在计算机科学中,汇编语言是一种低级编程语言,它直接与计算机的硬件架构相关联。本文主要讨论了多字节数据在存储器中的存储顺序,以及汇编语言中变量的地址属性。
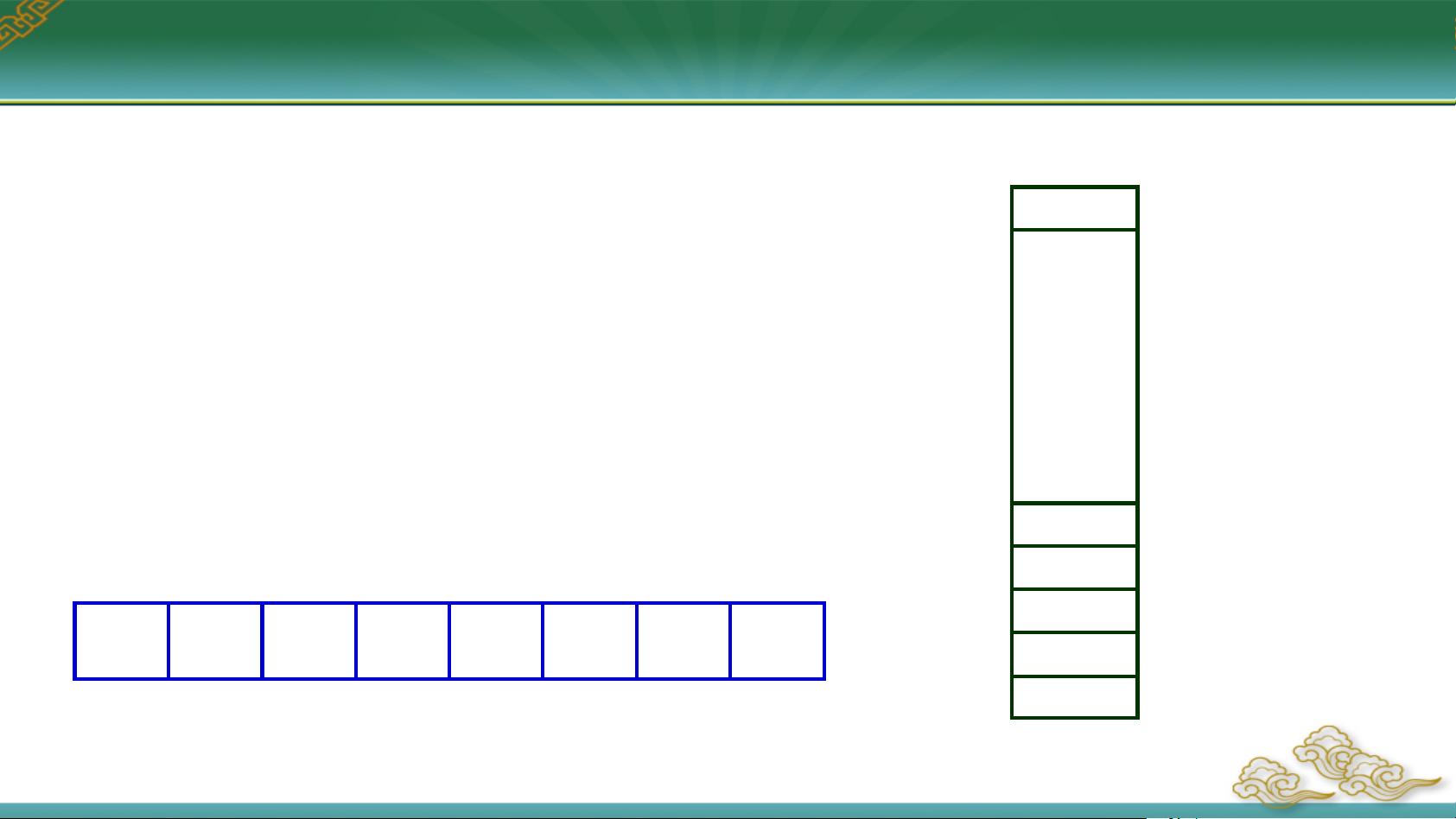
我们来看多字节数据的存储顺序。在计算机内存中,最小的存储单位是二进制位,即比特位(bit),而最常见的存储单位是字节(Byte),由8个二进制位组成。每个字节都有一个唯一的存储器地址。当存储多字节数据时,有两种主要的存储方式:小端存储(Little Endian)和大端存储(Big Endian)。小端方式下,低字节数据保存在低地址存储单元,高字节数据保存在高地址存储单元;相反,大端方式则是高字节数据在低地址,低字节数据在高地址。