

Robotics and Autonomous Systems 96 (2017) 184–210
Contents lists available at ScienceDirect
Robotics and Autonomous Systems
journal homepage: www.elsevier.com/locate/robot
Localization of sound sources in robotics: A review
Caleb Rascon *, Ivan Meza
Instituto de Investigaciones en Matematicas Aplicadas y en Sistemas, Universidad Nacional Autonoma de Mexico, Circuito Escolar S/N, Mexico 04510,
Mexico
h i g h l i g h t s
• A highly detailed survey of sound source localization (SSL) used over robotic platforms.
• Classification of SSL techniques and description of the SSL problem.
• Description of the diverse facets of the SSL problem.
• Survey of the evaluation methodologies used to measure SSL performance in robotics.
• Discussion of current SSL challenges and research questions.
a r t i c l e i n f o
Article history:
Received 18 August 2016
Received in revised form 24 June 2017
Accepted 21 July 2017
Available online 5 August 2017
Keywords:
Robot audition
Sound source localization
Direction-of-arrival
Distance estimation
Tracking
a b s t r a c t
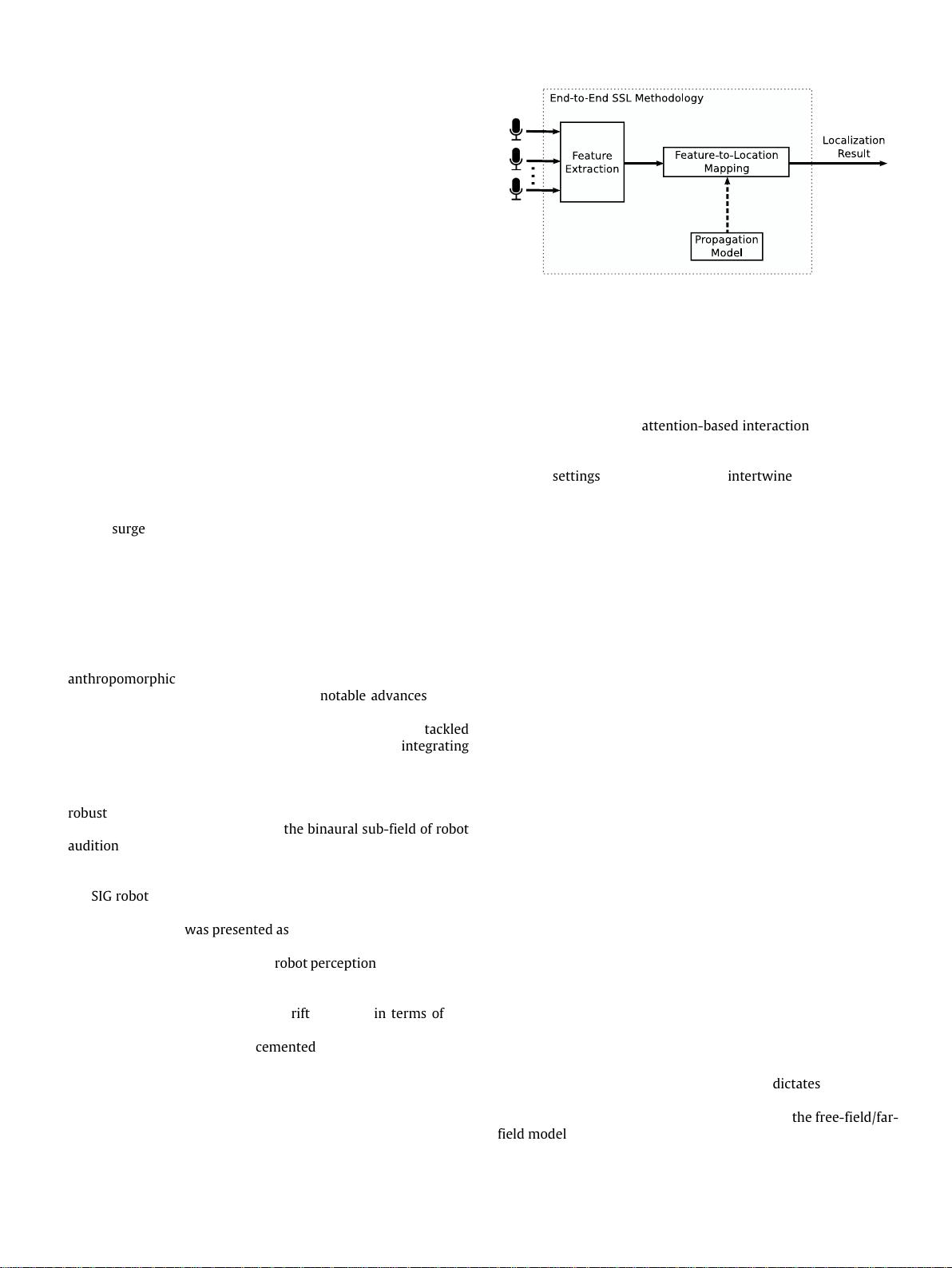
Sound source localization (SSL) in a robotic platform has been essential in the overall scheme of robot
audition. It allows a robot to locate a sound source by sound alone. It has an important impact on
other robot audition modules, such as source separation, and it enriches human–robot interaction by
complementing the robot’s perceptual capabilities. The main objective of this review is to thoroughly
