

Unstructured Lumigraph Rendering
Chris Buehler Michael Bosse Leonard McMillan Steven Gortler Michael Cohen
MIT Laboratory for Computer Science Harvard University Microsoft Research
Abstract
We describe an image based rendering approach that generalizes
many current image based rendering algorithms, including light
field rendering and view-dependent texture mapping. In particular,
it allows for lumigraph-style rendering from a set of input cameras
in arbitrary configurations (i.e., not restricted to a plane or to any
specific manifold). In the case of regular and planar input camera
positions, our algorithm reduces to a typical lumigraph approach.
When presented with fewer cameras and good approximate geom-
etry, our algorithm behaves like view-dependent texture mapping.
The algorithm achieves this flexibility because it is designed to meet
a set of specific goals that we describe. We demonstrate this flexi-
bility with a variety of examples.
Keyword Image-Based Rendering
1 Introduction
Image-based rendering (IBR) has become a popular alternative to
traditional three-dimensional graphics. Two effective IBR meth-
ods are view-dependent texture mapping (VDTM) [3] and the light
field/lumigraph [10, 5] approaches. The light field and VDTM algo-
rithms are in many ways quite different in their assumptions and in-
put. Light field rendering requires a large collection of images from
cameras whose centers lie on a regularly sampled two-dimensional
patch, but it makes few if any assumptions about the geometry of
the scene. In contrast, VDTM assumes a relatively accurate ge-
ometric model, but requires only a small number of images from
input cameras that can be in general positions. These images are
then “projected” onto the geometry for rendering.
We suggest that, at their core, these two approaches are quite
similar. Both are methods for interpolating color values for a de-
sired ray as some combination of input rays. In VDTM this inter-
polation is performed using a geometric model to determine which
pixel from each input image “corresponds” to the desired ray in the
output image. Of these corresponding rays, those that are closest in
angle to the desired ray are weighted to make the greatest contribu-
tion to the interpolated result.
Light field rendering can be similarly interpreted. For each de-
sired ray (s, t, u, v), one searches the image database for rays that
intersect near some (u, v) point on a “focal plane” and have a simi-
lar angle to the desired ray, as measured by the ray’s intersection on
the “camera plane” (s, t). In a depth-corrected lumigraph, the focal
plane is effectively replaced with an approximate geometric model,
making this approach even more similar to view dependent texture
mapping.
Given these related IBR approaches, we attempt to address the
following questions: Is there a generalized rendering framework
that spans all of these image-based rendering algorithms, having
VDTM and lumigraph/light fields as extremes? Might such an al-
gorithm adapt well to various numbers of input images from cam-
eras in general configurations while also permitting various levels
of geometric accuracy?
In this paper we approach the problem by suggesting a set of
goals that any image based rendering algorithm should have. We
find that no previous IBR algorithm simultaneously satisfies all of
these goals. Therefore these algorithms behave quite well under
appropriate assumptions on their input, but may produce unneces-
sarily poor renderings when these assumptions are violated.
We then describe an algorithm for “unstructured lumigraph ren-
dering” (ULR), that generalizes both lumigraph and VDTM render-
ing. Our algorithm is designed specifically with the stated goals in
mind. As a result, our renderer behaves well with a wide variety
of inputs. These include source cameras that are not on a com-
mon plane, such as source images taken by moving forward into a
scene, a configuration that would be problematic for previous IBR
approaches.
It should be no surprise that our algorithm bears many resem-
blances to earlier approaches. The main contribution of our algo-
rithm is that, unlike previously published methods, it is designed to
meet a set of listed goals. Thus, it works well on a wide range of
differing inputs, from few images with an accurate geometric model
to many images with minimal geometric information.
2 Previous Work
The basic approach to view dependent texture mapping (VDTM) is
put forth by Debevec et al. [3] in their Fac¸ade image-based model-
ing and rendering system. Fac¸ade is designed to estimate geometric
models consistent with a small set of source images. As part of this
system, a rendering algorithm was developed where pixels from all
relevant cameras were combined and weighted to determine a view-
dependent texture for the derived geometric models. In later work,
Debevec et al [4] describe a real-time VDTM algorithm. In this
algorithm, each polygon in the geometric model maintains a “view
map” data structure that is used to quickly determine a set of three
input cameras that should be used to texture it. Like most real-time
VDTM algorithms, this algorithm uses hardware supported projec-
tive texture mapping [6] for efficiency.
At the other extreme, Levoy and Hanrahan [10] describe the light
field rendering algorithm, in which a large collection of images are
used to render novel views of a scene. This collection of images
is captured from cameras whose centers lie on a regularly sampled
two-dimensional plane. Light fields otherwise make few assump-
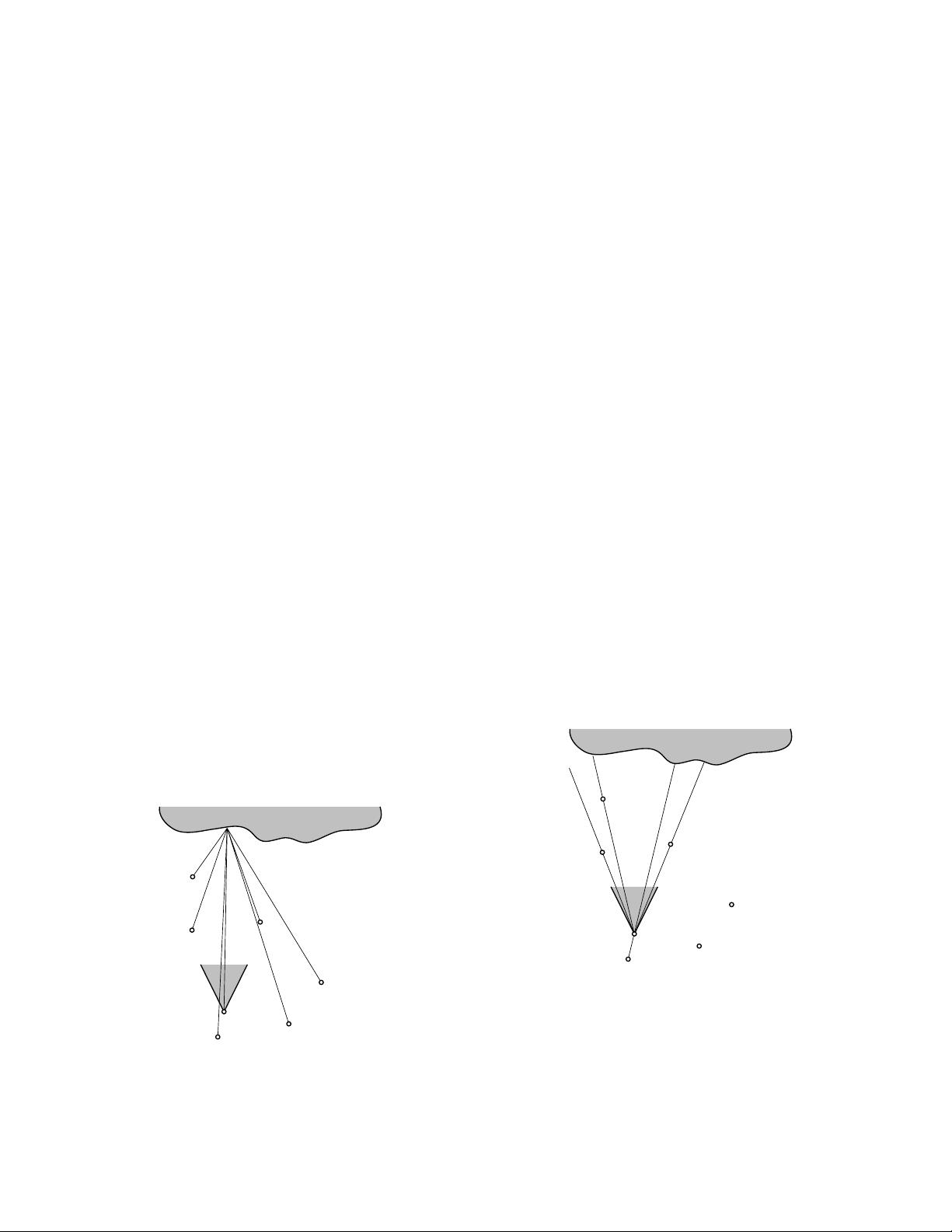
tions about the geometry of the scene. Gortler et al. [5] describe
a similar rendering algorithm called the lumigraph. In addition,
the authors of the lumigraph paper suggest many workarounds to
overcome limitations of the basic approach, including a “rebinning”
process to handle source images acquired from general camera po-
sitions and a “depth-correction” extension to allow for more ac-
剩余7页未读,继续阅读
资源评论


