

2008-11-04
Hadoop分布式文件系统源代码详细解析(一)
关键字 : 分布式 云计算
经济不行啦,只好潜心研究技术。
Google 的核心竞争技术是它的计算平台。 Google 的大牛们用了下面 5 篇文章,介绍了它们的计算设施。
GoogleCluster : http://research.google.com/archive/googlecluster.html
Chubby:http://labs.google.com/papers/chubby.html
GFS:http://labs.google.com/papers/gfs.html
BigTable :http://labs.google.com/papers/bigtable.html
MapReduce:http://labs.google.com/papers/mapreduce.html
很快, Apache上就出现了一个类似的解决方案,目前它们都属于 Apache的 Hadoop项目,对应的分别是:
Chubby-->ZooKeeper
GFS-->HDFS
BigTable-->HBase
MapReduce-->Hadoop
目前,基于类似思想的 Open Source 项目还很多,如 Facebook 用于用户分析的 Hive 。
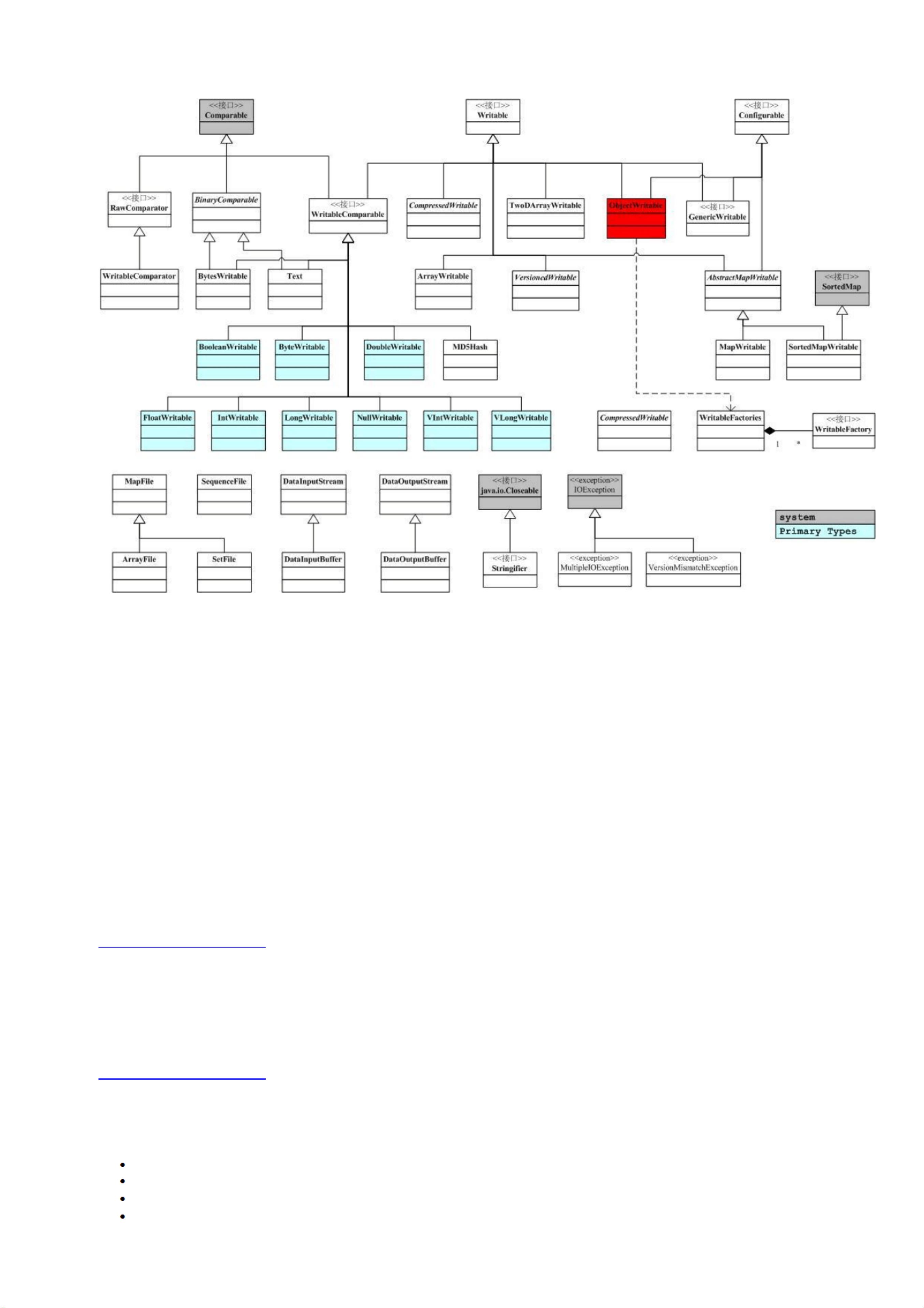
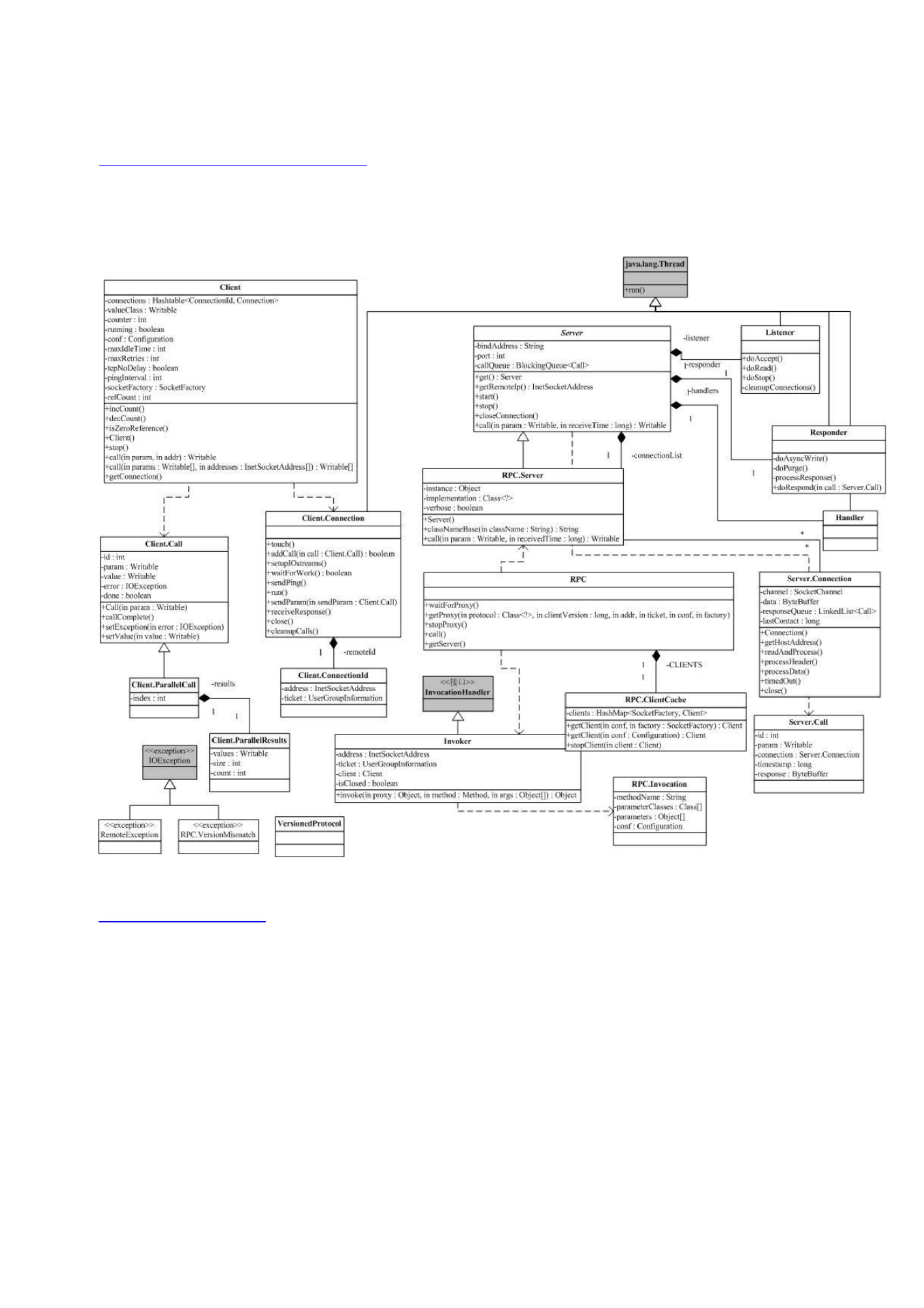
HDFS作为一个分布式文件系统, 是所有这些项目的基础。 分析好 HDFS,有利于了解其他系统。 由于 Hadoop的 HDFS和 MapReduce
是同一个项目,我们就把他们放在一块,进行分析。
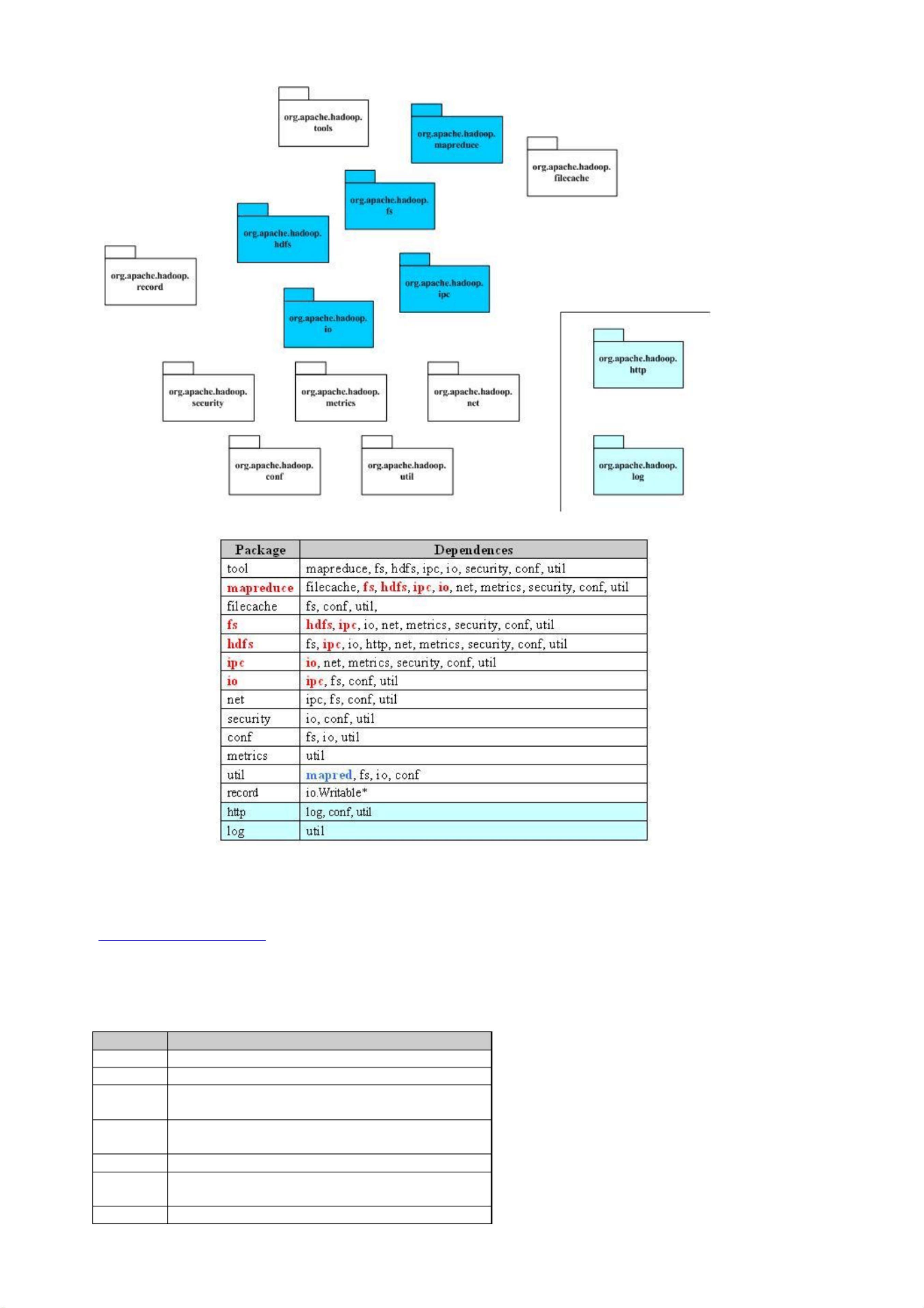
下图是 MapReduce整个项目的顶层包图和他们的依赖关系。 Hadoop包之间的依赖关系比较复杂,原因是 HDFS提供了一个分布
式文件系统,该系统提供 API,可以屏蔽本地文件系统和分布式文件系统,甚至象 Amazon S3这样的在线存储系统。这就造成
了分布式文件系统的实现,或者是分布式文件系统的底层的实现,依赖于某些貌似高层的功能。功能的相互引用,造成了蜘蛛
网型的依赖关系。一个典型的例子就是包 conf ,conf 用于读取系统配置,它依赖于 fs ,主要是读取配置文件的时候,需要使
用文件系统,而部分的文件系统的功能,在包 fs 中被抽象了。
Hadoop的关键部分集中于图中蓝色部分,这也是我们考察的重点。

剩余49页未读,继续阅读
资源评论


ll17770603473
- 粉丝: 0
- 资源: 6万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- xxs靶机,放入vm中使用
- BLE蓝牙单片机CC2540、CC2541带OSAL操作系统的例程-LED跑马灯.zip
- BLE蓝牙单片机CC2540、CC2541裸机简易C语言程序开发之系统睡眠唤醒-中断唤醒.zip
- BLE蓝牙单片机CC2540、CC2541裸机简易C语言程序开发之系统睡眠唤醒-定时器唤醒.zip
- BLE蓝牙单片机CC2540、CC2541裸机简易C语言程序开发之温湿度传感器DHT11.zip
- BLE蓝牙单片机CC2540、CC2541裸机简易C语言程序开发之温度传感器DS18B20.zip
- 机器学习预处理-表格数据的空值处理-py工程
- 基于OpenCV的机器视觉技术,对集会中的观众场景进行光流分析
- AN11801正版标准
- 实验四-运输层协议实验.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