map the current state of the SSL field for the reader and provide a starting point to SSL in robotics. To
this effect, we present: the evolution and historical context of SSL in robotics; an extensive review and
classification of SSL techniques and popular tracking methodologies; different facets of SSL as well as its
state-of-the-art; evaluation methodologies used for SSL; and a set of challenges and research motivations.
© 2017 The Authors. Published by Elsevier B.V. This is an open access article under the CC BY license
(http://creativecommons.org/licenses/by/4.0/).
1. Introduction
The goal of sound source localization (SSL) is to automatically
estimate the position of sound sources. In robotics, this function-
ality is useful in several situations, for instance: to locate a human
speaker in a waiter-type task, in a rescue scenario with no visual
contact, or to map an unknown acoustic environment. Its perfor-
mance is of paramount influence to the rest of a robot audition
system since its estimations are frequently used in subsequent
processing stages such as sound source separation, sound source
classification and automatic speech recognition.
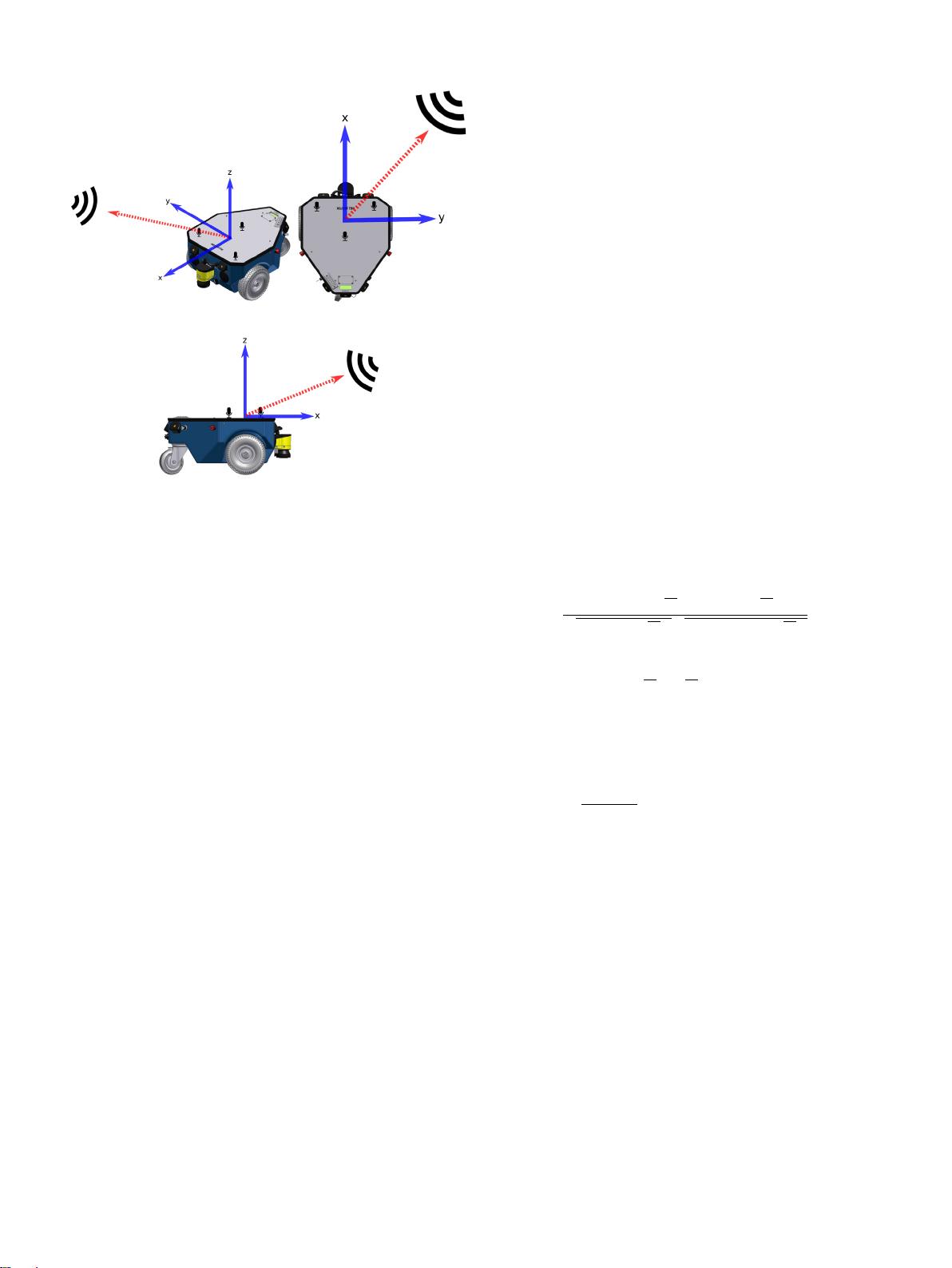
There are two components of a source position that can be
estimated as part of SSL (in polar coordinates):
• Direction-of-arrival estimation (which can be in 1 or 2 di-
mensions)
• Distance estimation.
*
Corresponding author.
E-mail addresses: caleb.rascon@iimas.unam.mx (C. Rascon),
ivanvladimir@turing.iimas.unam.mx (I. Meza).
SSL in real-life scenarios needs to take into account that more
