在本项目中,我们探讨的是一个基于Python实现的机器学习预测系统。这个系统的核心目标是利用数据驱动的方法来预测未来的趋势或结果,广泛应用于各种领域,如金融、医疗、气象等。Python作为目前数据科学与机器学习领域的主流编程语言,其丰富的库和简洁的语法使得开发这样的系统变得相对容易。
我们要了解机器学习的基本概念。机器学习是人工智能的一个分支,通过让计算机在数据中学习模式,从而实现自我改进和预测。主要分为监督学习、无监督学习和强化学习三种类型。在这个系统中,最可能使用的是监督学习,因为它需要已标注的数据集来训练模型,然后用模型进行预测。
Python中的机器学习库如Scikit-Learn、TensorFlow、Keras和PyTorch等,为开发者提供了强大的工具。其中,Scikit-Learn是最常用的库之一,它包含了大量的预处理方法、模型选择工具以及各种机器学习算法,如线性回归、决策树、随机森林、支持向量机、神经网络等。
项目源码可能包含了以下步骤:
1. 数据预处理:数据清洗是机器学习流程的关键部分,包括去除异常值、填充缺失值、标准化或归一化数据等。Pandas库是数据操作的好帮手,它提供了丰富的数据处理功能。
2. 特征工程:选择或构造对预测目标有影响力的特征,可以显著提高模型性能。Numpy和Scikit-Learn的特征选择模块能帮助进行这一过程。
3. 模型训练:使用Scikit-Learn的fit()函数训练模型,可以选择合适的算法,如线性回归、逻辑回归、随机森林、梯度提升等。
4. 模型评估:通过交叉验证(如k-fold交叉验证)和指标(如准确率、召回率、F1分数、AUC-ROC曲线等)来评估模型的性能。
5. 模型调优:使用网格搜索、随机搜索等方法调整模型参数以优化性能。
6. 模型预测:将新数据输入训练好的模型,获取预测结果。
7. 模型保存与加载:为了方便后续使用,可以将模型保存到文件中,如使用joblib库的dump()函数,之后再通过load()函数加载模型。
在实际应用中,该系统可能还会涉及到数据可视化,例如使用Matplotlib或Seaborn库绘制图表,以更好地理解数据和模型表现。此外,如果项目规模较大,可能还需要使用到大数据处理框架,如Apache Spark,以及版本控制工具如Git,确保代码的管理和协作。
这个基于Python的机器学习预测系统展示了如何利用Python生态系统中的工具和库,结合数据科学理论,构建一个预测模型。对于初学者和专业人士来说,这都是一个有价值的参考资源,有助于深化对机器学习实战的理解。

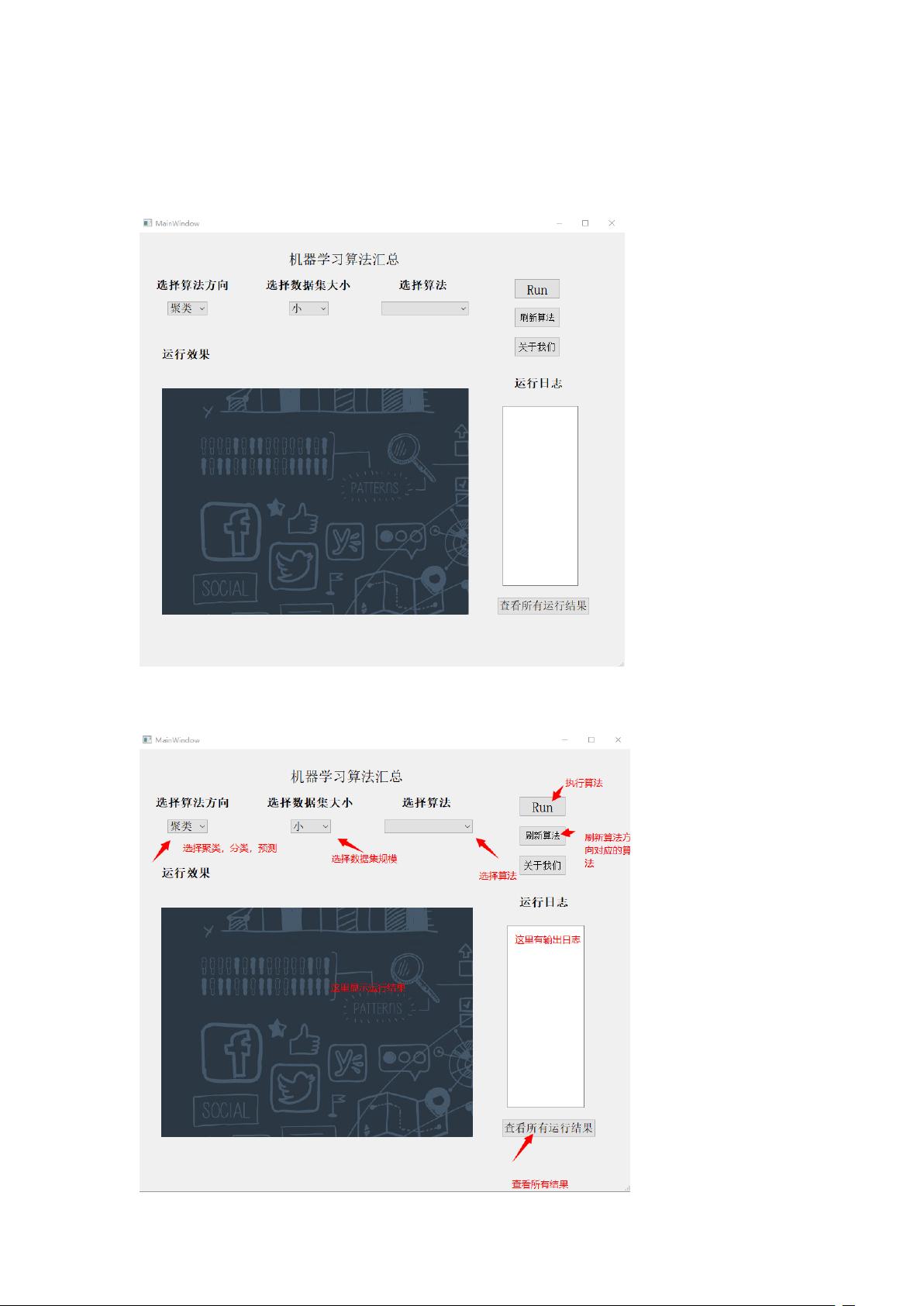
 基于python实现的机器学习预测系统-源码.zip (11个子文件)
基于python实现的机器学习预测系统-源码.zip (11个子文件)  基于python实现的机器学习预测系统-源码
基于python实现的机器学习预测系统-源码  使用说明书.docx 515KB
使用说明书.docx 515KB alldata.py 3KB
alldata.py 3KB data.xlsx 51KB
data.xlsx 51KB












