

Attention Is All You Need
Ashish Vaswani
∗
Google Brain
avaswani@google.com
Noam Shazeer
∗
Google Brain
noam@google.com
Niki Parmar
∗
Google Research
nikip@google.com
Jakob Uszkoreit
∗
Google Research
usz@google.com
Llion Jones
∗
Google Research
llion@google.com
Aidan N. Gomez
∗ †
University of Toronto
aidan@cs.toronto.edu
Łukasz Kaiser
∗
Google Brain
lukaszkaiser@google.com
Illia Polosukhin
∗ ‡
illia.polosukhin@gmail.com
Abstract
The dominant sequence transduction models are based on complex recurrent or
convolutional neural networks that include an encoder and a decoder. The best
performing models also connect the encoder and decoder through an attention
mechanism. We propose a new simple network architecture, the Transformer,
based solely on attention mechanisms, dispensing with recurrence and convolutions
entirely. Experiments on two machine translation tasks show these models to
be superior in quality while being more parallelizable and requiring significantly
less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-
to-German translation task, improving over the existing best results, including
ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task,
our model establishes a new single-model state-of-the-art BLEU score of 41.8 after
training for 3.5 days on eight GPUs, a small fraction of the training costs of the
best models from the literature. We show that the Transformer generalizes well to
other tasks by applying it successfully to English constituency parsing both with
large and limited training data.
1 Introduction
Recurrent neural networks, long short-term memory [
13
] and gated recurrent [
7
] neural networks
in particular, have been firmly established as state of the art approaches in sequence modeling and
∗
Equal contribution. Listing order is random. Jakob proposed replacing RNNs with self-attention and started
the effort to evaluate this idea. Ashish, with Illia, designed and implemented the first Transformer models and
has been crucially involved in every aspect of this work. Noam proposed scaled dot-product attention, multi-head
attention and the parameter-free position representation and became the other person involved in nearly every
detail. Niki designed, implemented, tuned and evaluated countless model variants in our original codebase and
tensor2tensor. Llion also experimented with novel model variants, was responsible for our initial codebase, and
efficient inference and visualizations. Lukasz and Aidan spent countless long days designing various parts of and
implementing tensor2tensor, replacing our earlier codebase, greatly improving results and massively accelerating
our research.
†
Work performed while at Google Brain.
‡
Work performed while at Google Research.
31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
arXiv:1706.03762v5 [cs.CL] 6 Dec 2017
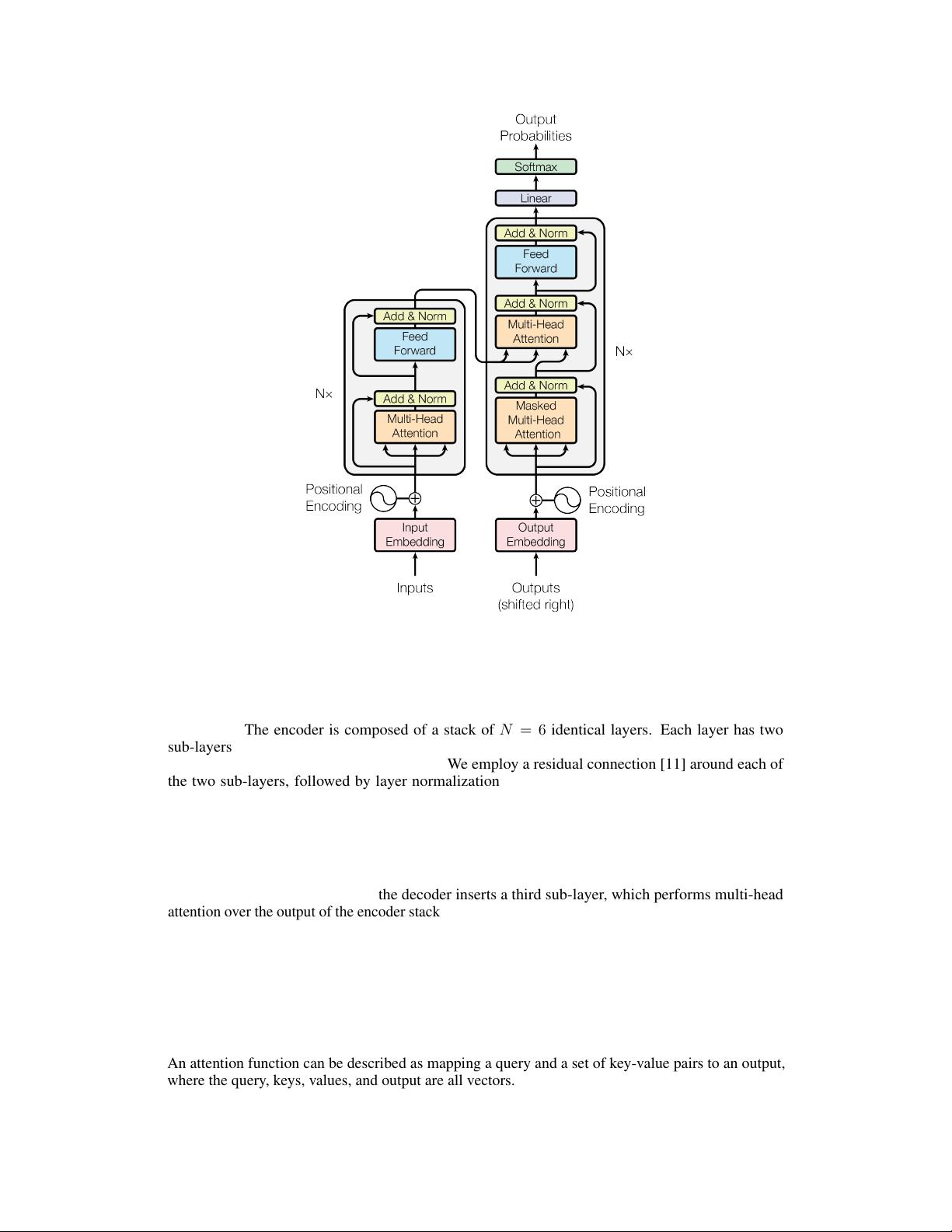
Transformer是第一种完全依赖attention的序列转
换模型。使用与multi-headed self-attention结合
的encode-decode架构替换迭代层。

