
馃摎 This guide explains how to use **Weights & Biases** (W&B) with YOLOv5 馃殌. UPDATED 29 September 2021.
* [About Weights & Biases](#about-weights-&-biases)
* [First-Time Setup](#first-time-setup)
* [Viewing runs](#viewing-runs)
* [Disabling wandb](#disabling-wandb)
* [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
* [Reports: Share your work with the world!](#reports)
## About Weights & Biases
Think of [W&B](https://wandb.ai/site?utm_campaign=repo_yolo_wandbtutorial) like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models 鈥� architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
* [Debug](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Free-2) model performance in real time
* [GPU usage](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#System-4) visualized automatically
* [Custom charts](https://wandb.ai/wandb/customizable-charts/reports/Powerful-Custom-Charts-To-Debug-Model-Peformance--VmlldzoyNzY4ODI) for powerful, extensible visualization
* [Share insights](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Share-8) interactively with collaborators
* [Optimize hyperparameters](https://docs.wandb.com/sweeps) efficiently
* [Track](https://docs.wandb.com/artifacts) datasets, pipelines, and production models
## First-Time Setup
<details open>
<summary> Toggle Details </summary>
When you first train, W&B will prompt you to create a new account and will generate an **API key** for you. If you are an existing user you can retrieve your key from https://wandb.ai/authorize. This key is used to tell W&B where to log your data. You only need to supply your key once, and then it is remembered on the same device.
W&B will create a cloud **project** (default is 'YOLOv5') for your training runs, and each new training run will be provided a unique run **name** within that project as project/name. You can also manually set your project and run name as:
