
通用论坛正文提取
摘要
网络时代信息化大潮正在席卷全球,信息的重要性凸显,各类型网站隐藏着
海量的信息。但由于每个网站、每个程序员的代码习惯不同,可能导致信息提取
的难度系数增大。因此,本文以 BBS 类型的网站为案例,探索提取 BBS 类型网络
信息的通用性算法并通过借助网络爬虫技术,运用 eclispe+pydev 软件和 excel 软
件探索适用于 BBS 类型网站的通用性算法。
本文主要探索以下 5 个方面:
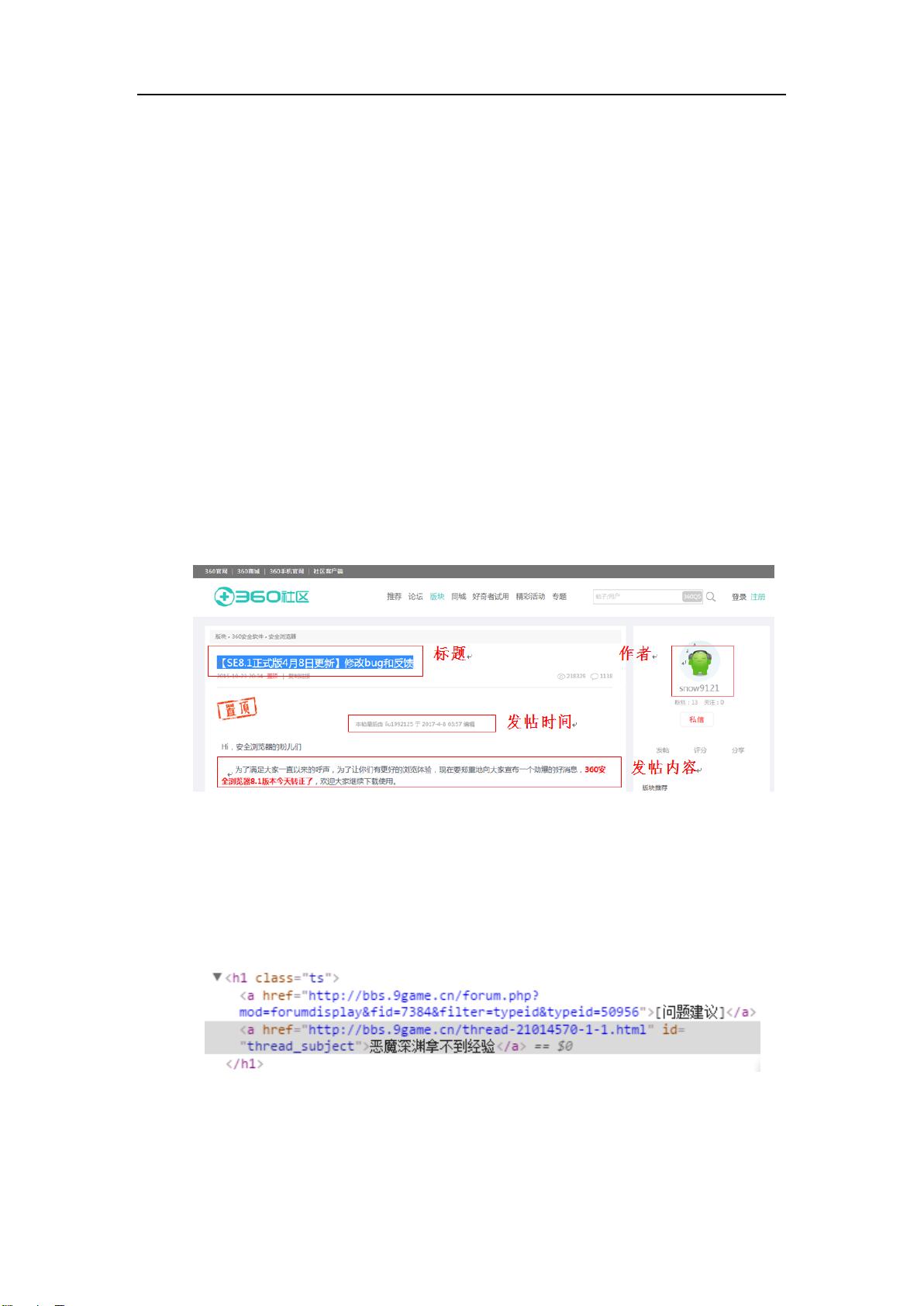
1. 通过搜寻大量 BBS 类型的网页,研究网页结构、标签分布、目标信息的标签
位置,通过采取“正难则反”的方式,剔除<img>、<script>等无关标签;
2. 抽取剔除无关标签之后的所有文本;
3. 对标题、时间、作者、正文等目标信息进行去噪处理;
4. 各种目标文本的获取方式,如表 1 所示:
表 1 目标文本的获取方式
提取目标
提取方式
Title(标题)
设置权重值 W,设置连续变量,计算长度差
Time(时间)
正则表达式
Content(文本)和 author(作者)
通过主办方给的所有链接测试文本密度
及运用统计学探索性分析的方法推导规律
5. 测试验证,使用 260 个网页进行测试并搜集结果数据,分析其通用性。
关键字:
通用算法 数据挖掘 EDA BBS eclipse+pydev excel

剩余16页未读,继续阅读
资源评论













