
[](https://pypi.python.org/pypi/synonyms) [](https://pypi.python.org/pypi/synonyms/) [](https://pypi.org/pypi/synonyms/) [](https://www.cskefu.com/licenses/v1.html "开源许可协议") [](https://pypi.org/pypi/synonyms/)
# Synonyms
Chinese Synonyms for Natural Language Processing and Understanding.
更好的中文近义词:聊天机器人、智能问答工具包。
`synonyms`可以用于自然语言理解的很多任务:文本对齐,推荐算法,相似度计算,语义偏移,关键字提取,概念提取,自动摘要,搜索引擎等。
为提供稳定、可靠、长期优化的服务,Synonyms 改为使用 [春松许可证, v1.0](https://www.cskefu.com/licenses/v1.html) 并针对机器学习模型的下载进行收费,详见[证书商店](https://store.chatopera.com/product/syns001)。之前的贡献者(突出贡献的代码贡献者),可与我们联系,讨论收费问题。-- [Chatopera Inc.](https://www.chatopera.com) @ Oct. 2023
# Table of Content:
- [Install](https://github.com/chatopera/Synonyms#welcome)
- [Usage](https://github.com/chatopera/Synonyms#usage)
- [Quick Get Start](https://github.com/chatopera/Synonyms#quick-get-start)
- [Valuation](https://github.com/chatopera/Synonyms#valuation)
- [Benchmark](https://github.com/chatopera/Synonyms#benchmark)
- [Statement](https://github.com/chatopera/Synonyms#statement)
- [References](https://github.com/chatopera/Synonyms#references)
- [Frequently Asked Questions](https://github.com/chatopera/Synonyms#frequently-asked-questions-faq)
- [License](https://github.com/chatopera/Synonyms#license)
# Welcome
Follow steps below to install and activate packages.
## 1/3 Install Sourcecodes Package
```bash
pip install -U synonyms
```
当前稳定版本 v3.x。
## 2/3 Config license id
Synonyms's machine learning model package(s) requires a License from [Chatopera License Store](https://store.chatopera.com/product/syns001), first purchase a License and get the `license id` from **Licenses** page on Chatopera License Store(`license id`:在证书商店,证书详情页,点击【复制证书标识】).
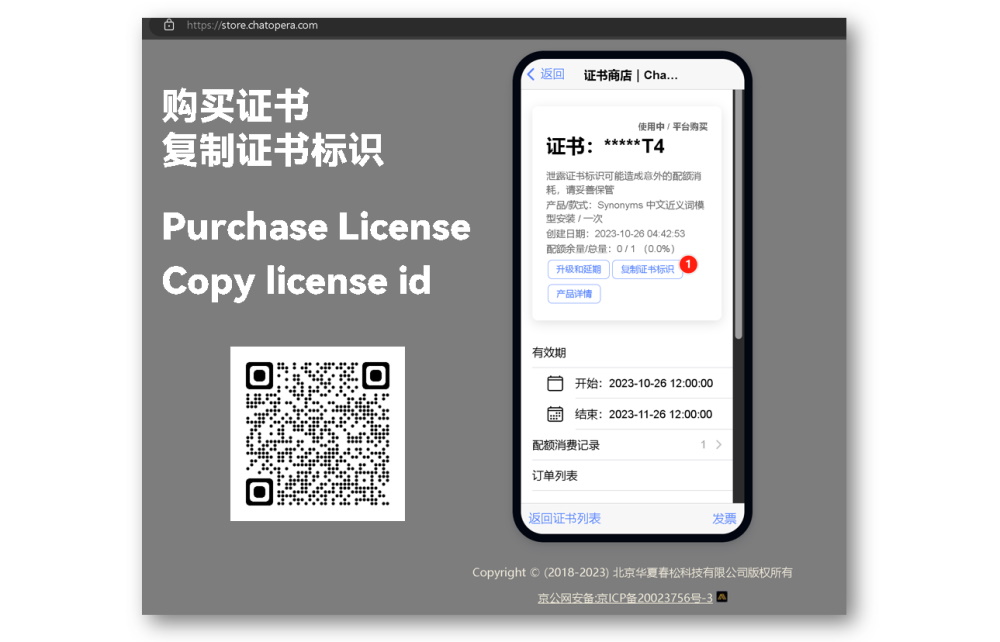
Secondly, set environment variable in your terminal or shell scripts as below.
