
# keras-yolo3
参考博客:
[【Yolo3】一文掌握图像标注、训练、识别(Keras+TensorFlow-gpu)](https://cungudafa.blog.csdn.net/article/details/105074825)
[【Keras+TensorFlow+Yolo3】教你如何识别影视剧人手模型](https://cungudafa.blog.csdn.net/article/details/105137889)
# 环境
环境:`windows10 + anaconda3(conda4.8.2)+ labelImg1.8.1 + VSCode`
版本:`python3.6.0 + opencv4.1.0 + yolo3 +keras 2.3.1 +tensorflow-gpu2.1.0`
>环境安装记录:
>
>[【GPU】win10 (1050Ti)+anaconda3+python3.6+CUDA10.0+tensorflow-gpu2.1.0](https://cungudafa.blog.csdn.net/article/details/105089003)
>
>库:numpy1.18.2、Pillow7.0.0、matplotlib 、python-opencv4.2.0
# 目录
原始目录:[docs/tree_old.txt](https://gitee.com/cungudafa/keras-yolo3/blob/master/docs/tree_old.txt)
我重新整合了一下目录结构:[docs/tree.txt](https://gitee.com/cungudafa/keras-yolo3/blob/master/docs/tree.txt)
# 运行过程
## 1.下载
1. 下载项目框架
```
git clone https://gitee.com/cungudafa/keras-yolo3.git
```
2. 下载权重
[单独下载yolov3.weights 权重](https://pan.baidu.com/s/1CVgvP4hQQvDNbKmXhmkxqw),放在项目根目录下
3. 将 DarkNet 的.weights文件转换成 Keras 的.h5文件
```bash