剩余14页未读,继续阅读
资源评论


lucky_chaichai
- 粉丝: 7189
- 资源: 5









最新资源
- 基于单片机智能电子密码锁设计(proteus仿真+程序) (1)输入密码:通过4*4矩阵键盘输入6位密码; (2)修改密码:可以对初始密码进行修改; (3)显示电路:使用LCD1602显示密码锁运行状
- 微电网分层控制中二次控制,集中控制,分布式协调控制,事件触发,运行效果良好
- 三菱Q系列L系列程序 三菱L程序,主站L02PLC QX42.QY42P等输入输出模块.L系列定位控制模块 3C-FPC组装机 三菱JE系列伺服控制,绝对定位,X,Y,Z,R模组取
- MATLAB代码:计及碳捕集电厂灵活运行方式及需求响应的综合能源系统日前调度模型 仿真平台:MATLAB yalmip+cplex 包含新能源消纳、热电联产、电锅炉、储能电池、天然气、碳捕集CCS、计
- 新能源汽车车载双向OBC,PFC,LLC,V2G 双向 充电 新能源汽车车载双向OBC,PFC,LLC,V2G 双向 充电桩 电动汽车 车载充电机 充放电机 MATLAB仿真模型 (1)基于V2G技术
- 潮流追踪法,采用牛拉法计算任意拓扑结构系统网损,支路功率,考虑分布式电源接入情况,采用潮流追踪法计算负荷和分布式电源进行网损分摊
- 三相PWM整流器仿真模型 包括基于开关表的直接功率控制,滞环电流控制,有限集模型预测直接功率控制,有限集模型预测电流控制,均为输入三相对称交流电,220V 50Hz,直流侧输出760V,且直流输出电压
- 17 16届智能车十六届国二代码源程序,基础四轮摄像头循迹识别判断 逐飞tc264龙邱tc264都有 能过十字直角三岔路环岛元素均能识别,功能全部能实现 打包出的龙邱逐飞都有,代码移植行好,有基础的
- 西门子1500PLC程序 BMS系统 医药洁净室程序 串级PID 温度误差正负0.2(控温湿度强烈推荐) 程序有详细注释,很方便能看懂; 在运行医药厂房BMS PLC程序; 串级PID,分程调节,控
- 西门子224 XP程序源码,包括pcb,原理图 ,bom PLC 224 全套生产量产方案 非常具有参考价值
- matlab 图像分割gui可视化代码 ,代码功能有 图像灰度化,显示灰度直方图,阈值分割法,区域分割法,梯度边缘分割法,canny边缘分割,拉普拉斯边缘分割,并且可以进行各个方法的比较
- 电动汽车备用能力分析 对电动汽车备用能力的评估需置于合理的、计及用户响应意愿的市场机制下来考察 首先设计出兼顾系统调控需求与用户出行需求的充(放)电合约机制,提出了EV短时备用能力计算方法和响应电价
- Agv伺服驱动器方案开发,本人在AGV行业三年,有丰富的行业经验
- Comsol金属开口环倍频SHG转效率计算
- (断开git服务器合并本地两个分支代码)Git操作技巧:本地合并两个分支代码详细步骤与冲突解决方法
- 交错并联Boost PFC仿真电路模型,控制方法采用输出电压外环,电感电流内环的双闭环PI控制方式 控制效果:交流侧输入电流畸变小,波形良好,输出直流电压可完好跟随给定,两相电感电流均流很好,如展示
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