```shell
$ python train.py --project ... --name ...
```
YOLOv5 notebook example: <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
<img width="960" alt="Screen Shot 2021-09-29 at 10 23 13 PM" src="https://user-images.githubusercontent.com/26833433/135392431-1ab7920a-c49d-450a-b0b0-0c86ec86100e.png">
</details>
## Viewing Runs
<details open>
<summary> Toggle Details </summary>
Run information streams from your environment to the W&B cloud console as you train. This allows you to monitor and even cancel runs in <b>realtime</b> . All important information is logged:
* Training & Validation losses
* Metrics: Precision, Recall, mAP@0.5, mAP@0.5:0.95
* Learning Rate over time
* A bounding box debugging panel, showing the training progress over time
* GPU: Type, **GPU Utilization**, power, temperature, **CUDA memory usage**
* System: Disk I/0, CPU utilization, RAM memory usage
* Your trained model as W&B Artifact
* Environment: OS and Python types, Git repository and state, **training command**
<p align="center"><img width="900" alt="Weights & Biases dashboard" src="https://user-images.githubusercontent.com/26833433/135390767-c28b050f-8455-4004-adb0-3b730386e2b2.png"></p>
</details>
## Disabling wandb
* training after running `wandb disabled` inside that directory creates no wandb run
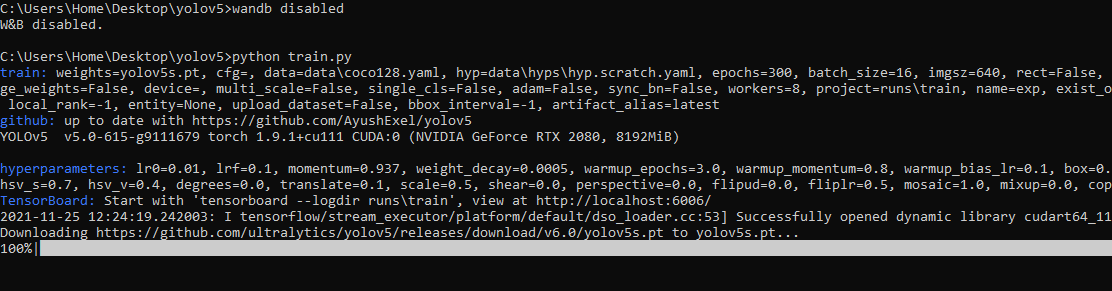
* To enable wandb again, run `wandb online`
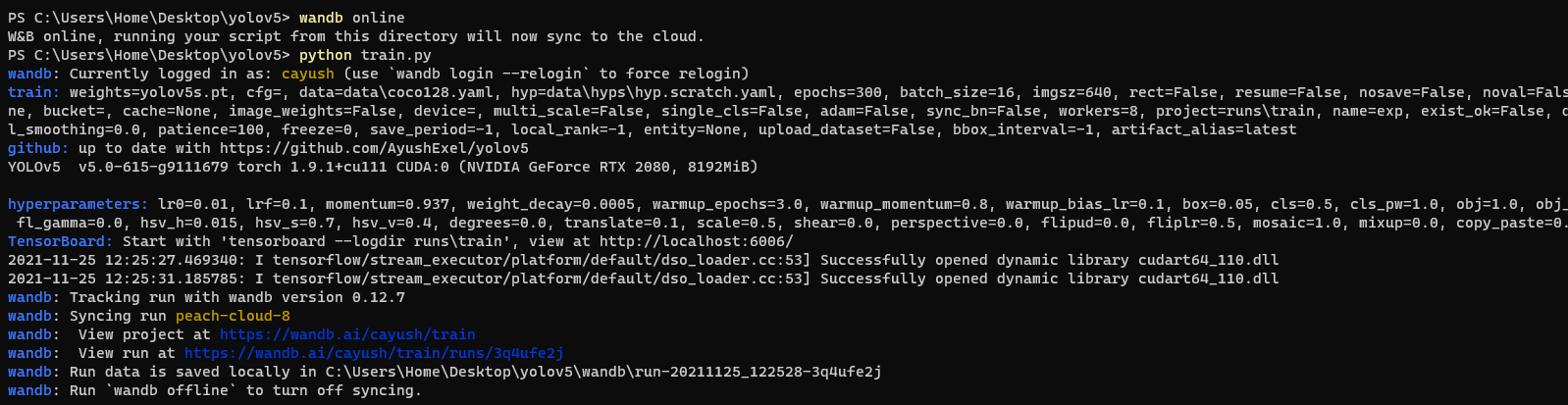
## Advanced Usage
You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
<details open>
<h3> 1: Train and Log Evaluation simultaneousy </h3>
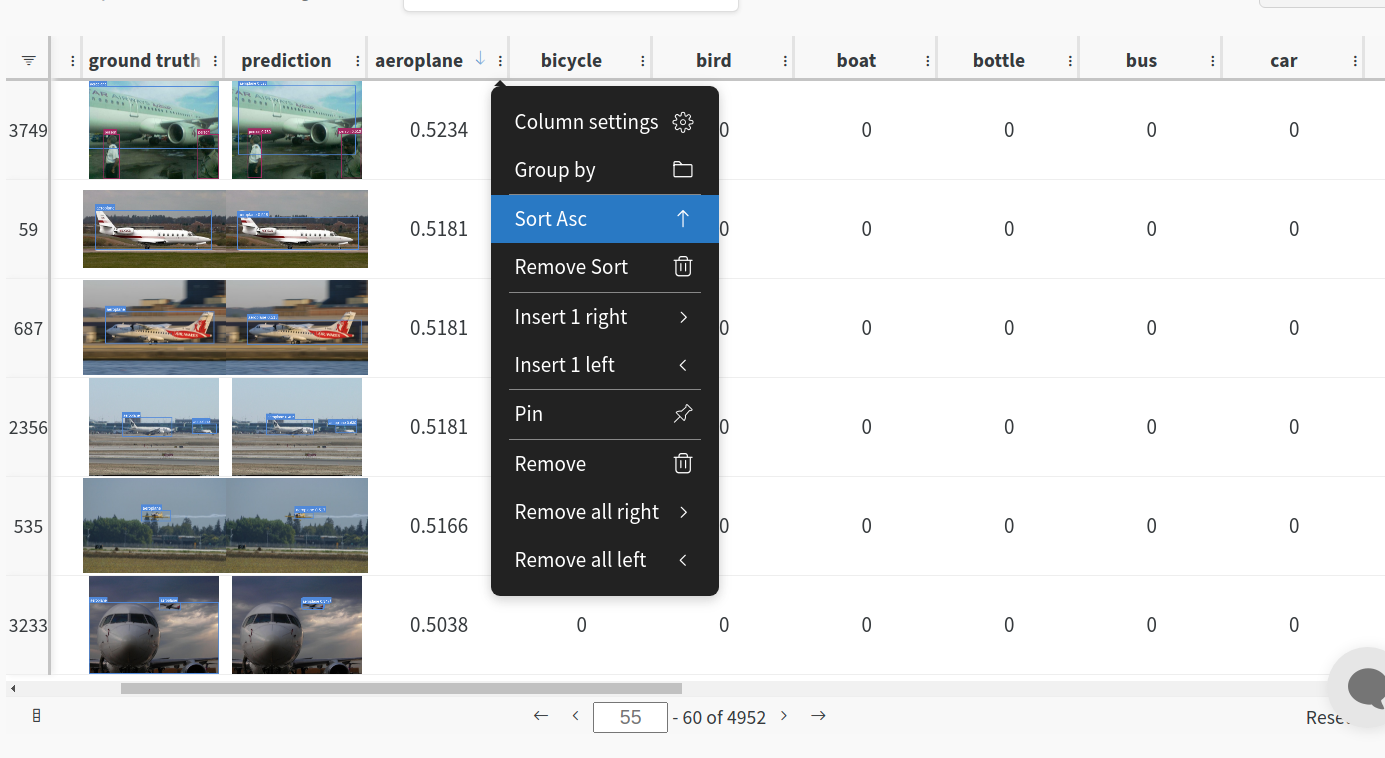
This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
so no images will be uploaded from your system more than once.
