

深入解析数据压缩算法
所谓数据压缩,是指在不丢失信息的前提下,缩减数据量以减少存储
空间,提高传输、存储和处理效率的一种技术方法。或者是按照一定
的算法对数据进行重新组织,减少数据的冗余和存储的空间。
能实现数据压缩的本质原因就是数据的冗余性。
本系列将分为上下两个部分,介绍四种数据压缩算法,分别为 Human
压缩算法、RLE 压缩算法、LZW 压缩算法、Rice 压缩算法。
其中本文将详解 Human 压缩算法和 RLE 压缩算法
第一节 Huffman 压缩算法
huffman 压缩算法可以说是无损压缩中最优秀的算法。它使用预先二
进制描述来替换每个符号,长度由特殊符号出现的频率决定。其中出
现次数比较多的符号需要很少的位来表示,而出现次数较少的符号则
需要较多的位来表示。
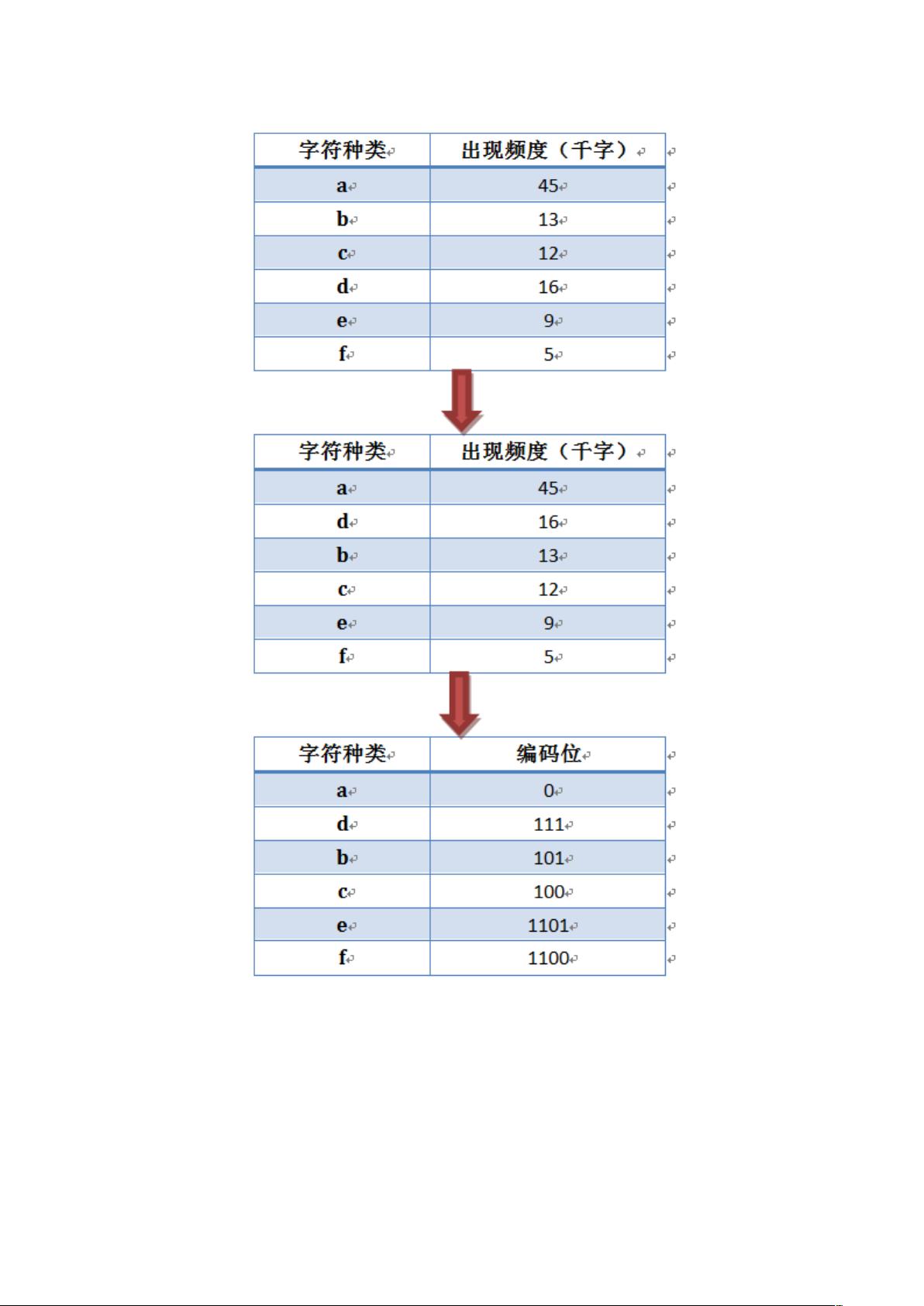
huffman 压缩算法的原理:利用数据出现的次数构造 Human 二叉树,
并且出现次数较多的数据在树的上层,出现次数较少的数据在树的下
层。于是,我们就可以从根节点到每个数据的路径来进行编码并实现
压缩。
老办法,还是举个例子。
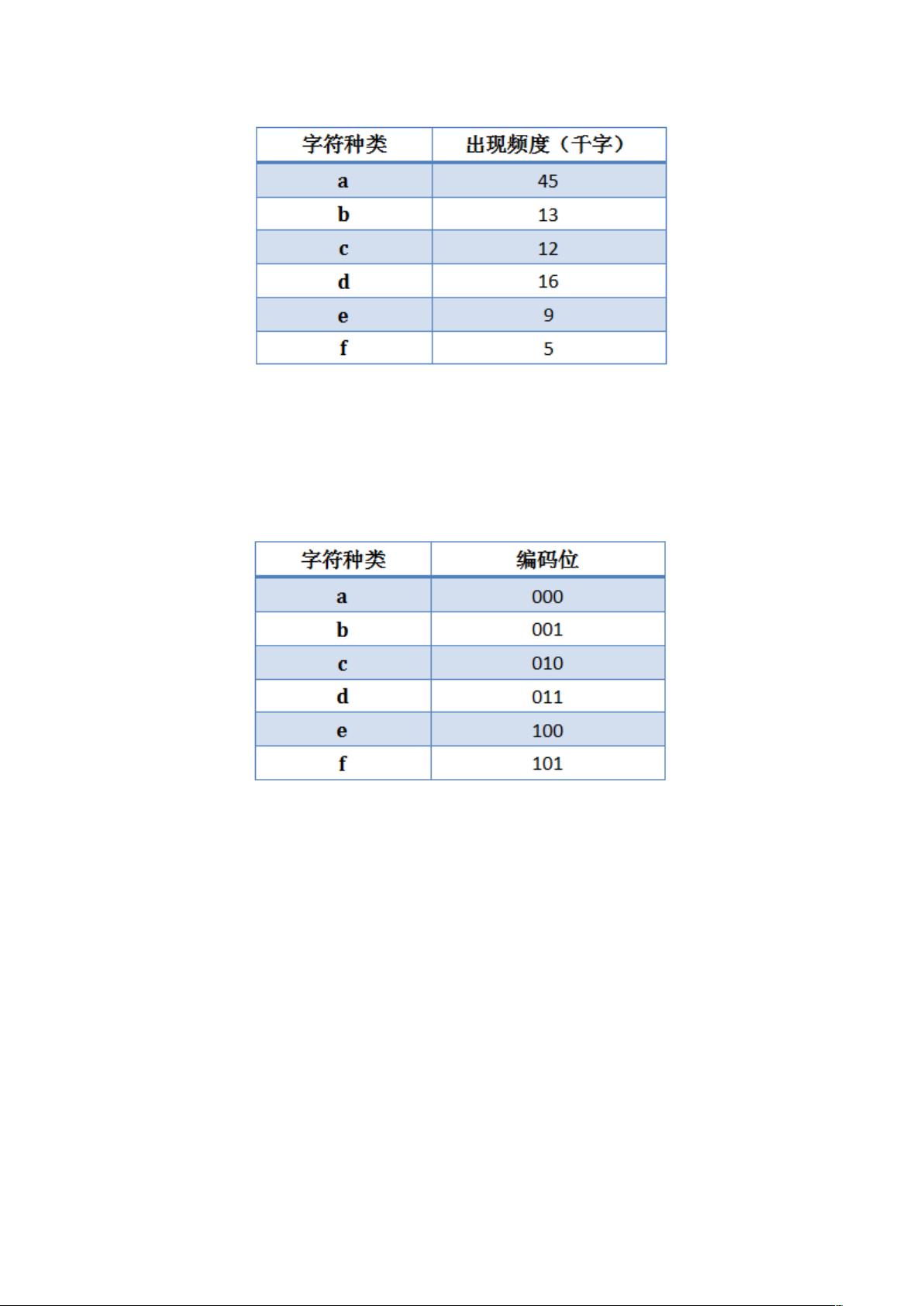
假设有一个包含 100000 个字符的数据文件要压缩存储。各字符在该文
件中的出现频度如下所示:
剩余13页未读,继续阅读
资源评论

 思念白云蓝天2015-07-05勉强能看懂,里面好像有点小错误
思念白云蓝天2015-07-05勉强能看懂,里面好像有点小错误 tuzilaopo2014-11-07恩,理解起来有点吃力,本人水平有限,不过还是感谢
tuzilaopo2014-11-07恩,理解起来有点吃力,本人水平有限,不过还是感谢- ly709795204ly2015-05-02慢慢看,算法不是新的。。
