Spark大数据分析平台 讲师 冰风影
DATAGURU专业数据分析社区
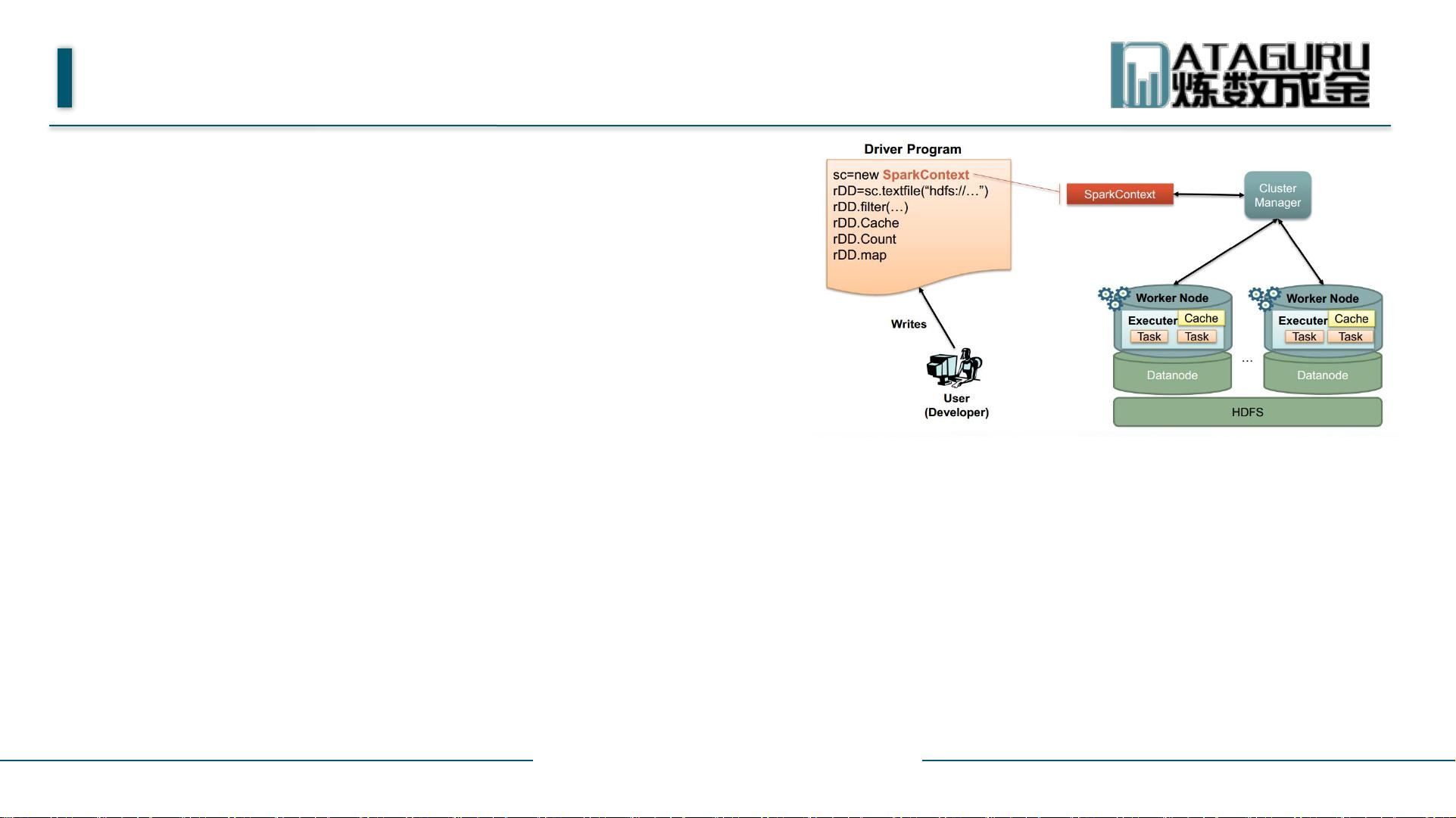
Spark编程模型
Spark应用程序由两部分组成
Driver
Executor
基本概念
Application:Spark的应用程序,包含一个Driver program和若干个Executor。
SparkContext:Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor
Driver program:运行Application的main()函数并且创建SparkContext,通常SparkContext代表driver program
Executor:是Application运行在Work node上的一个迚程,该迚程负责运行Task,并且负责将数据存在内存或者磁盘上;每个
Application都会申请各自的Executors来处理
Cluster Manager :在集群上获取资源的外部服务(例如:Standalone、Mesos、Yarn)
Work Node:集群中任何可以运行Application代码的节点,运行一个或者多个Executor迚程

















