

CS229 Lecture notes
Andrew Ng
Part V
Support Vector Machines
This set of notes presents the Support Vector Machine (SVM) learning al-
gorithm. SVMs are among the best (and many believe are indeed the best)
“off-the-shelf” sup ervised learning algorithm. To tell the SVM story, we’ll
need to first talk about margins and the idea of separating data with a large
“gap.” Next, we’ll talk about the optimal margin classifier, which will lead
us into a digression on L agrange duality. We’ll also see kernels, which give
a way t o apply SVMs efficiently in very hig h dimensional (such as infinite-
dimensional) feature spaces, and finally, we’ll close off the story with the
SMO algorithm, which gives an efficient implementation of SVMs.
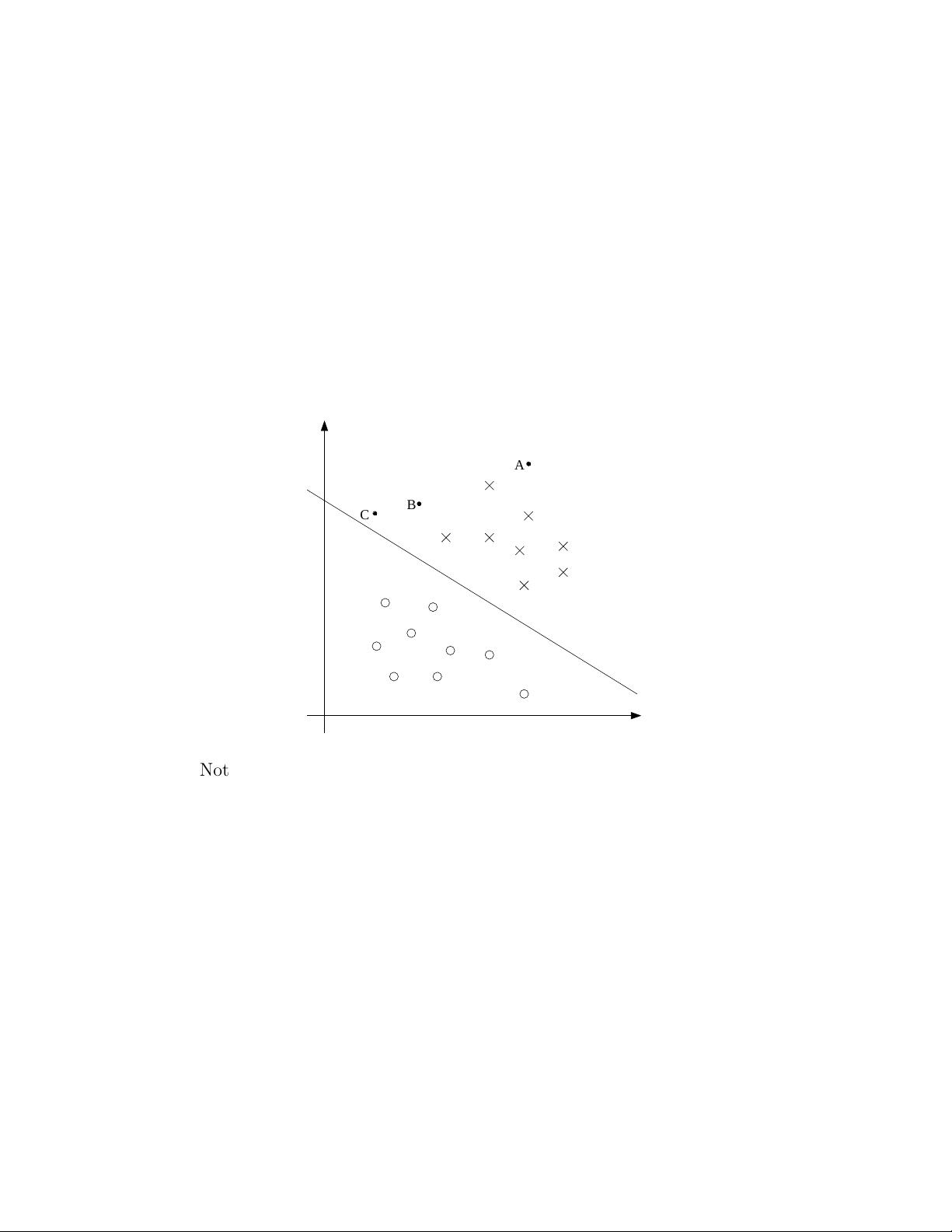
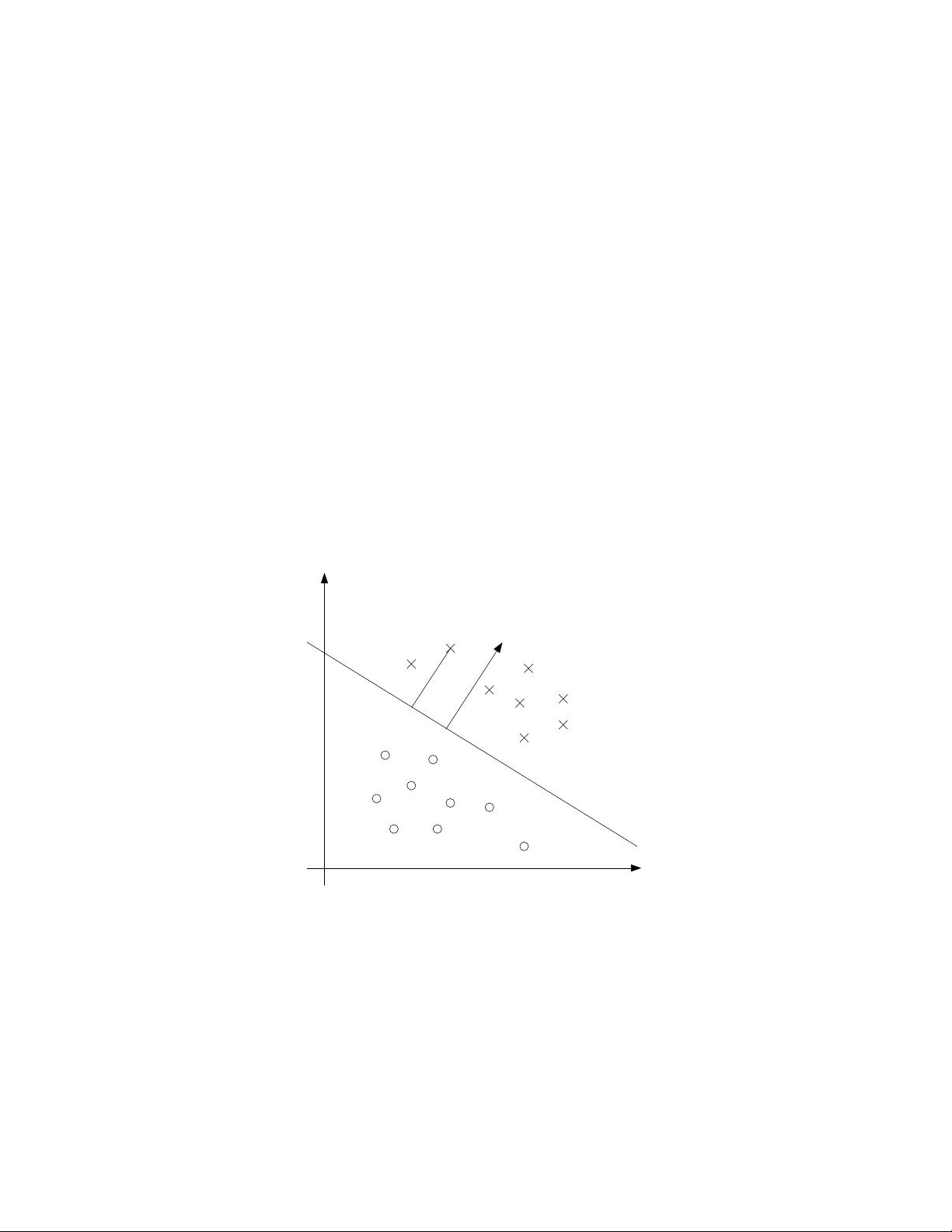
1 Margins: Intuition
We’ll start our story on SVMs by talking about margins. This section will
give the intuitions about margins and about the “ confidence” of our predic-
tions; these ideas will be made formal in Section 3.
Consider logistic regression, where the probability p(y = 1|x; θ) is mod-
eled by h
θ
(x) = g(θ
T
x). We would then predict “1” on an input x if and
only if h
θ
(x) ≥ 0.5, or equivalently, if and only if θ
T
x ≥ 0. Consider a
positive training example (y = 1 ) . The lar ger θ
T
x is, the larger also is
h
θ
(x) = p(y = 1|x; w, b), and thus a lso the higher our degree of “confidence”
that the label is 1. Thus, informally we can think of our prediction as being
a very confident one that y = 1 if θ
T
x ≫ 0. Similarly, we think of logistic
regression as making a very confident prediction of y = 0, if θ
T
x ≪ 0. Given
a training set, again informally it seems that we’d have found a good fit to
the training data if we can find θ so that θ
T
x
(i)
≫ 0 whenever y
(i)
= 1, and
1