<details open>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --upload_data val</code>
</details>
<h3>2. Visualize and Version Datasets</h3>
Log, visualize, dynamically query, and understand your data with <a href='https://docs.wandb.ai/guides/data-vis/tables'>W&B Tables</a>. You can use the following command to log your dataset as a W&B Table. This will generate a <code>{dataset}_wandb.yaml</code> file which can be used to train from dataset artifact.
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data .. </code>

</details>
<h3> 3: Train using dataset artifact </h3>
When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that
can be used to train a model directly from the dataset artifact. <b> This also logs evaluation </b>
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --data {data}_wandb.yaml </code>

</details>
<h3> 4: Save model checkpoints as artifacts </h3>
To enable saving and versioning checkpoints of your experiment, pass `--save_period n` with the base cammand, where `n` represents checkpoint interval.
You can also log both the dataset and model checkpoints simultaneously. If not passed, only the final model will be logged
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --save_period 1 </code>

</details>
</details>
<h3> 5: Resume runs from checkpoint artifacts. </h3>
Any run can be resumed using artifacts if the <code>--resume</code> argument starts with聽<code>wandb-artifact://</code>聽prefix followed by the run path, i.e,聽<code>wandb-artifact://username/project/runid </code>. This doesn't require the model checkpoint to be present on the local system.
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --resume wandb-artifact://{run_path} </code>

</details>
<h3> 6: Resume runs from dataset artifact & checkpoint artifacts. </h3>
<b> Local dataset or model checkpoints are not required. This can be used to resume runs directly on a different device </b>
The syntax is same as the previous se
 YOLOv5deepsort算法船舶等交通工具监测计数UI界面源码.zip (236个子文件)
YOLOv5deepsort算法船舶等交通工具监测计数UI界面源码.zip (236个子文件)  Dockerfile 846B
Dockerfile 846B main.exe 15.59MB .gitkeep 0B
main.exe 15.59MB .gitkeep 0B xref-main.html 3.37MB
xref-main.html 3.37MB bus.jpg 476KB zidane.jpg 165KB background.jpg 144KB train.jpg 59KB boat.jpg 2KB setting.json 84B fold.json 44B ip.json 33B main.exe.manifest 1KB README.md 11KB README.md 2KB README.md 87B README.md 67B main.pkg 15.28MB
bus.jpg 476KB zidane.jpg 165KB background.jpg 144KB train.jpg 59KB boat.jpg 2KB setting.json 84B fold.json 44B ip.json 33B main.exe.manifest 1KB README.md 11KB README.md 2KB README.md 87B README.md 67B main.pkg 15.28MB zidane.png 1.92MB world-book-day.png 27KB book.png 20KB swap.png 15KB reading.png 15KB four-arrows.png 10KB folder.png 8KB directions.png 8KB conan.png 4KB street-sign.png 4KB doctor.png 3KB evil.png 3KB button-on.png 2KB button-off.png 1KB direction.png 1KB file.png 1KB book1.png 956B swap1.png 671B yolov5s.pt 14.12MB apprcc_rc.py 12.37MB main.py 61KB win.py 48KB datasets.py 46KB general.py 36KB common.py 33KB wandb_utils.py 27KB tf.py 21KB