大数据设计方案是企业在开展大数据项目时的关键文档,它涵盖了系统数据流程设计、具体版本选型、服务器选型、运维成本分析以及集群规模规划等多个方面。以下是对这些内容的详细阐述:
1. **系统数据流程设计**:
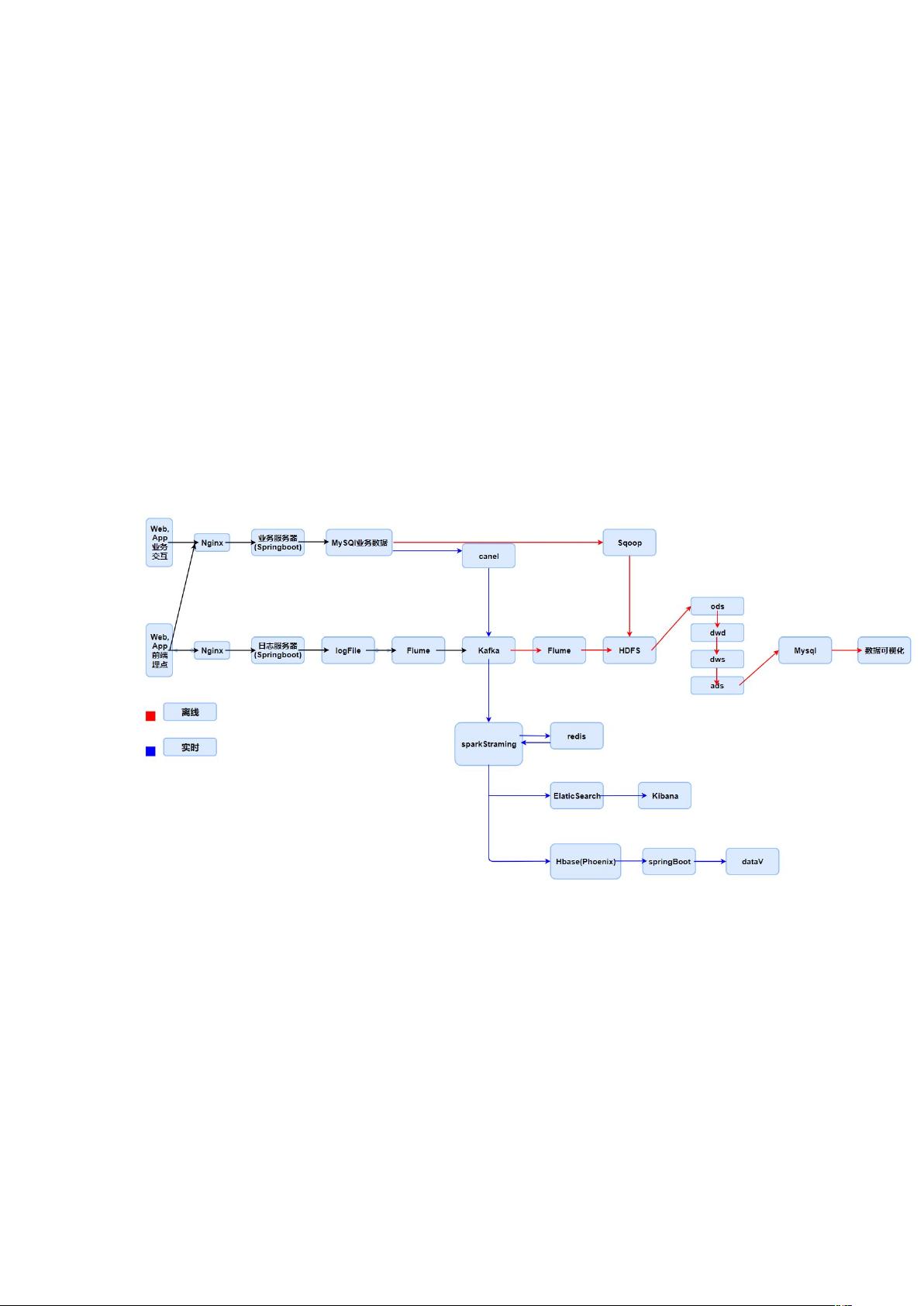
- **集群流程图**:展示了数据从不同源头收集、处理到最终存储和分析的整个过程,包括数据采集、清洗、转换、存储和查询等环节。
- **集群框架图**:描绘了大数据集群的架构,包括各个组件如何交互和协同工作,如Hadoop、Kafka、Hive、Spark等。
- **集群特点**:强调了集群需具备多数据源对接、离线/在线处理能力、统一管理和监控、用户认证及权限管理以满足多租户需求。
2. **具体版本选型**:
- **Apache框架**:选择了Hadoop 2.7.2、Flume 1.7.0、Kafka 0.11.0.2等稳定且功能丰富的版本,确保系统的稳定性和性能。
- **其他组件**:包括Hive 1.2.1用于大规模数据计算,Sqoop 1.4.6用于数据导入导出,MySQL 5.6.24作为关系型数据库,Azkaban 2.5.0用于工作流调度,以及Elasticsearch 6.3.1和Kibana 6.3.1提供数据分析和可视化。
3. **服务器选型**:
- **物理机与云主机**:对比了物理机和阿里云主机的成本,包括硬件配置(如内存、CPU、硬盘)和寿命。物理机需要专门运维,而云主机运维由阿里云负责。
- **成本考虑**:物理机初期投入大,但后续运维成本低;云主机虽有灵活扩展性,但长期运行成本较高。
4. **运维成本考虑**:
- 物理机需要额外的运维人员进行维护,而云主机则由服务商提供运维服务,降低了企业内部的人力资源需求。
5. **集群规模**:
- **数据量分析**:基于用户行为数据、Kafka中的数据和业务数据的规模,计算了所需的存储空间,并考虑到数据冗余和预留空间。
- **集群规划**:设计了包括DataNode、NameNode、ResourceManager、NodeManager、Zookeeper、Kafka、Flume、Hbase、Hive、MySQL、Spark、Elasticsearch、Sqoop和Azkaban在内的服务器分配,以满足不同组件的需求。
6. **离线测试集群服务器规划**:
- 自服务服务器、Hadoop102、Hadoop03和Hadoop104分别承担了不同的角色,如NameNode、DataNode、NodeManager、ResourceManager、Zookeeper、Flume、Kafka、Hive、MySQL、Spark等,确保了测试环境的完整性和功能性。
这份设计方案为企业的大数据项目提供了全面的指导,从技术选型到硬件配置,再到集群管理和运维成本的考量,为企业构建了一个可靠且高效的大数据处理环境。














评论0