例如,对于一个字节量数据`38323139h`,在小端存储中,它的存储顺序是`39H, 38H, 32H, 31H`,而在大端存储中,则是`31H, 32H, 38H, 39H`。80x86架构的处理器,如Intel和AMD的CPU,使用的是小端存储方式。
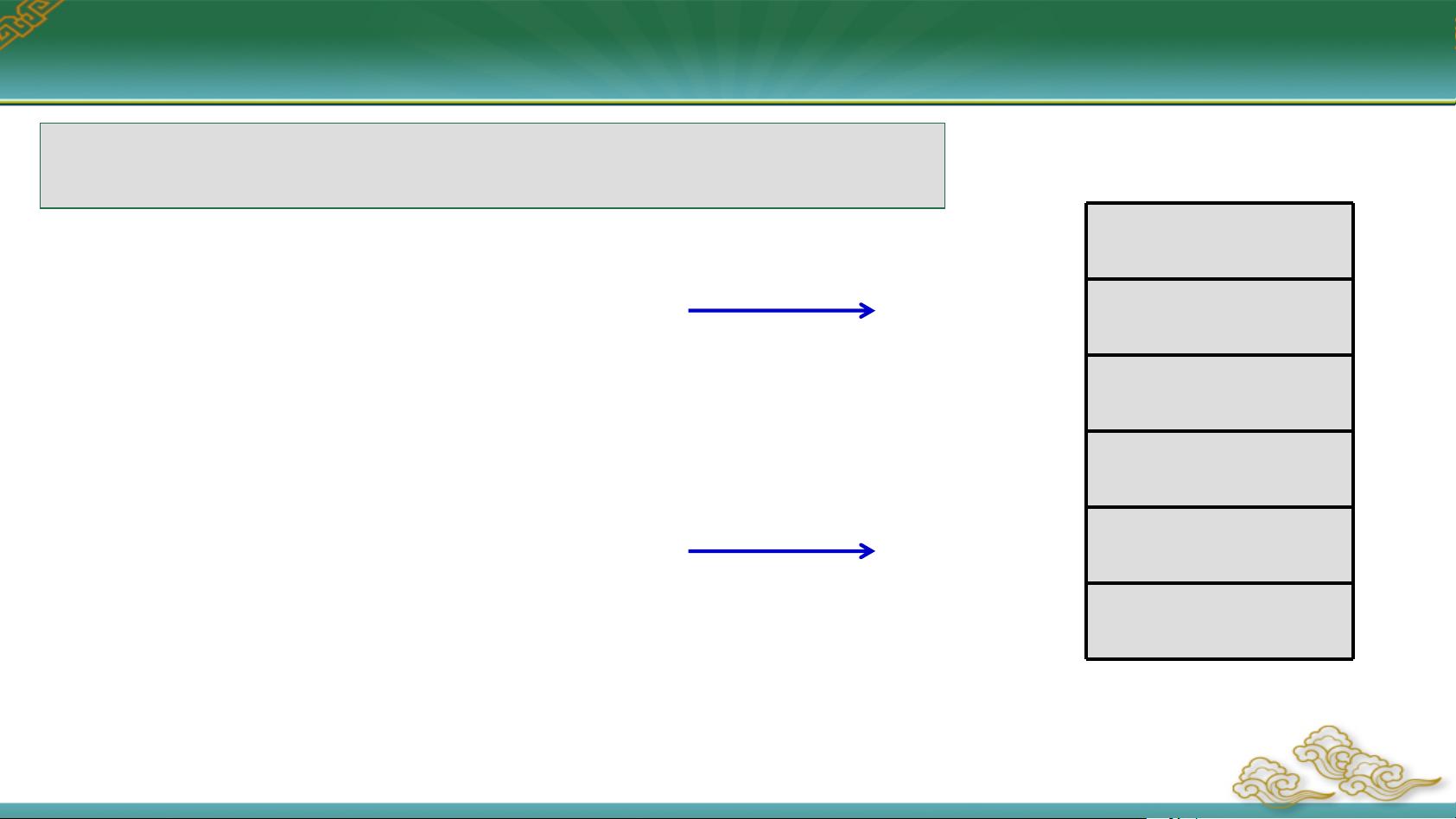
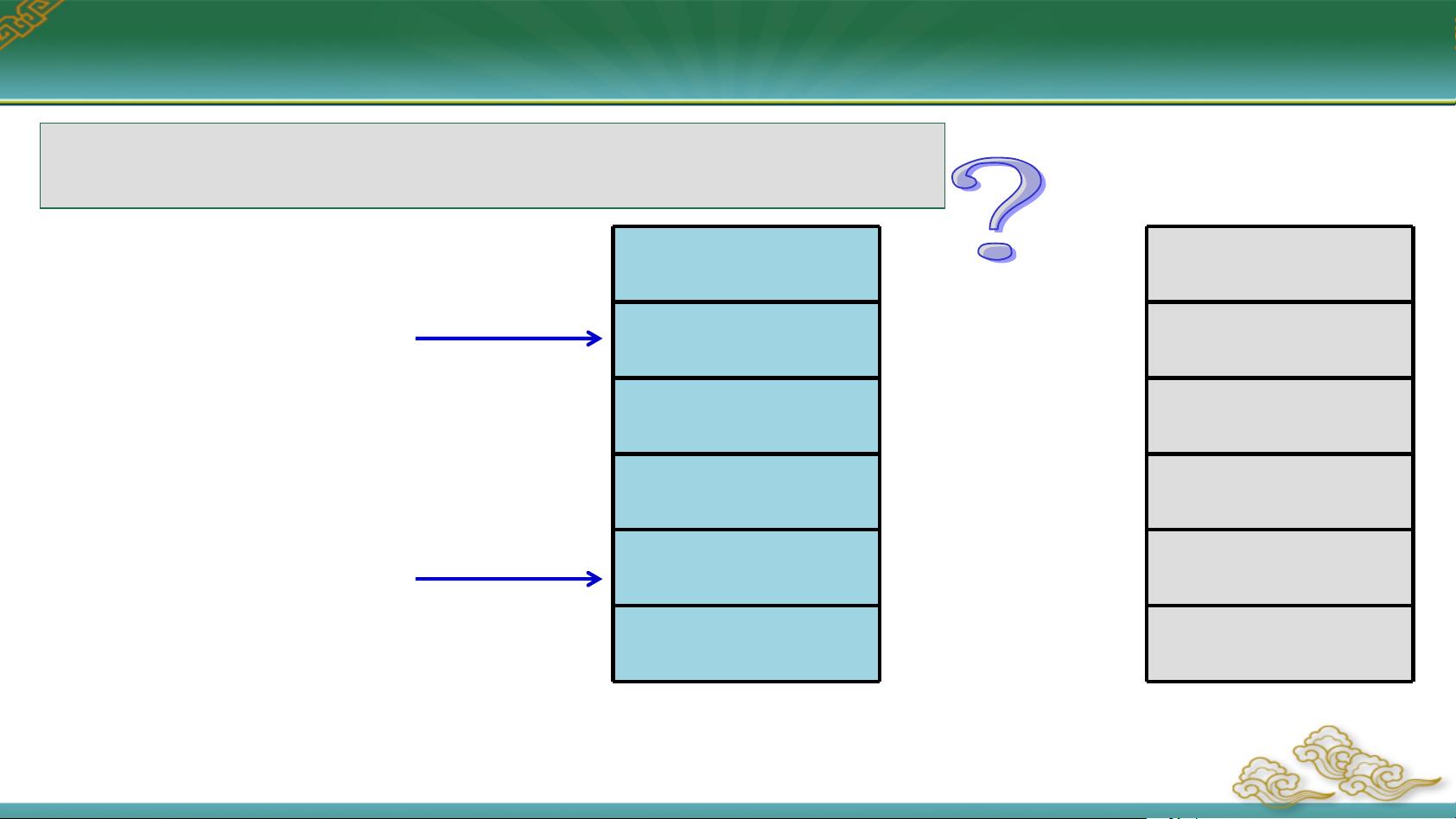
接下来,我们讨论变量的地址属性。在汇编语言中,定义变量不仅分配存储空间,还可以赋予初始值并创建变量名。变量有两类属性:地址属性和类型属性。地址属性是指变量所在的存储单元的逻辑地址,由段基地址和偏移地址组成。我们可以通过地址操作符来访问这些属性,比如使用方括号`[]`表示存储器地址,`$`返回当前偏移地址,`OFFSET` 返回变量的偏移地址,而 `SEG` 返回段基地址。在实际编程中,变量名可以直接代表其偏移地址,例如`bvar`等同于`[bvar]`,`bvar+1`则指向`bvar`的下一个字节。
在示例程序中,可以看到如何通过汇编指令操作变量地址。例如,`mov al, bvar`指令将`bvar`的第一个字节数据加载到`AL`寄存器中,`mov ah, bvar+1`则将`bvar`的第二个字节数据加载到`AH`寄存器中。此外,通过计算表达式如`$-array`可以得到变量`array`占用的存储空间大小,进一步除以类型值来确定变量个数。
理解多字节数据的存储顺序和变量的地址属性是编写汇编语言程序的关键。这些基础知识对于编写高效的底层代码,特别是处理硬件交互和内存管理的场合至关重要。在实际应用中,程序员需要根据系统的存储方式(小端或大端)正确地访问和处理多字节数据,同时充分利用变量的地址属性进行内存操作。