭或者重启,它还可以重新获取该偏移量,以保证读取状态不会丢失。
一个分区只能被同一个消费者群组里面的一个消费者读取,但可以被不同消费者群组中所组成的多个消费者共同读取。多个
消费者群组中消费者共同读取同一个主题时,彼此之间互不影响。
剩余15页未读,继续阅读

追凡客
- 粉丝: 0
- 资源: 1









最新资源
- 毕设和企业适用springboot区域电商平台类及物流信息平台源码+论文+视频.zip
- 毕设和企业适用springboot区域电商平台类及在线教育互动平台源码+论文+视频.zip
- 毕设和企业适用springboot区域电商平台类及智慧社区管理平台源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及企业数字资产管理平台源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及气象数据管理系统源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及企业风险监控平台源码+论文+视频.zip
- 毕设和企业适用springboot商城类及智能农业解决方案源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及VR互动平台源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及大数据存储平台源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及大数据实时处理系统源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及大数据云平台源码+论文+视频.zip
- 毕设和企业适用springboot全渠道电商平台类及电商产品推荐平台源码+论文+视频.zip
- 毕设和企业适用springboot区域电商平台类及智能云平台源码+论文+视频.zip
- 毕设和企业适用springboot区域电商平台类及自动化控制系统源码+论文+视频.zip
- 毕设和企业适用springboot全渠道电商平台类及个性化广告平台源码+论文+视频.zip
- 毕设和企业适用springboot全渠道电商平台类及酒店管理平台源码+论文+视频.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0