Automatic Understanding of Image and Video Advertisements
Zaeem Hussain Mingda Zhang Xiaozhong Zhang Keren Ye
Christopher Thomas Zuha Agha Nathan Ong Adriana Kovashka
Department of Computer Science
University of Pittsburgh
{zaeem, mzhang, xiaozhong, yekeren, chris, zua2, nro5, kovashka}@cs.pitt.edu
Abstract
There is more to images than their objective physical
content: for example, advertisements are created to per-
suade a viewer to take a certain action. We propose the
novel problem of automatic advertisement understanding.
To enable research on this problem, we create two datasets:
an image dataset of 64,832 image ads, and a video dataset
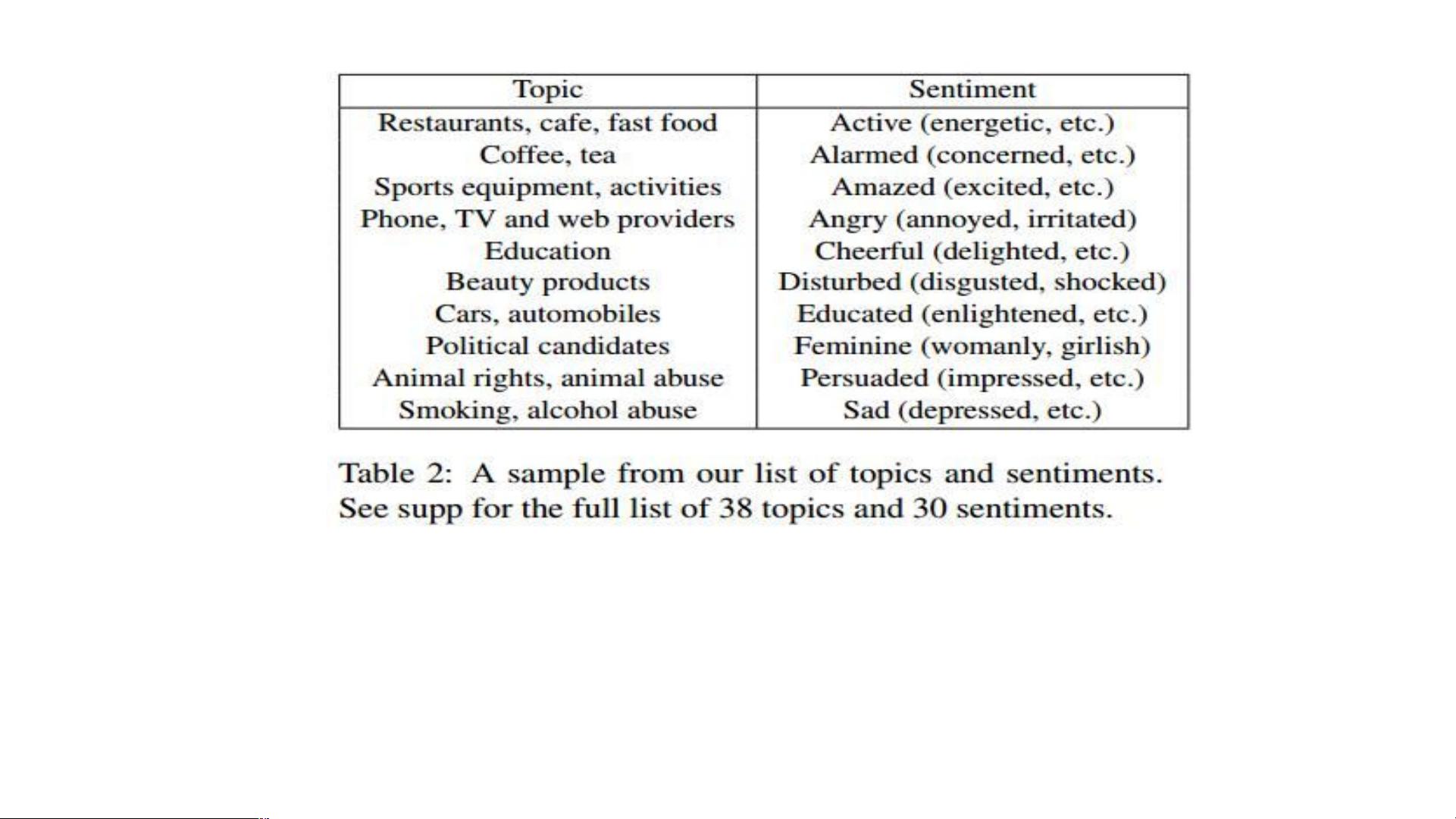
of 3,477 ads. Our data contains rich annotations encom-
passing the topic and sentiment of the ads, questions and
answers describing what actions the viewer is prompted to
take and the reasoning that the ad presents to persuade the
viewer (“What should I do according to this ad, and why
should I do it?”), and symbolic references ads make (e.g. a
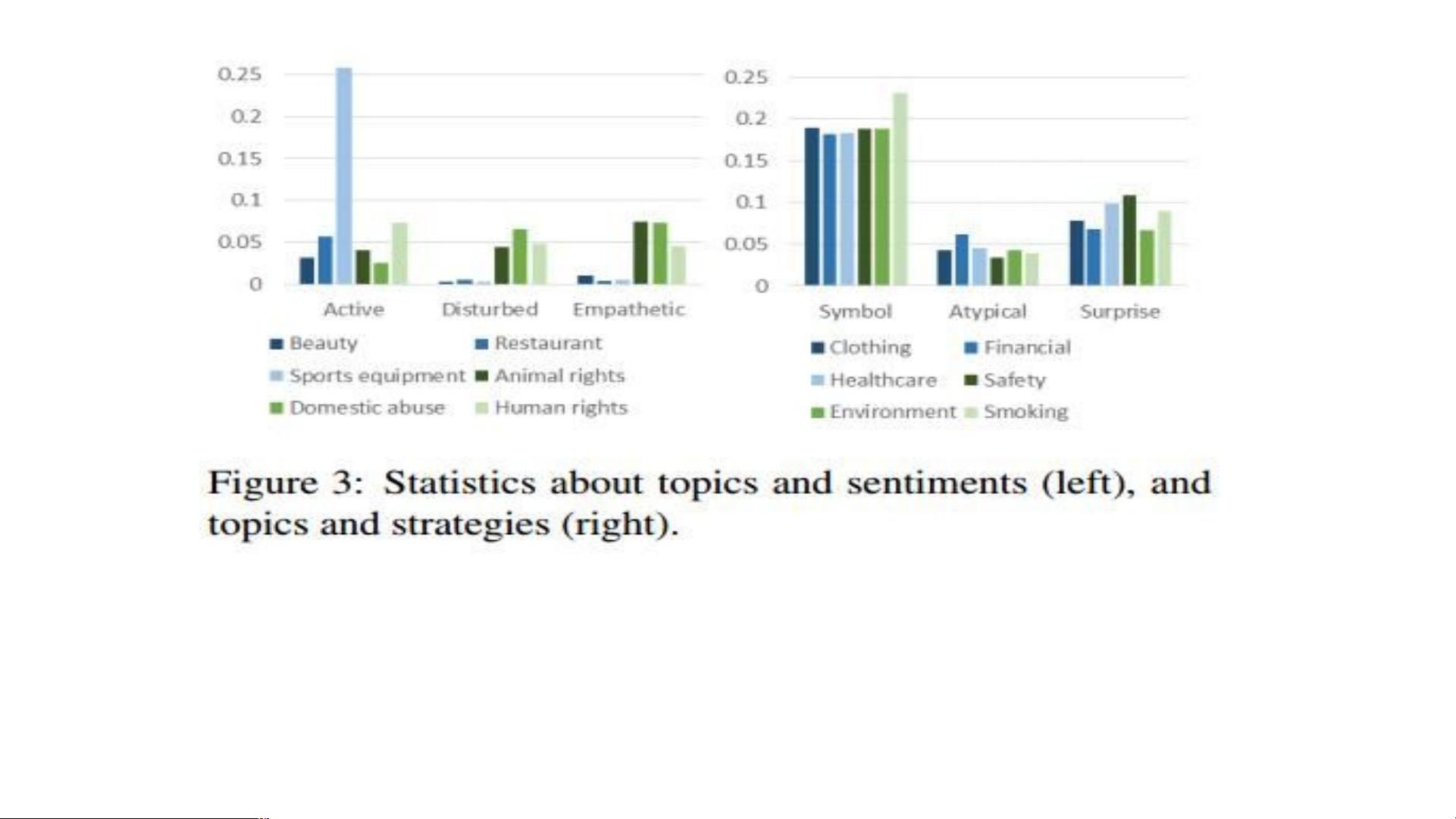
dove symbolizes peace). We also analyze the most common
persuasive strategies ads use, and the capabilities that com-
puter vision systems should have to understand these strate-
gies. We present baseline classification results for several
prediction tasks, including automatically answering ques-
tions about the messages of the ads.
1. Introduction
Image advertisements are quite powerful, and web com-
panies monetize this power. In 2014, one fifth of Google’s
revenue came from their AdSense product, which serves
ads automatically to targeted users [1]. Further, ads are an
integral part of our culture. For example, the two top-left
ads in Fig. 1 have likely been seen by every American, and
have been adapted and reused in countless ways. In terms