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
```
可以查看到我们的模型结构:
[docs/model_summary.txt](https://gitee.com/cungudafa/keras-yolo3/blob/master/docs/model_summary.txt)
## 2.标签分类
下载数据集:(`我这里用hand进行试验,你可以用你自己的标注数据集`)
本次使用的**数据集**来自:[牛津大学Arpit Mittal, Andrew Zisserman和 Phil Torr](http://www.robots.ox.ac.uk/~vgg/data/hands/)

**资料下载:**
我们用到的数据集为VOC格式:我们仅下载[evaluation_code.tar.gz](http://www.robots.ox.ac.uk/~vgg/data/hands/downloads/evaluation_code.tar.gz)(13.8M)即可。
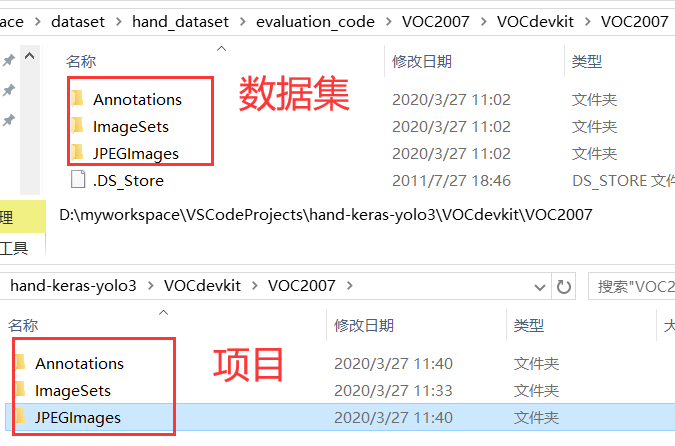
将下载的数据集复制到项目路径下:(事实是数据集有400+图片,我训练起来太累了,容易过拟合,这里只用了009985-010028共40+张图片进行训练)
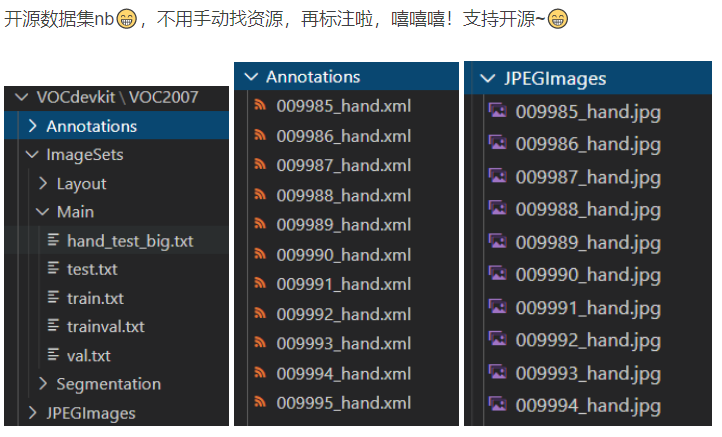
运行script目录下获取标签:
1. voc标签格式:voc_annotation.py
2. yolo标签格式:yolo_annotation.py
## 3.训练
1. 修改train.py中训练轮速、路径(可选步骤)
2. 训练 train.py(50轮和100轮,各保存一次)保存在logs目录下
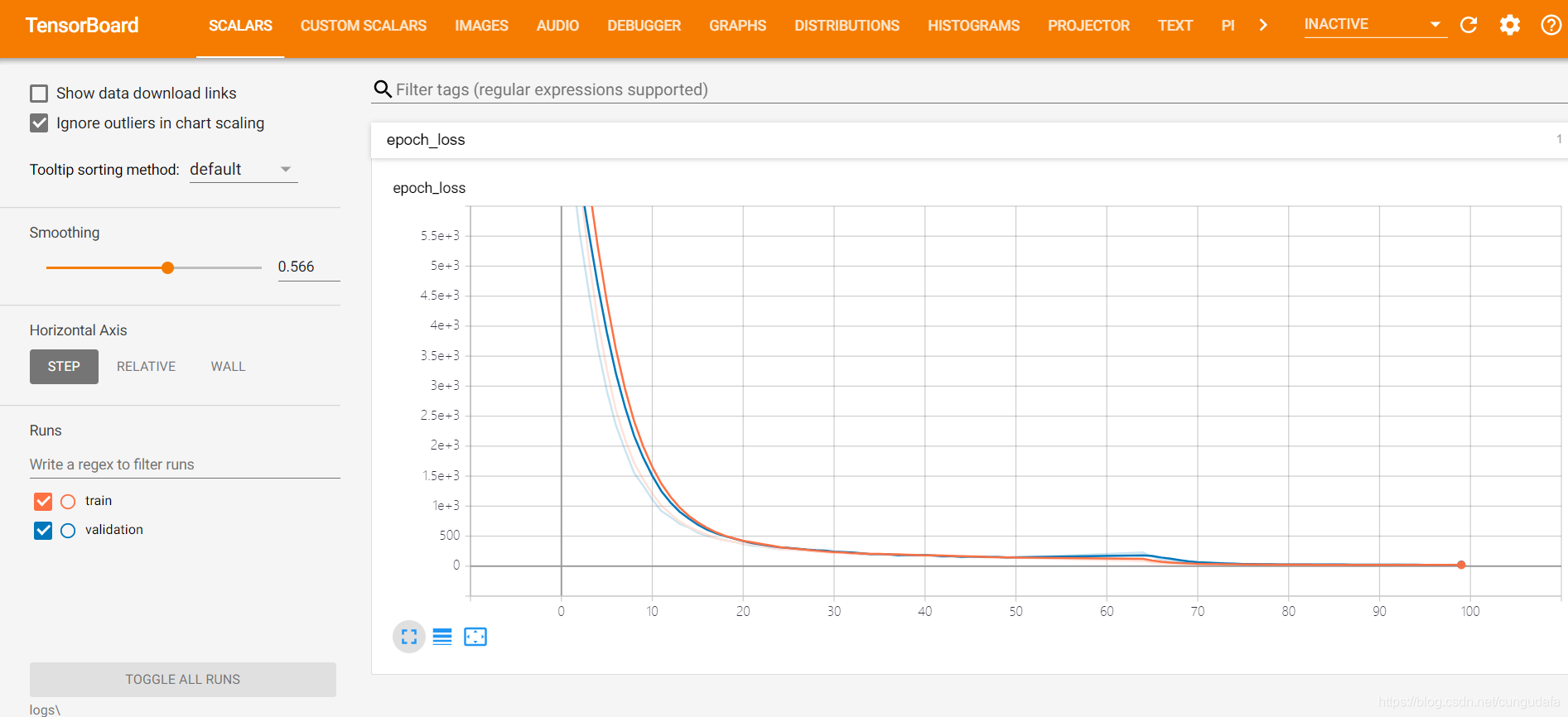
>神经网络可视化,在根目录下运行:`tensorboard --logdir=logs\`
>
>会将运行记录打印到浏览器中
>
>打开浏览器查看:[http://localhost:6006/](http://localhost:6006/)
**可视化查看神经网络loss:**
1. 项目目录下运行:
```
tensorboard --logdir=logs\
```
