第二版编译原理课后答案
需积分: 20 68 浏览量
2008-12-07
09:51:16
上传
评论
收藏 1.61MB DOC 举报

第 1 章
1.(1) × (2) √ (3) × (4) × (5) × (6) √
第 2 章
1.(1) √(2) √ (3) × (4) × (5) × (6) ×
2.(1)终结符:0,1,2,3,4,5,6,7,8,9,10
非终结符:N,S,E,D
(2)
①N SE S10 D10 110
②N SE S0 SD0 S10 D10 110
(3)偶数的集合
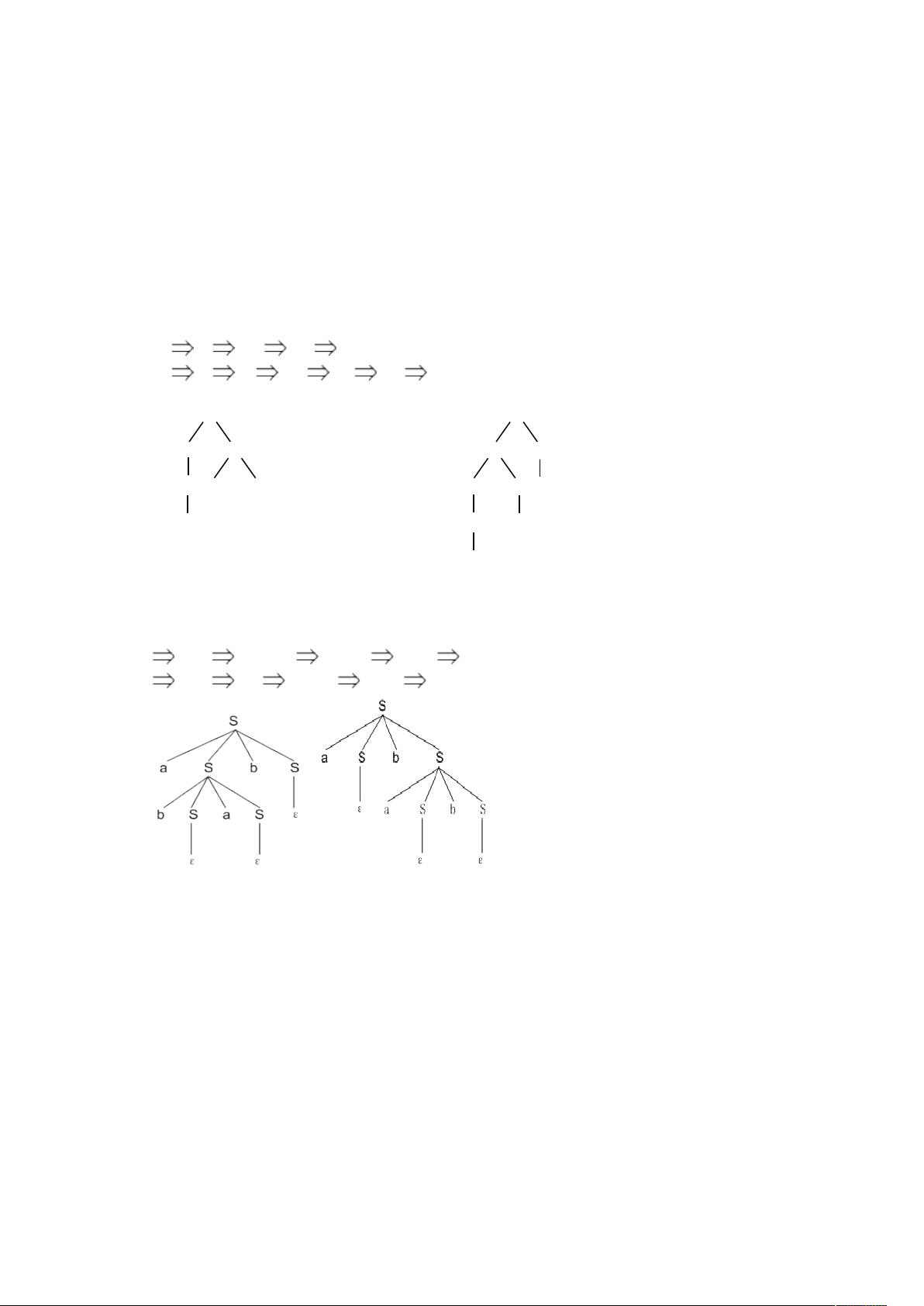
3.(1)句子 abab 的两个相应的最右推导:
S aSbS aSbaSbS aSbaSb aSbab abab
S aSbS aSb abSaSb abSab abab
(2)此文法产生的语言是:所有 a 的个数与 b 的个数相等的由 a 和 b 组成的字符串。
4.能被 5 整除的数从形式上看,是以 0,5 结尾的数字串。题目要求不以 0 开头,注意 0
不是该语言的句子。
所求文法 G[S]:
S→MF|5
F→5|0
N→1|2|3|4|5|6|7|8|9
D→N|0
M→MD|N
其中,S 代表能被 5 整除且不以 0 开头的无符号整数;
F 代表可以出现在个位上的数字;
D 代表所有数字;
110 最右推导的语法树
1
N
S
E
D
1
0
1
N
S
E
S
D
0
1
D
剩余35页未读,继续阅读
资源评论













