
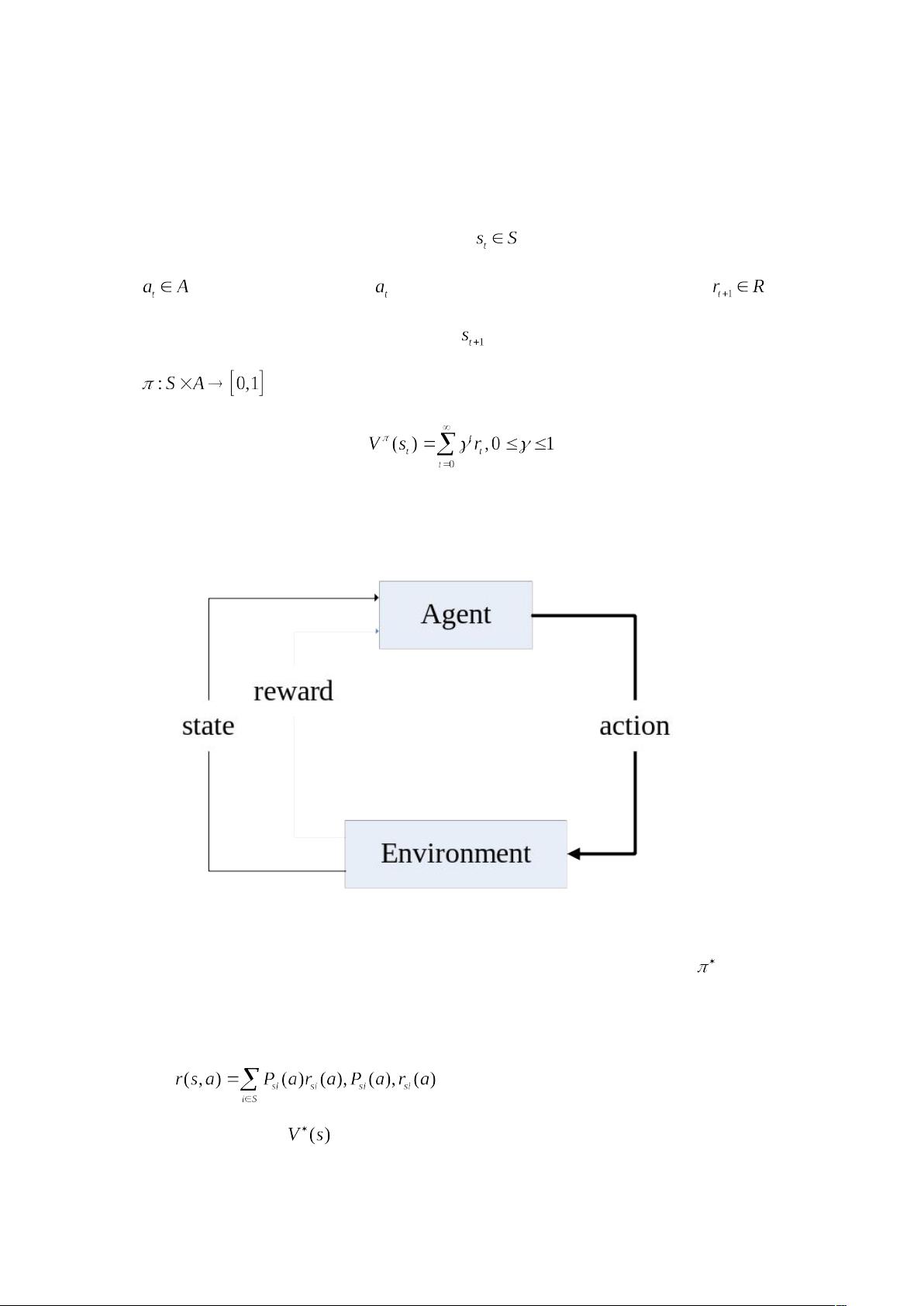
增强学习模型
增强学习的标准模型结构如图所示,决策者与环境的交互发生在一系列的离散时刻 t=0,1,
…,在每个时刻 t,Agent 通过观察环境得到状态 ,S 为环境状态集;据此选择一个动作
,A 为动作集;执行动作 后在下一时刻 t+1,Agent 收到一个报酬值, ,
其 中 R 为 实 数 集 ; 并 达到 一 个 新 的 状 态 。 学 习 的 目 标 就 是 学 习 一 个 最 优 策 略
,使得 Agent 所得报酬总和:
最大(或最小),上式给出的无限折扣模型的目标函数形式。
增强学习在许多方面不同于已被广泛研究的监督学习算法,最重要的差别是不需要导师信
号,并且在选择动作以后,智能体获得了一个即刻的报酬信号和后续的状态,但是没有告
知学习体,对于长期目标而言哪一个动作是最好的动作。
增强学习基本算法
通过 Markov 决策过程建模,增强学习问题一般可以采用迭代结束来更新函数的估计值来
获得最优策略。根据 Bellman 动态规划的基本理论,可以直接给出在最优策略 下系统在
状态 s 的值函数:
( )
( ) max{ ( , ) ( ) ( )}
si
a A s
i S
V s r s a P a V i
(1)
其中 分别表示执行动作 a,从状态 s 转移到 i 的概率和
获得的报酬信号。而 可以通过 Bellman 迭代来逼近



剩余30页未读,继续阅读
资源评论


laojiudian
- 粉丝: 0
- 资源: 1









最新资源
- MSCOMM控件资源WIN-ALL
- default.custom.yaml # RIme 输入法 的简体设置文件
- MT7621路由器SDK和HDK文件,MT7621无线路由器,MediaTek-ApSoC-SDK-4320-20150414.tar.bz2 AP-MT7621 MT7612E MT7603E-V4
- 广播星历位置计算,精密星历提供的坐标进行求差
- 默纳克刷机,默纳克刷协议,默纳克显示板 外呼板协议更改 烧录 默纳克各种软件各种刷机,含主板、轿顶板、外呼板刷机软件原程序、操作器刷机软件及协议一应俱全
- 连续性和可导性入门学习(微积分前置知识)
- Unistorm最新unity天气资源包
- 基于yolov5实现的AI自动瞄准的python源码+文档说明(亲测可用)
- 计算机基础知识点与前沿技术全面解析
- 课程设计javaweb的企业人事管理系统源码+数据库+实验报告(高分项目)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