lvzhigao2008
- 粉丝: 0
- 资源: 6









最新资源
- screenrecorder-20241221-204839.mp4
- Screenshot_20241221-204051.png
- 自考计算机网络原理04741真题及答案2018-2020
- YOLO算法-垃圾箱检测数据集-214张图像带标签-垃圾桶.zip
- Hive存储压缩与Hive3性能优化-必看文档
- YOLO算法-施工管理数据集-7164张图像带标签-安全帽-装载机-挖掘机-平地机-移动式起重机-反光背心-工人-推土机-滚筒-哑巴卡车.zip
- YOLO算法-俯视视角草原绵羊检测数据集-4133张图像带标签-羊.zip
- YOLO算法-挖掘机数据集-2656张图像带标签-自卸卡车-挖掘机-轮式装载机.zip
- YOLO算法-火车-轨道-手推车数据集-3793张图像带标签-火车-轨道-手推车.zip
- YOLO算法-垃圾数据集-6561张图像带标签-纸张-混合的-餐厅快餐.zip
- 技术报告:大型语言模型在压力下战略欺骗用户的行为研究
- YOLO算法-水泥路面裂纹检测数据集-5005张图像带标签-裂纹.zip
- YOLO算法-垃圾数据集-568张图像带标签-纸张-纸箱-瓶子.zip
- YOLO算法-施工设备数据集-2000张图像带标签-装载机-挖掘机-平地机-移动式起重机-推土机-滚筒-哑巴卡车.zip
- 防火墙系统项目源代码全套技术资料.zip
- 西门子V90效率倍增-伺服驱动功能库详解-循环通信库 DRIVELib.mp4
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


