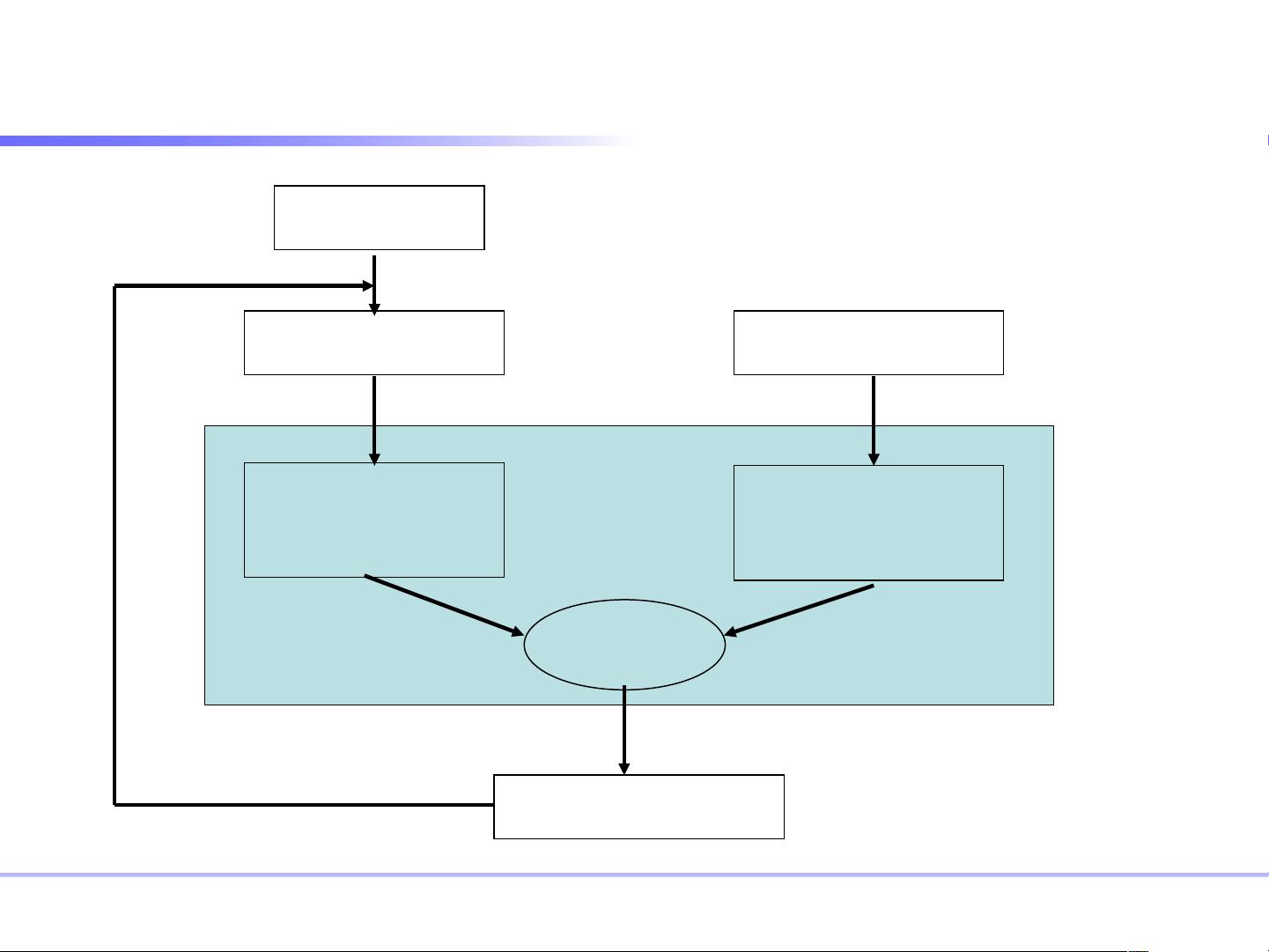
信息检索是信息技术领域的重要组成部分,它涉及到如何有效地从大量文档集合中找到与用户查询相关的信息。本主题主要探讨了信息检索的基本原理和技术,以及数据库全文检索的实现方法。 信息检索模型是实现信息检索的核心,包括布尔模型、向量模型、概率模型等。布尔模型基于逻辑运算符(如AND, OR, NOT)来组合查询,判断文档是否满足查询条件。向量模型将文档和查询表示为词项的向量,通过计算两个向量的相似度来评估文档的相关性。概率模型如BM25则引入了项频率和逆文档频率等因素,以概率方式衡量相关性。 在信息检索过程中,评价指标是衡量检索效果的关键。查全率(Recall)指的是检索出的相关文档数占文档集合中所有相关文档的比例,反映系统能否找到所有相关文档。查准率(Precision)则是检索出的相关文档数占所有检索出的文档总数的比例,体现了检索结果的纯净度。 文档表示通常涉及分词、去除停用词和词干提取等预处理步骤。分词是将文本分割成有意义的词语,停用词是常见的无意义词汇,如“的”、“是”等,不参与索引。词干提取则通过减少词缀,使不同形式的词归一化,如“compute”,“computing”,“computation”都还原为“comput”。 倒排索引是全文检索中的关键数据结构。它为每个词项创建一个倒排表,记录该词项在哪些文档中出现,以及在文档内的位置。倒排索引能快速定位到包含特定词项的文档,从而提高检索速度。 在文档查询中,常用的相似度计算方法有向量点积和余弦相似度。向量点积直接计算两个向量的内积,而余弦相似度考虑了向量的方向,能更好地评估向量之间的角度差异。 数据库全文检索技术是针对长文本数据的高效查询手段。例如,SQL Server 2000引入了全文索引,它不同于普通索引,存储在文件系统但由数据库管理系统控制。全文索引在数据更新时自动更新,提升了对长文本字段的查询性能。 总结来说,信息检索涉及到从大量数据中提取相关信息,这需要有效的检索模型、预处理技术和数据结构,如倒排索引。数据库全文检索技术则专门针对文本数据提供高效的查询解决方案,以应对传统索引方法在处理长文本时的局限性。
剩余19页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~