of video ads, Volkswagen’s 2011 commercial “The Force”
had received 8 million views before it aired on TV [25].
Ads are persuasive because they convey a certain mes-
sage that appeals to the viewer. Sometimes the message is
simple, and can be inferred from body language, as in the
“We can do it” ad in Fig. 1. Other ads use more complex
messages, such as the inference that because the eggplant
and pencil form the same object, the pencil gives a very
real, natural eggplant color, as in the top-right ad in Fig. 1.
Figure 1: Two iconic American ads, and three that require
robust visual reasoning to decode. Despite the potential ap-
plications of ad-understanding, this problem has not been
tackled in computer vision before.
Decoding the message in the bottom-right ad involves even
more steps, and reading the text (“Don’t buy exotic animal
souvenirs”) might be helpful. The viewer has to infer that
the woman went on vacation from the fact that she is car-
rying a suitcase, and then surmise that she is carrying dead
animals from the blood trailing behind her suitcase. A hu-
man knows this because she associates blood with injury
or death. In the case of the “forest lungs” image at the
bottom-left, lungs symbolize breathing and by extension,
life. However, a human first has to recognize the groups of
trees as lungs, which might be difficult for a computer to
do. These are just a few examples of how ads use different
types of visual rhetoric to convey their message, namely:
common-sense reasoning, symbolism, and recognition of
non-photorealistic objects. Understanding advertisements
automatically requires decoding this rhetoric. This is a
challenging problem that goes beyond listing objects and
their locations [72, 21, 61], or even producing a sentence
about the image [76, 14, 33], because ads are as much about