2. 浏览器查看:[http://localhost:6006/](http://localhost:6006/)
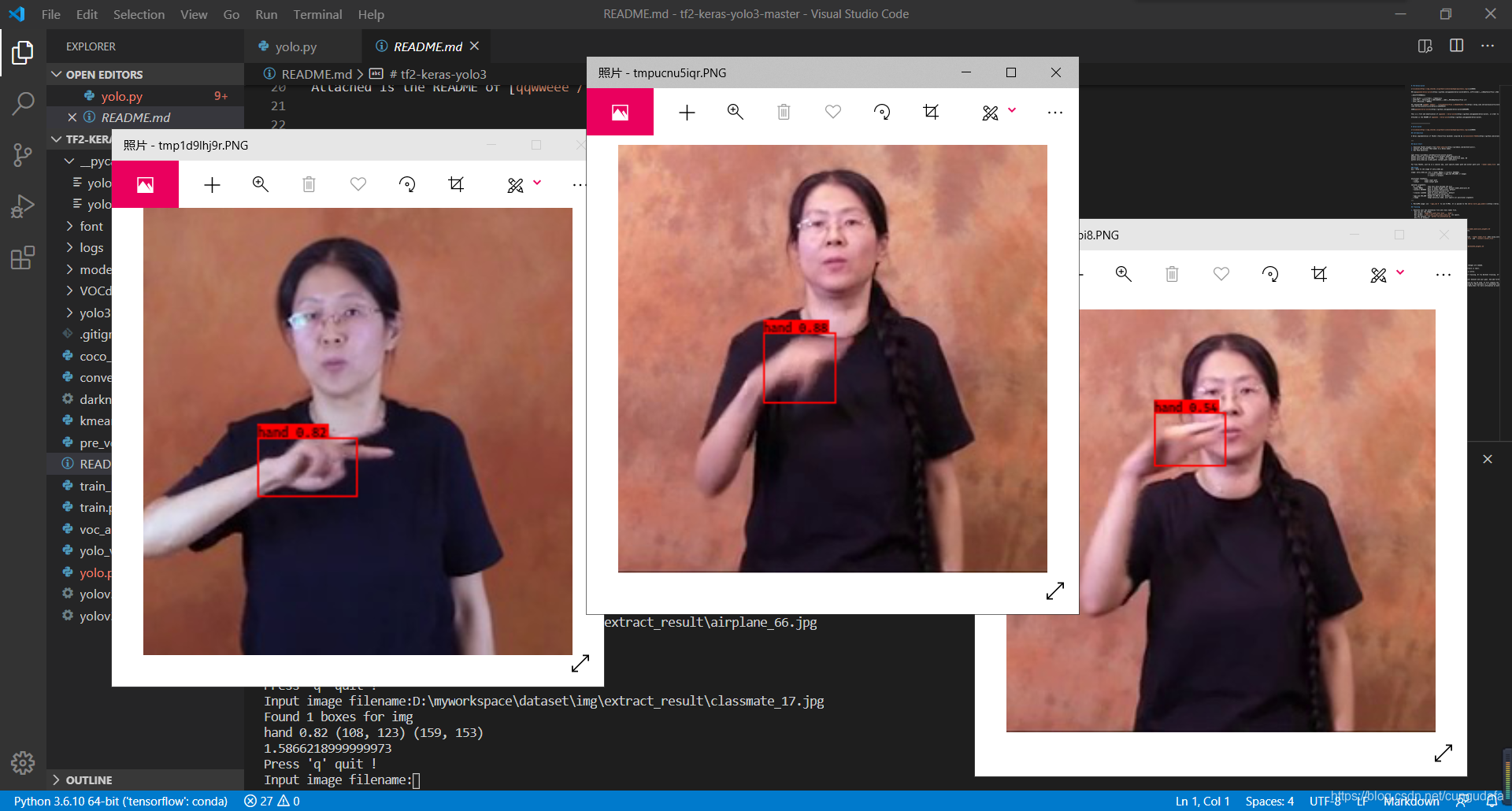
## 4.测试
参考[tf2-keras-yolo3](https://github.com/AaronJny/tf2-keras-yolo3),可以直接对图片和视频进行检测。
我另外封装了一下检测部分的代码:识别部分[keras-yolo3-recognize](https://download.csdn.net/download/cungudafa/12283933)
运行predict.py或者:
```
# 图片检测
python yolo_video.py --image
再输入图片路径
# 视频检测
python yolo_video.py --input img\test.mp4
```


 Python实现对图像标注、训练、识别.zip (30个子文件)
Python实现对图像标注、训练、识别.zip (30个子文件)  keras-yolo3-master core
keras-yolo3-master core  darknet53.py 2KB loss.py 9KB utils.py 3KB yolo3.py 13KB docs
darknet53.py 2KB loss.py 9KB utils.py 3KB yolo3.py 13KB docs  test.jpg 221KB
test.jpg 221KB model_summary.txt 105KB dragonofmom.jpg 26KB dragonofmom2.jpg 31KB font FiraMono-Medium.otf 124KB SIL Open Font License.txt 4KB tree_old.txt 2KB tree.txt 4KB test1.jpg 20KB
model_summary.txt 105KB dragonofmom.jpg 26KB dragonofmom2.jpg 31KB font FiraMono-Medium.otf 124KB SIL Open Font License.txt 4KB tree_old.txt 2KB tree.txt 4KB test1.jpg 20KB xuanya.mp4 1.19MB test2.jpg 23KB