- hzjbsjz2015-07-15恩,理解起来有点吃力,本人水平有限,不过还是感谢

kkewwei
- 粉丝: 1
- 资源: 62









最新资源
- 微电源下垂控制matlab仿真建模 采用解耦的电压外环?电流内环控制, 输出电压电流波形质量良好,
- 锂电池充电器用不对称半桥谐振反激变器电路仿真模型 结构简单 效率高 输出电压闭环闭环 原边管子可实现ZVS,副边二极管可实现ZCS 模型内包含开环控制,输出电压闭环控制两种控制方式 matlab
- 异步电机双矢量模型预测转矩控制(MPTC) 针对单矢量MPTC转矩纹波大等缺点,从而引入零矢量组合发波,有效改善转矩控制性能 (1)、双矢量发波(有效电压矢量+零矢量); (2)、仿真系统完善,波形
- 三电平T型逆变器仿真模型 90和60度坐标系都可以 MATLAB Simulink SVPWM控制,无中点电位不平衡控制 具体输出波形见下面图片;与有中点电位平衡的波形基本一样,只是电容电压的区别
- SS2可编程逻辑控制器方案,原创,方案,有源码在手 方案采用ARM芯片M4F内核,主频200M,功能比原装强劲,支持4轴同时可以控制4台伺服电机 同时发脉冲100K 支持U盘更新PLC程序,方便
- 增程式混合动力汽车Cruise整车仿真模型 串联混合动力仿真 1.基于Cruise平台搭建整车部件等动力学模型,基于MATLAB Simulink平台完成整车控制策略的建模,策略模型具备再生制动,最
- 电源开关电源200W 12V 24V,电源架构PFC+LLC+同步整流,高效率高功率因数 转让PCB电路图参数变压器电感参数Bom清单 供学习参考DIY做产品参考设计都非常奈斯 需要的可以直接联