than one sound source might be active in the environment. There-
fore it is also necessary to estimate the position of multiple simul-
taneous sound sources. In addition, both the robot and the sound
source are mobile, so it is important to track its position through
time.
SSL has been substantially pushed forward by the robotics com-
munity by refining traditional techniques such as: single direction-
of-arrival (DOA) estimation, learning-based approaches (such as
neural network and manifold learning), beamforming-based ap-
proaches, subspace methods, source clustering through time and
tracking techniques such as Kalman filters and particle filtering.
While implementing these techniques onto robotics platforms,
several facets relevant to SSL in robots have been made evident
including: number and type of microphones used, number and
mobility of sources, robustness against noise and reverberation,
type of array geometry to be employed, type of robotic platforms
to build upon, etc.
As it is shown in this review, the SSL field in robotics is quite
mature, proof of which are the recent surveys in this topic. For
instance, [1,2] present a survey on binaural robot audition, [3]
offers a general survey of SSL in Chinese, [4] presents some SSL
http://dx.doi.org/10.1016/j.robot.2017.07.011
0921-8890/© 2017 The Authors. Published by Elsevier B.V. This is an open access article under the CC BY license (http://creativecommons.org/licenses/by/4.0/).
红色下划线:重要观点句
绿色高亮;关键词
黄色高亮:不认识的单词

剩余26页未读,继续阅读
资源评论