xuanya.mp4 1.19MB test2.jpg 23KB exam.png 0B data anchors coco_anchors.txt 76B dataset val.txt 137B test.txt 392B train.txt 5KB classes voc_classes.txt 6B coco.name 0B train.py 10KB LICENSE 1KB convert.py 11KB .gitignore 2KB yolov3.cfg 8KB README.md 4KB scripts yolo_annotations.py 2KB voc_annotations.py 1KB
exam.png 0B data anchors coco_anchors.txt 76B dataset val.txt 137B test.txt 392B train.txt 5KB classes voc_classes.txt 6B coco.name 0B train.py 10KB LICENSE 1KB convert.py 11KB .gitignore 2KB yolov3.cfg 8KB README.md 4KB scripts yolo_annotations.py 2KB voc_annotations.py 1KB
我慢慢地也过来了
- 粉丝: 9971
- 资源: 4072









最新资源
- (源码)基于Java的DVD租赁管理系统.zip
- (源码)基于Arduino的模型铁路控制系统.zip
- (源码)基于C语言STM32F10x框架的温湿度监控系统.zip
- (源码)基于Spring Boot的极简易课堂对话系统.zip
- (源码)基于JSP+Servlet+MySQL的学生管理系统.zip
- (源码)基于ESP8266的蜂箱监测系统.zip
- (源码)基于Spring MVC和Hibernate框架的学校管理系统.zip
- (源码)基于TensorFlow 2.3的高光谱水果糖度分析系统.zip
- (源码)基于Python框架库的知识库管理系统.zip
- (源码)基于C++的日志管理系统.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论10