剩余24页未读,继续阅读
资源评论


lhr18716032695
- 粉丝: 0
- 资源: 1









最新资源
- Magica Cloth 2 V 2.13布料模拟插件
- 基于SpringBoot的在线考试系统源代码全套技术资料.zip
- 运行在PostgreSQL中的AdventureWorks示例数据库
- 最新女神大秀直播间打赏视频付费观看网站源码 自带直播数据
- 客户购物 (最新趋势) 数据集
- 配电网优化模型matlab 考虑可转移负荷、中断负荷以及储能、分布式能源的33节点系统优化模型,采用改进麻雀搜索算法,以IEEE33节点为例,以风电运维成本、网损成本等为目标,得到系统优化结果,一共有
- MATLAB代码:基于条件风险价值的合作型Stackerlberg博弈微网动态定价与优化调度 关键词:微网优化调度 条件风险价值 合作博弈 纳什谈判 参考文档:A cooperative Stack
- 述职报告PPT模板及样例文章
- MATLAB代码:基于分布式优化的多产消者非合作博弈能量共享 关键词:分布式优化 产消者 非合作博弈 能量共享 仿真平台: matlab 主要内容:为了使光伏用户群内各经济主体能实现有序的电能交易
- 学生抑郁数据集-可以用于分析学生的心理健康趋势
- CRUISE纯电动车双电机四驱仿真模型,基于simulink DLL联合仿真模型,实现前后电机效率最优及稳定性分配 关于模型: 1.策略是用64位软件编译的,如果模型运行不了请将软件切成64位 切
- Android程序开发初级教程WORD文档doc格式最新版本
- cruise混动仿真,P2并联混动仿真模型,Cruise混动仿真模型,可实现并联混动汽车动力性经济性仿真 关于模型 1.模型是基于cruise simulink搭建的base模型,策略模型基于MAT
- HCIP 复习内容实验 ia
- BGP路由协议模拟器,网络路由条目实时监控
- MATLAB代码:含多种需求响应及电动汽车的微网 电厂日前优化调度 关键词:需求响应 空调负荷 电动汽车 微网优化调度 电厂调度 仿真平台:MATLAB+CPLEX 主要内容:代码主要做的是一
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