* For Shell Users
e.g. Shell, CMD Scripts on Linux, Windows, macOS.
```bash
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
## e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
## 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
## 2/2 PowerShell
$env:SYNONYMS_DL_LICENSE='YOUR_LICENSE'
```
* For Python Code Users
Jupyter Notebook, etc.
```python
import os
os.environ["SYNONYMS_DL_LICENSE"] = "YOUR_LICENSE"
_licenseid = os.environ.get("SYNONYMS_DL_LICENSE", None)
print("SYNONYMS_DL_LICENSE=", _licenseid)
```

**提示:安装后初次使用会下载词向量文件,下载速度取决于网络情况。**
## 3/3 Download Model Package
Last, download the model package by command or script -
```bash
python -c "import synonyms; synonyms.display('能量')" # download word vectors file
```

## Usage
支持使用环境变量配置分词词表和 word2vec 词向量文件。
| 环境变量 | 描述 |
| ----------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| _SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN_ | 使用 word2vec 训练的词向量文件,二进制格式。 |
| _SYNONYMS_WORDSEG_DICT_ | 中文分词[**主字典**](https://github.com/fxsjy/jieba#%E5%BB%B6%E8%BF%9F%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6),格式和使用[参考](https://github.com/fxsjy/jieba#%E8%BD%BD%E5%85%A5%E8%AF%8D%E5%85%B8) |
| _SYNONYMS_DEBUG_ | ["TRUE"\|"FALSE"], 是否输出调试日志,设置为 “TRUE” 输出,默认为 “FALSE” |
### synonyms#nearby(word [, size = 10])
```python
import synonyms
print("人脸: ", synonyms.nearby("人脸"))
print("识别: ", synonyms.nearby("识别"))
print("NOT_EXIST: ", synonyms.nearby("NOT_EXIST"))
```
`synonyms.nearby(WORD [,SIZE])`返回一个元组,元组中包含两项:`([nearby_words], [nearby_words_score])`,`nearby_words`是 WORD 的近义词们,也以 list 的方式存储,并且按照距离的长度由近及远排列,`nearby_words_score`是`nearby_words`中**对应位置**的词的距离的分数,分数在(0-1)区间内,越接近于 1,代表越相近;`SIZE` 是返回词汇数量,默认 10。比如:
```python
synonyms.nearby(人脸, 10) = (
["图片", "图像", "通过观察", "数字图像", "几何图形", "脸部", "图象", "放大镜", "面孔", "Mii"],
[0.597284, 0.580373, 0.568486, 0.535674, 0.531835, 0.530
095, 0.525344, 0.524009, 0.523101, 0.516046])
```
在 OOV 的情况下,返回 `([], [])`,目前的字典大小: 435,729。
### synonyms#compare(sen1, sen2 [, seg=True])
两个句子的相似度比较
```python
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms.compare(sen1, sen2, seg=True)
```
其中,参数 seg 表示 synonyms.compare 是否对 sen1 和 sen2 进行分词,默认为 True。返回值:[0-1],并且越接近于 1 代表两个句子越相似。
```python
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0
```
### synonyms#display(word [, size = 10])
以友好的方式打印近义词,方便调试,`display(WORD [, SIZE])`调用了 `synonyms#nearby` 方法。
```python
>>> synonyms.display("飞机")
'飞机'近义词:
1. 飞机:1.0
2. 直升机:0.8423391
3. 客机:0.8393003
4. 滑翔机:0.7872388
5. 军用飞机:0.7832081
6. 水上飞机:0.77857226
7. 运输机:0.7724742
8. 航机:0.7664748
9. 航空器:0.76592904
10. 民航机:0.74209654
```
`SIZE` 是打印词汇表的数量,默认 10。
### synonyms#describe()
打印当前包的描述信息:
```
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
```
### synonyms#v(word)
获得一个词语的向量,该向量为 numpy 的 array,当该词语是未登录词时,抛出 KeyError 异常。
```python
>>> synonyms.v("飞机")
array([-2.412167 , 2.2628384 , -7.0214124 , 3.9381874 , 0.8219283 ,
-3.2809453 , 3.8747153 , -5.217062 , -2.2786229 , -1.2572327 ],
dtype=float32)
```
### synonyms#sv(sentence, ignore=False)
获得一个分词后句子的向量,向量以 BoW 方式组成
```python
sentence: 句子是分词后通过空格联合起来
ignore: 是否忽略OOV,False时,随机生成一个向量
```
### synonyms#seg(sentence)
中文分词
```python
synonyms.seg("中文近义词工具包")
```
分词结果,由两个 list 组成的元组,分别是单词和对应
 《人工智能》--中文近义词:聊天机器人,智能问答工具包.zip (36个子文件)
《人工智能》--中文近义词:聊天机器人,智能问答工具包.zip (36个子文件)  synonyms
synonyms  utils.py 9KB __init__.py 267B word2vec.py 11KB data
utils.py 9KB __init__.py 267B word2vec.py 11KB data  stopwords.txt 11KB vocab.txt 9.4MB synonyms.py 12KB .travis.yml 856B setup.py 2KB .github ISSUE_TEMPLATE.md 117B PULL_REQUEST_TEMPLATE.md 1KB benchmark.py 2KB assets
stopwords.txt 11KB vocab.txt 9.4MB synonyms.py 12KB .travis.yml 856B setup.py 2KB .github ISSUE_TEMPLATE.md 117B PULL_REQUEST_TEMPLATE.md 1KB benchmark.py 2KB assets  screenshot_20231124180125.png 49KB
screenshot_20231124180125.png 49KB sentence_precision.jpg 33KB roc_curve_eulidean0.8+unigram0.2+POS.png 17KB 1.png 58KB syn_order_post.jpg 110KB 64531083-3199aa80-d341-11e9-86cd-3a3ed860b14b.png 411KB 6.png 185KB pr_hresholds_eulidean0.8+unigram0.2+POS.png 18KB 5.png 165KB 4.png 100KB
sentence_precision.jpg 33KB roc_curve_eulidean0.8+unigram0.2+POS.png 17KB 1.png 58KB syn_order_post.jpg 110KB 64531083-3199aa80-d341-11e9-86cd-3a3ed860b14b.png 411KB 6.png 185KB pr_hresholds_eulidean0.8+unigram0.2+POS.png 18KB 5.png 165KB 4.png 100KB 3.gif 2.8MB pr_curve_eulidean0.8+unigram0.2.png 21KB 2.png 418KB VALUATION.md 1KB LICENSE 617B Requirements.txt 14B CHANGELOG.md 2KB CODE_OF_CONDUCT.md 3KB .gitignore 161B setup.cfg 39B demo.py 6KB README.md 15KB scripts test.sh 426B pypi.sh 642B package.sh 758B
3.gif 2.8MB pr_curve_eulidean0.8+unigram0.2.png 21KB 2.png 418KB VALUATION.md 1KB LICENSE 617B Requirements.txt 14B CHANGELOG.md 2KB CODE_OF_CONDUCT.md 3KB .gitignore 161B setup.cfg 39B demo.py 6KB README.md 15KB scripts test.sh 426B pypi.sh 642B package.sh 758B资源评论


季风泯灭的季节
- 粉丝: 1908
- 资源: 3370









最新资源
- YOLOV3-NANO-Tensorflow.zip
- YoloV3+MobileNetV2检测库在caffe中的纯C++实现.zip
- java毕业设计-基于SSM的电影推荐网站【代码+论文+PPT】.zip
- Yolov3 采用全新的 TensorFlow 2.0 API 实现(训练和预测).zip
- yolov3 的注释和规范.zip
- 糖尿病数据集(csv)
- YOLOv3 在 TensorFlow 1.1X 中的实现.zip
- 系统学习linux命令
- java毕业设计-基于SSM的党务政务服务热线平台【代码+论文+PPT】.zip
- YOLOv3 在 GPU 上使用自己的数据进行训练 YOLOv3 的 Keras 实现.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