plots.py 21KB wandb_utils.py 19KB yolo.py 15KB metrics.py 14KB torch_utils.py 14KB json_logger.py 12KB augmentations.py 12KB loss.py 10KB linear_assignment.py 8KB kalman_filter.py 8KB __init__.py 8KB autoanchor.py 7KB downloads.py 6KB train.py 6KB google_utils.py 6KB nn_matching.py 6KB tracker.py 5KB track.py 5KB experimental.py 5KB tracker.py 4KB io.py 4KB deep_sort.py 4KB benchmarks.py 4KB activations.py 4KB evaluation.py 4KB rtsp_dialog.py 4KB original_model.py 3KB model.py 3KB iou_matching.py 3KB callbacks.py 2KB test.py 2KB autobatch.py 2KB detector.py 2KB preprocessing.py 2KB CustomMessageBox.py 2KB feature_extractor.py 2KB detection.py 1KB resume.py 1KB sweep.py 1KB draw.py 1KB __init__.py 1KB restapi.py 1KB log_dataset.py 1KB parser.py 1024B sweep.py 910B log_dataset.py 896B tools.py 773B capnums.py 669B MouseLabel.py 598B __init__.py 521B log.py 480B rtsp_win.py 368B asserts.py 329B example_request.py 312B evaluate.py 308B
zidane.png 1.92MB world-book-day.png 27KB book.png 20KB swap.png 15KB reading.png 15KB four-arrows.png 10KB folder.png 8KB directions.png 8KB conan.png 4KB street-sign.png 4KB doctor.png 3KB evil.png 3KB button-on.png 2KB button-off.png 1KB direction.png 1KB file.png 1KB book1.png 956B swap1.png 671B yolov5s.pt 14.12MB apprcc_rc.py 12.37MB main.py 61KB win.py 48KB datasets.py 46KB general.py 36KB common.py 33KB wandb_utils.py 27KB tf.py 21KB plots.py 21KB wandb_utils.py 19KB yolo.py 15KB metrics.py 14KB torch_utils.py 14KB json_logger.py 12KB augmentations.py 12KB loss.py 10KB linear_assignment.py 8KB kalman_filter.py 8KB __init__.py 8KB autoanchor.py 7KB downloads.py 6KB train.py 6KB google_utils.py 6KB nn_matching.py 6KB tracker.py 5KB track.py 5KB experimental.py 5KB tracker.py 4KB io.py 4KB deep_sort.py 4KB benchmarks.py 4KB activations.py 4KB evaluation.py 4KB rtsp_dialog.py 4KB original_model.py 3KB model.py 3KB iou_matching.py 3KB callbacks.py 2KB test.py 2KB autobatch.py 2KB detector.py 2KB preprocessing.py 2KB CustomMessageBox.py 2KB feature_extractor.py 2KB detection.py 1KB resume.py 1KB sweep.py 1KB draw.py 1KB __init__.py 1KB restapi.py 1KB log_dataset.py 1KB parser.py 1024B sweep.py 910B log_dataset.py 896B tools.py 773B capnums.py 669B MouseLabel.py 598B __init__.py 521B log.py 480B rtsp_win.py 368B asserts.py 329B example_request.py 312B evaluate.py 308B共 236 条
- 1
- 2
- 3
资源评论


不会仰游的河马君
- 粉丝: 5559
- 资源: 7747









最新资源
- 使用MATLAB和Simulink对雷达系统进行建模和仿真 (1) matlab代码.rar
- 使用Mie理论的近场电场计算Matlab代码.rar
- 使用MATLAB进行雷达系统设计和分析 matlab代码.rar
- 使用MATLAB模拟单相三电平二极管钳位MLI.rar
- 使用Mie理论计算雷达截面积(RCS)Matlab代码.rar
- 使用传输矩阵方法的多层介质堆叠的透射率和反射率光谱Matlab代码.rar
- 使用各种驱动周期的电动三轮车模拟仿真Simulink模型.zip
- 使用各种驱动周期的电动三轮车模拟仿真Simulink模型.zip
- 使用均匀线性阵列的一维相位干涉测量中的数字数据 matlab代码.rar
- 使用均匀线性阵列的一维相位干涉测量中的数字数据 matlab代码.rar
- 使用基本相关接收机绘制UWB PPM单周期和双周期的时域和频域图 matlab代码.rar
- 使用基本相关接收机绘制UWB PPM单周期和双周期的时域和频域图 matlab代码.rar
- 使用简单导电路径模型探索静电平衡的 Live Script matlab代码.rar
- 使用简单导电路径模型探索静电平衡的 Live Script matlab代码.rar
- 数组信号参数最大似然估计方差模拟 matlab代码.rar
- 数组信号参数最大似然估计方差模拟 matlab代码.rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


