

实验一 Hadoop 实验
一、实验目的
1、了解 Hadoop 的 HDFS 和 Map Reduce。
2、掌握 Hadoop 多节点部署过程。
3、掌握 HDFS Shell 命令操作
4、掌握 HDFS 的 Java 访问接口
5、掌握 MapReduce 应用程序实践
二、实验仪器设备/实验环境
、安装有 的 或者 或者其他 系统(必要),多台;
、;;
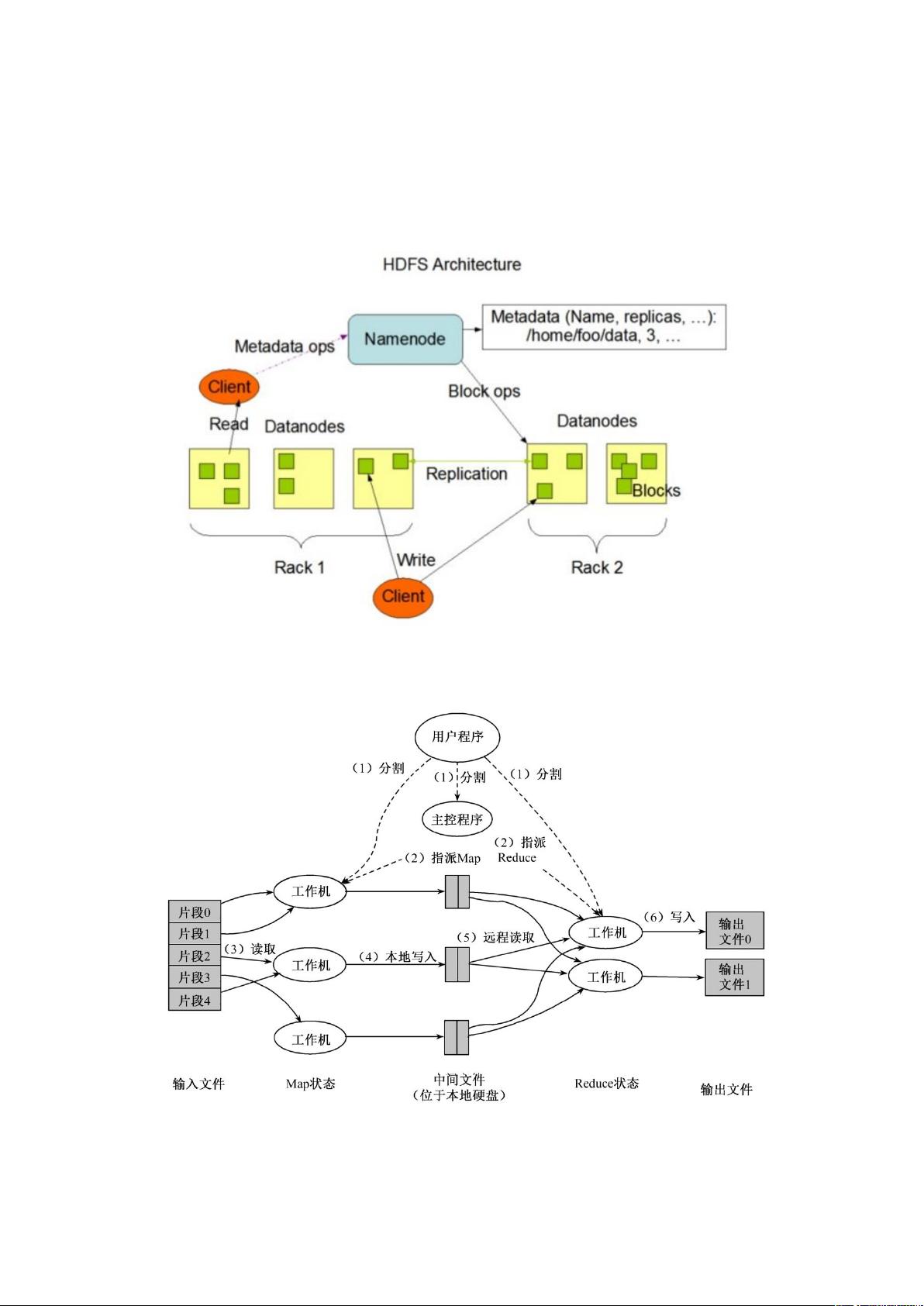
三、实验原理
是一个能够对海量数据进行分布式处理的系统架构,为大数据计算提供了分布
式的集群环境及计算框架; 框架的核心是: 和 !。
分布式文件系统为海量的数据提供了存储,MapReduce 分布式处理框架为海量
的数据提供了计算。
部署
Hadoop 部 署 方 式 分 三 种 , Standalone mode 单 节 点 、 Pseudo-Distributed
mode 伪多节点、Cluster mode 多节点,其中前两种都是在单机部署。

剩余15页未读,继续阅读
资源评论


长脖子大白鹅
- 粉丝: 0
- 资源: 1









最新资源
- Java答题期末考试必须考
- 组播报文转发原理的及图解实例
- 青龙燕铁衣-数据集.zip
- 指针扫描和内存遍历二合一工具
- 基于JavaScript的在线考试系统(编号:65965158)(1).zip
- 五相电机双闭环矢量控制模型-采用邻近四矢量SVPWM-MATLAB-Simulink仿真模型包括: (1)原理说明文档(重要):包括扇区判断、矢量作用时间计算、矢量作用顺序及切时间计算、PWM波的生成
- Linux下的cursor安装包
- springboot-教务管理系统(编号:62528147).zip
- 3dmmods_倾城系列月白_by_白嫖萌新.zip
- SVPWM+死区补偿(基于电流极性)+高频注入法辨识PMSM的dq轴电感(离线辨识)-simulink
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