- 该模型采用模型预测控制进行PMSM速度控制,由于预测控制理论在近些年来得到了快速发展并且在工业控制中应用越来越广泛算法应用到永磁同步电机的控制中,充分利用其滚动优化和反馈校正的特点,使控制器表现出较好
- MATLAB机器人仿真 机械臂视觉控制运动仿真,根据设定的跟踪目标,通过读取摄像头跟踪运动目标,利用逆解实现机械臂跟随目标运动的路径规划仿真,实现视觉控制机械臂运动仿真
- 风电并网,matlab,四机两区系统并入风电,风电调频控制
- 高频方波电压注入的的PMSM转子初始位置检测 1.方波电压和正负脉冲电压相结合实现永磁同步电机转子初始位置检测; 2.提供算法对应的参考文献和仿真模型,支持技术解答 仿真模型纯手工搭建,不是从网络上
- 基于空间矢量控制的永磁同步电机状态反馈控制转速系统设计及仿真,仿真平台基于MATLAB Simulink搭建 联系默认发仿真系统文件 另外包含设计文档,高清仿真结果示意图,出图程序 设计文档包括
- Comsol黑磷各向异性吸收
- omron欧姆龙CJ CP程序 欧姆龙CJ2M-CPU35,搭配普洛菲斯触摸屏,主机搭载NC413定位控制模块带将近30轴,NG剔除功能 全自动CE锂电池包装成型机,轴控制,涵盖人机配
- 基于FPGA的图像边缘检测系统设计 边缘检测算子有Sobel和Prewitt算子,本次设计是用按键控制的,可以在Sobel和Prewitt算子间进行切 网上基本没有这种结合的,基本全是Sobel算子
- matlab频谱功率谱画图程序(完整版) 输入:% data为待分析信号,需要是一维实数也能处理数据信息波(例如:下图7-9绘制的导入数据的信号) (感觉信号的横坐标单位可能不太正确,需自行调整一下)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


