

1. Introduction
2. WebMagic概览
i. 设计思想
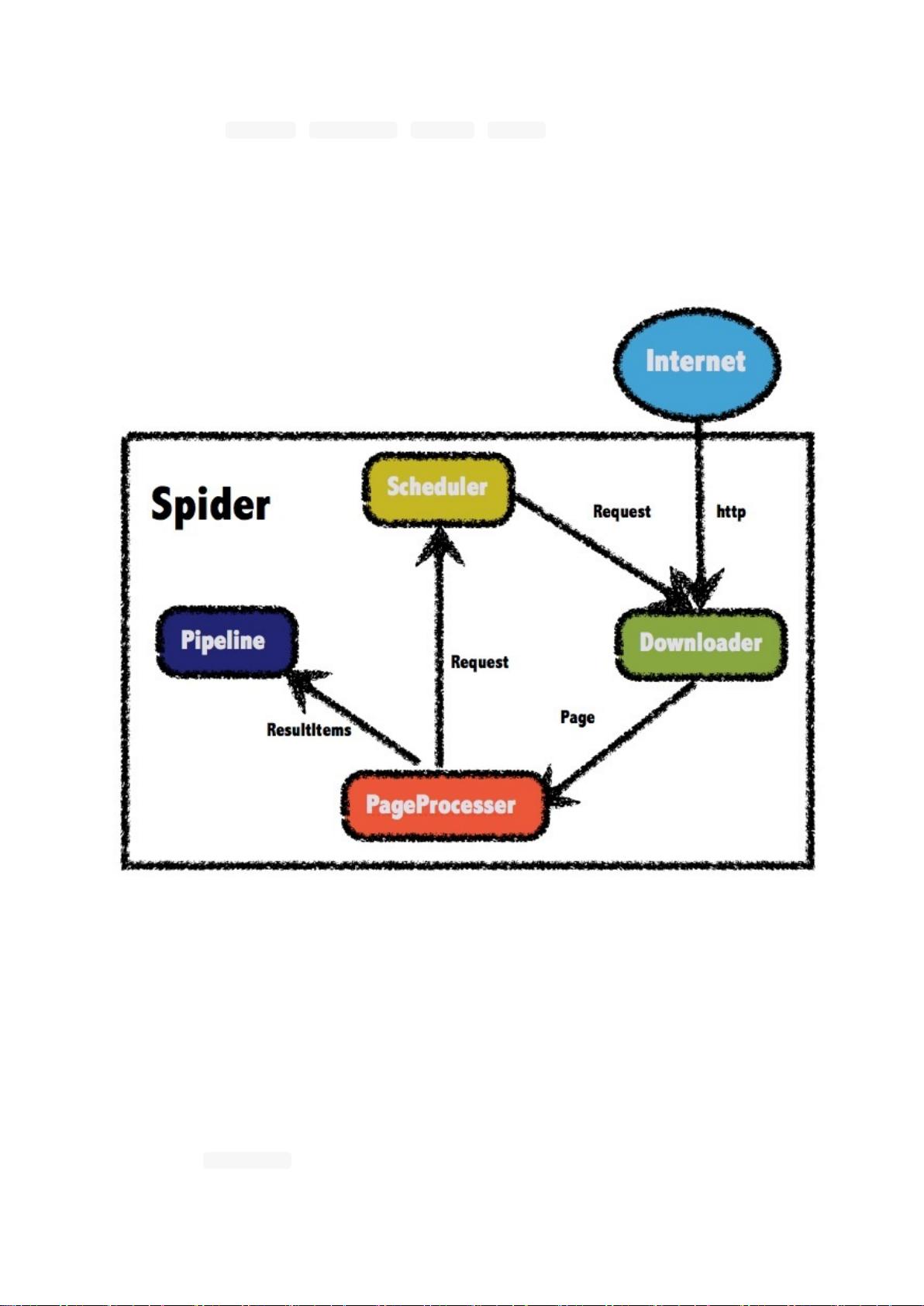
ii. 总体架构
iii. 项目组成
3. 快速开始
i. 添加依赖
ii. 不使用Maven
iii. 编写第一个爬虫
4. 下载和编译源码
i. 下载源码
ii. 导入项目
iii. 编译和执行源码
5. 编写基本的爬虫
i. 实现PageProcessor
ii. 使用Selectable的链式API
iii. 保存结果
iv. 爬虫的配置、启动和终止
v. Jsoup与Xsoup
vi. 爬虫的监控
6. 使用注解编写爬虫
i. 编写Model类
ii. TargetUrl与HelpUrl
iii. 使用ExtractBy进行抽取
iv. 在类上使用ExtractBy
v. 结果的类型转换
vi. 一个完整的流程
vii. AfterExtractor
7. 组件的使用和定制
i. 定制Pipeline
ii. 使用Scheduler
iii. 使用Downloader
8. 实例分析
i. 列表+详情的基本页面组合
ii. 抓取前端渲染的页面
iii. 分页抓取
iv. 定期抓取
v. 增量更新
TableofContents



剩余56页未读,继续阅读
资源评论


liuyang77886
- 粉丝: 24
- 资源: 14









最新资源
- 【创新无忧】基于多元宇宙优化算法MVO优化广义神经网络GRNN实现光伏预测附matlab代码.rar
- 【创新无忧】基于白鲨优化算法WSO优化广义神经网络GRNN实现光伏预测附matlab代码.rar
- 【创新无忧】基于多元宇宙优化算法MVO优化广义神经网络GRNN实现数据回归预测附matlab代码.rar
- 【创新无忧】基于多元宇宙优化算法MVO优化极限学习机ELM实现乳腺肿瘤诊断附matlab代码.rar
- 【创新无忧】基于多元宇宙优化算法MVO优化极限学习机KELM实现故障诊断附matlab代码.rar
- 【创新无忧】基于飞蛾扑火优化算法MFO优化广义神经网络GRNN实现电机故障诊断附matlab代码.rar
- 【创新无忧】基于多元宇宙优化算法MVO优化相关向量机RVM实现数据多输入单输出回归预测附matlab代码.rar
- 【创新无忧】基于多元宇宙优化算法MVO优化相关向量机RVM实现北半球光伏数据预测附matlab代码.rar
- 【创新无忧】基于飞蛾扑火优化算法MFO优化广义神经网络GRNN实现光伏预测附matlab代码.rar
- 【创新无忧】基于飞蛾扑火优化算法MFO优化极限学习机ELM实现乳腺肿瘤诊断附matlab代码.rar
- 【创新无忧】基于飞蛾扑火优化算法MFO优化广义神经网络GRNN实现数据回归预测附matlab代码.rar
- 【创新无忧】基于飞蛾扑火优化算法MFO优化相关向量机RVM实现数据多输入单输出回归预测附matlab代码.rar
- 【创新无忧】基于飞蛾扑火优化算法MFO优化相关向量机RVM实现北半球光伏数据预测附matlab代码.rar
- 【创新无忧】基于飞蛾扑火优化算法MFO优化极限学习机KELM实现故障诊断附matlab代码.rar
- 【创新无忧】基于非洲秃鹫优化算法AVOA优化广义神经网络GRNN实现电机故障诊断附matlab代码.rar
- 【创新无忧】基于非洲秃鹫优化算法AVOA优化广义神经网络GRNN实现光伏预测附matlab代码.rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


