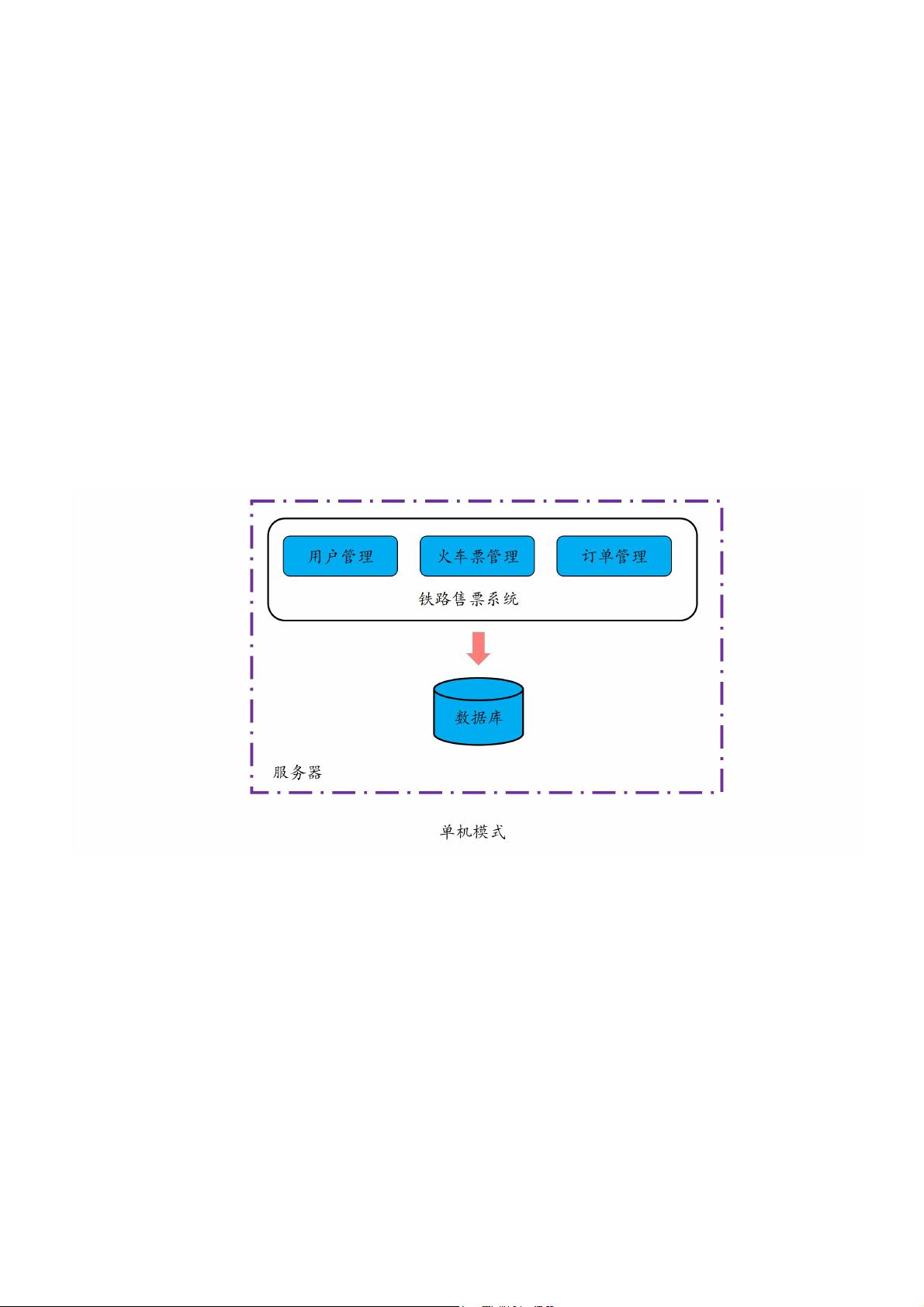
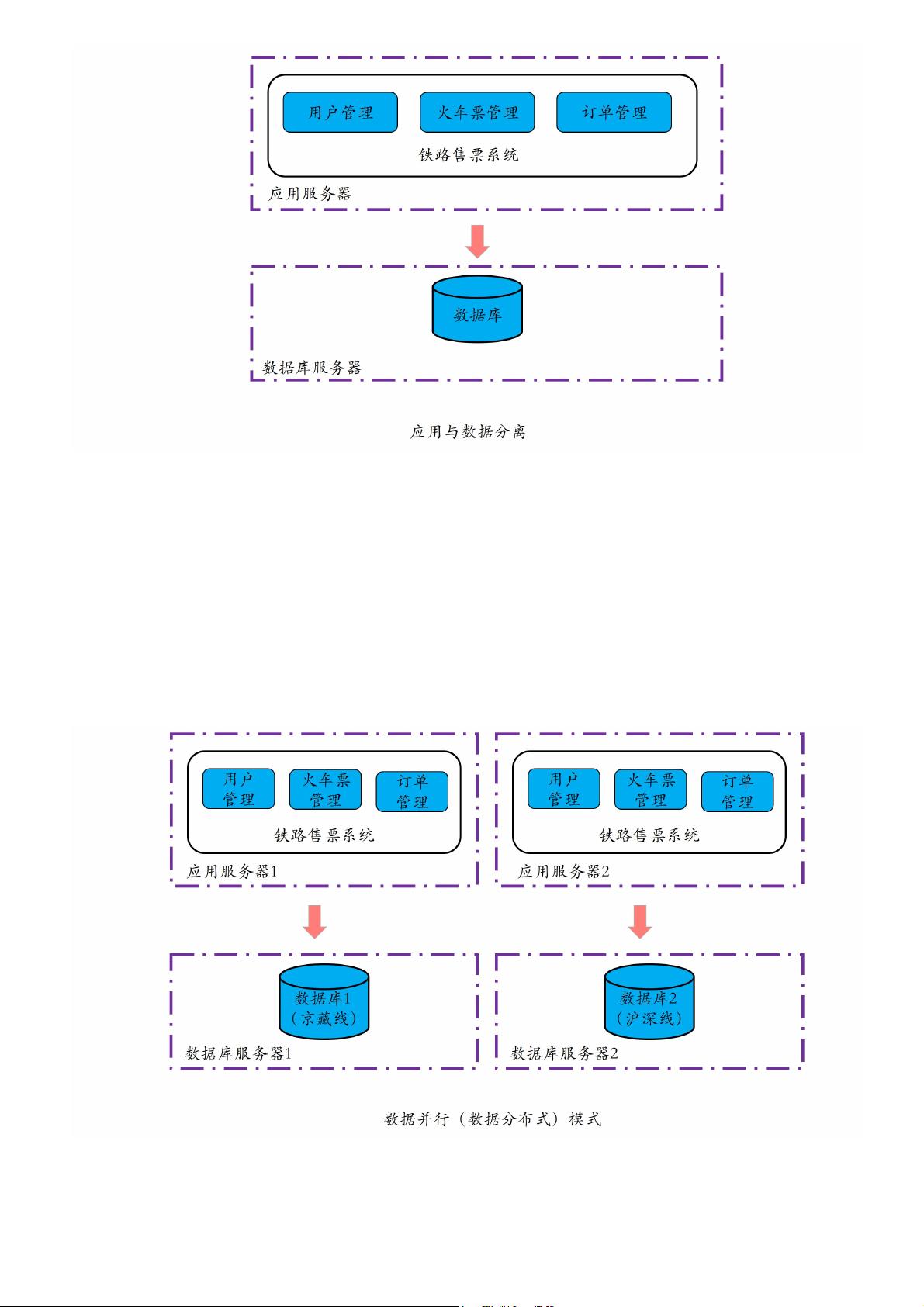
择,比方说所有业务服务器共用一个数据库服务器,而不一定真的需要去进行数据库拆分。
可以看出,在数据并行或数据分布式模式中,每台计算机都是全量地从头到尾一条龙地执行
一个程序,就像一个全能的铁道游击队战士。所以,你也可以将这种模式形象地理解成游击
队模式,就和铁道游击队插曲的歌词有点类似:“我们扒飞车那个搞机枪,撞火车那个炸桥
梁……”
这种模式的好处是,可以利用多台计算机并行处理多个请求,使得我们可以在相同的时间内
完成更多的请求处理,解决了单机模式的计算效率瓶颈问题。但这种模式仍然存在如下几个
问题,在实际应用中,我们需要对其进行相应的优化:
从上面介绍可以看出,数据并行模式实现了多请求并行处理,但如果单个请求特别复杂,比
方说需要几天甚至一周时间的时候,数据并行模式的整体计算效率还是不够高。
由此可见,数据并行模式的主要问题是:对提升单个任务的执行性能及降低时延无效。
集团军模式:任务并行或任务分布式
那么,有没有办法可以提高单个任务的执行性能,或者缩短单个任务的执行时间呢?答案是
肯定的。任务并行(也叫作任务分布式)就是为解决这个问题而生的。那什么是任务并行
呢?
任务并行指的是,将单个复杂的任务拆分为多个子任务,从而使得多个子任务可以在不同的
计算机上并行执行。
相同的应用部署到不同的服务器上,当大量用户请求过来时,如何能比较均衡地转发到不
同的应用服务器上呢?解决这个问题的方法是设计一个负载均衡器,我会在”分布式高可
靠“模块与你讲述负载均衡的相关原理。
当请求量较大时,对数据库的频繁读写操作,使得数据库的 IO 访问成为瓶颈。解决这个
问题的方式是读写分离,读数据库只接收读请求,写数据库只接收写请求,当然读写数据
库之间要进行数据同步,以保证数据一致性。
当有些数据成为热点数据时,会导致数据库访问频繁,压力增大。解决这个问题的方法是
引入缓存机制,将热点数据加载到缓存中,一方面可以减轻数据库的压力,另一方面也可
以提升查询效率。